




参考:面向大模型的存储加速方案设计和实践-百度开发者中心 (baidu.com)
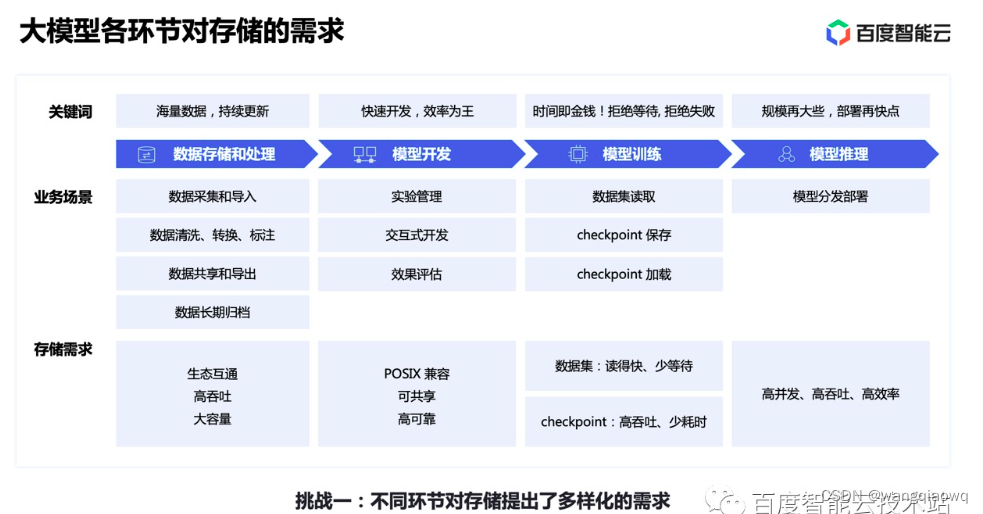
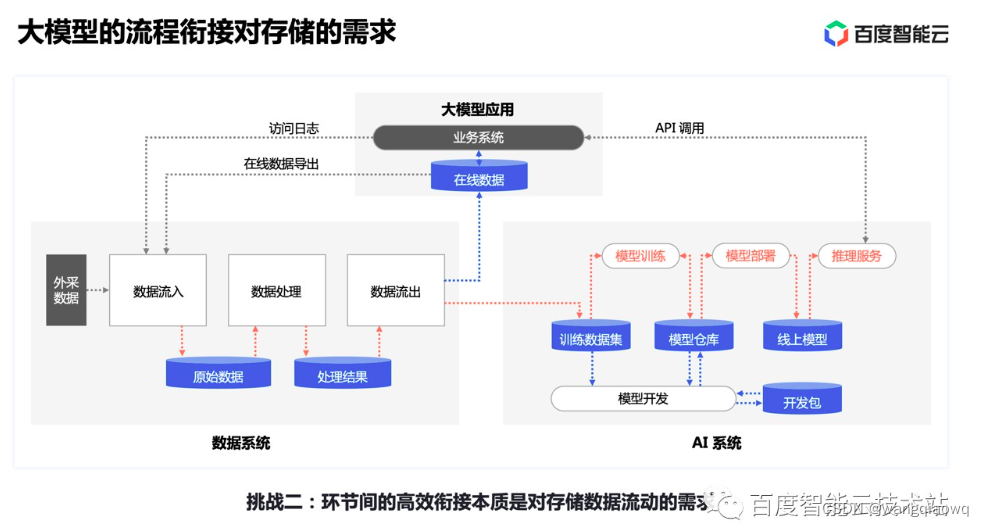
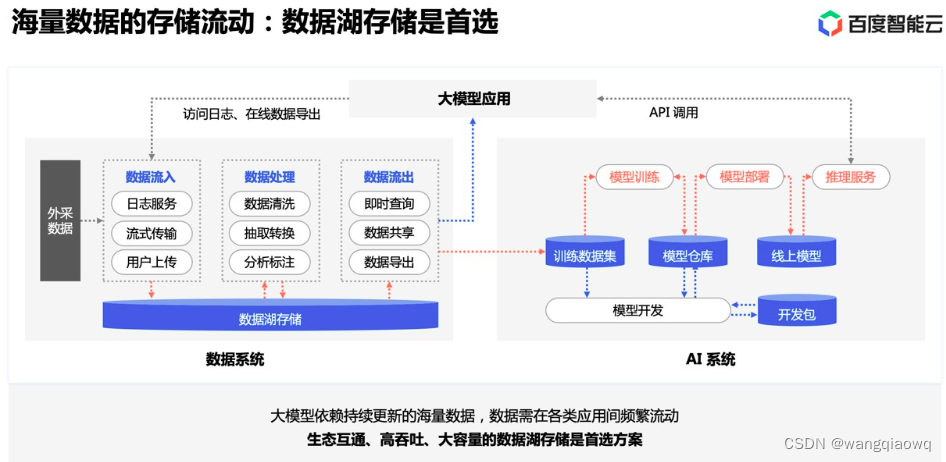
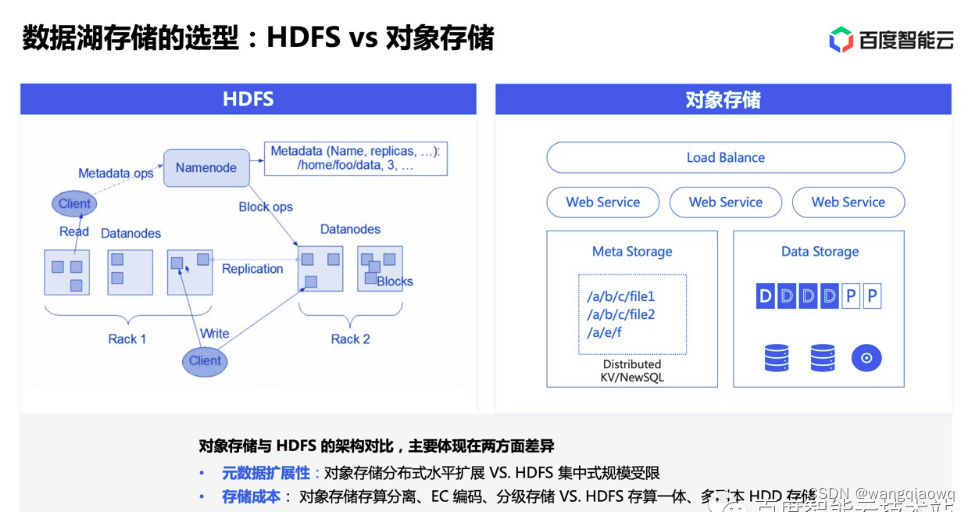

对于一个典型的训练来说,可能迭代多轮 epoch。在每个 epoch 内,首先需要对数据集进行随机打散,然后将打散后的数据划分为若干 batch,每读取一个 batch 的数据,进行一次训练迭代。同时会周期性保存 checkpoint 用于故障快速恢复。
