




 ES的查询是近实时的,数据写入后先存储在内存缓冲区和translog,等待refresh_interval(默认1s)后刷新到FileSystemCache。此时,数据生成segment文件,成为可查询状态。refresh后,内存缓冲区清空,translog内容定时持久化到磁盘。刷新间隔可调整,以便在大量写入和实时查询需求之间找到平衡。
ES的查询是近实时的,数据写入后先存储在内存缓冲区和translog,等待refresh_interval(默认1s)后刷新到FileSystemCache。此时,数据生成segment文件,成为可查询状态。refresh后,内存缓冲区清空,translog内容定时持久化到磁盘。刷新间隔可调整,以便在大量写入和实时查询需求之间找到平衡。
ES中的查询是近实时的,也就是说当数据添加到索引后并不能马上被查询到,等到索引刷新后才会被查询到,索引刷新相关字段为refresh_interval,默认为1s刷新一次。
为何说ES的查询是近实时的呢?首先先了解下ES写入数据的过程:
- ES写入数据是先把数据写进Luence的**"memory buffer"缓冲区**(同时也会把数据写一份到translog buffer,进行定时同步到磁盘的持久性操作),Elasticsearch 是基于 Lucene 实现的。ES 基于底层这些包,然后进行了扩展,提供了更多的更丰富的查询语句,并且通过 RESTful API 可以更方便地与底层交互。ES中的倒排索引、打分机制、全文检索原理、分词原理等技术都是Lucene提供的。
- 写进Luence的"memory buffer"缓冲区的数据还不能被查询,Luence会每1s调用refresh方法将缓冲区的数据刷新到FileSystemCache中,刷新时间可以修改,也就是可以修改refresh_interval参数。FileSystemCache是缓存层,会将数据生成segment文件,一旦生成segment文件,就能通过索引查询到了。segment文件就是倒排索引文件
- refresh完,memory buffer就清空了。每隔5s中,开始是保存到translog buffer到数据就会被flush到磁盘中
- 定期/定量从FileSystemCache中,结合translog内容flush index到磁盘中。做增量flush
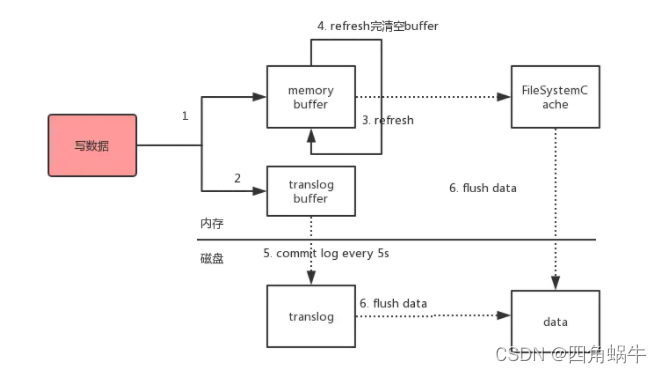
总结:由上可知,es的查询是近实时的,写入到能查询的时间取决于refresh
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