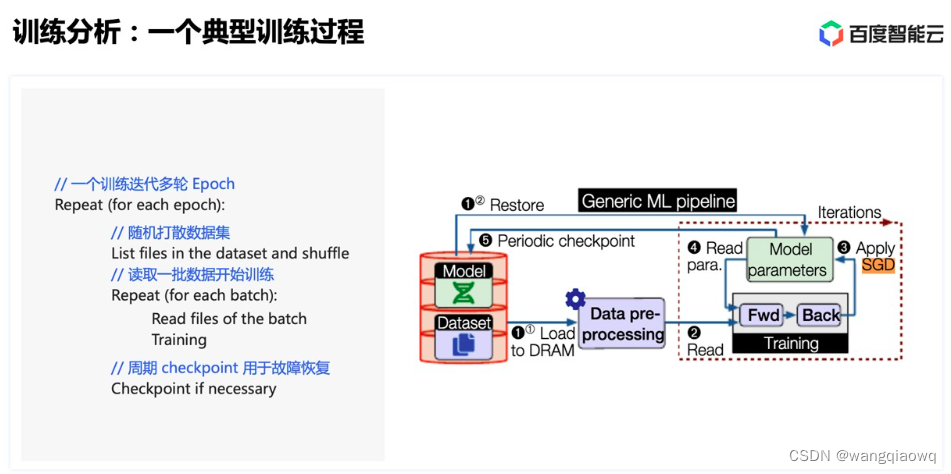
每一轮 epoch 的耗时都是由数据 shuffle、数据读取等待、checkpoint 和真正的训练时间相加得到。因此为了尽量提高训练效率,减少 GPU 的空闲,我们的主要优化就集中在三个思路:
优化 shuffle 过程,尽量将耗时控制在较小比例;
优化读取过程,尽量让每一轮读取数据的耗时小于
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 577
577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









