




Pandas 是Python 中最强大的数据分析工具之一,在数据科学、金融分析、机器学习等领域被广泛应用。
一、高效读取大型 CSV 文件
处理大型数据集时,内存消耗是一个常见问题。pandas 提供了分块读取的方法,可以有效降低内存压力:
import pandas as pd
import numpy as np
# 常规读取方式
df = pd.read_csv("large_file.csv") # 可能导致内存溢出
# 高效读取方式,分块读取
chunk_size = 10000
data_chunks = []
for chunk in pd.read_csv("large_file.csv", chunksize=chunk_size):
# 对每个数据块进行处理
processed_chunk = chunk.query('value' > 0) # 示例,筛选正值
data_chunks.append(processed_chunk)
# 合并处理后的数据块
result_df = pd.concat(data_chunks, ignore_index=True)
# 或者直接迭代处理而不保存所有数据
total_sum = 0
for chunk in pd.read.csv("large_file.csv", chunksize=chunk_size):
total_sum += chunk['value'].sum()
print(f"数据总和:{total_sum}" )
这种方式可以处理远大于内存容量的文件,非常适合大数据场景
二、使用查询字符串进行数据筛选
pandas 的 query 方法提供了一种简洁的方式来筛选数据,比传统的布尔索引更加直观:
# 创建示例数据
df = pd.DataFrame({
"A": np.random.rand(10000),
"B": np.random.rand(10000),
"C": np.random.choice(["X", "Y", "Z"], 10000)
})
# 传统方式
filtered_df1 = df[(df["A"] > 0.5) & (df["B"] < 0.5) & (df["C"] == "X")]
# 使用 query (通常更快且更可读)
filtered_df2 = df.query('A > 0.5 and B < 0.5 and C == "X"')
# 使用变量
threshold_a = 0.5
threshold_b = 0.5
filtered_df3 = df.query('A > @threshold_a and B < @threshold_b and C == "X"')
query 方法不仅使代码更加简洁,在处理大型数据集时通常也会有更好的性能。
三、多级索引高效操作
在处理复杂数据时,多级索引(MultiIndex)是一个强大的功能
# 创建多级索引的 DataFrame
arrays = [
["北京", "上海", "广州", "北京", "上海", "广州"],
["2021", "2021", "2021", "2022", "2022", "2022"]
]
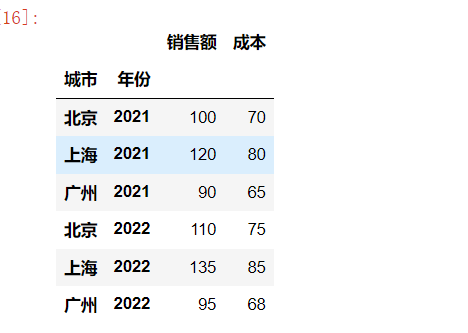
index = pd.MultiIndex.from_arrays(arrays, names=("城市", "年份"))
df = pd.DataFrame({
"销售额": [100, 120, 90, 110, 135, 95],
"成本": [70, 80, 65, 75, 85, 68]
}, index=index)
df
# 基于索引级别访问数据
beijing_data = df.loc["北京"]
beijing_data

year_2021_data = df.xs("2021", level="年份")
year_2021_data
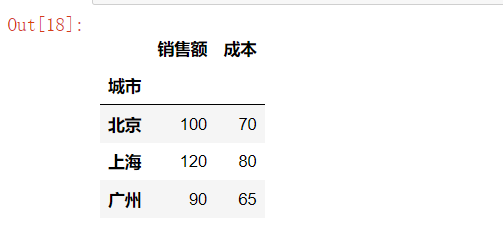
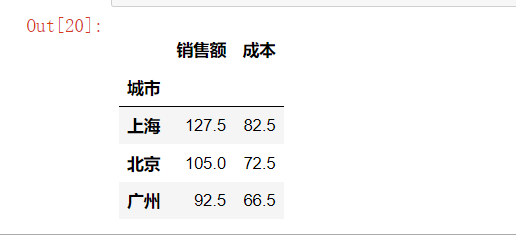
# 按索引级别分组计算
city_avg = df.groupby(level="城市").mean()
city_avg
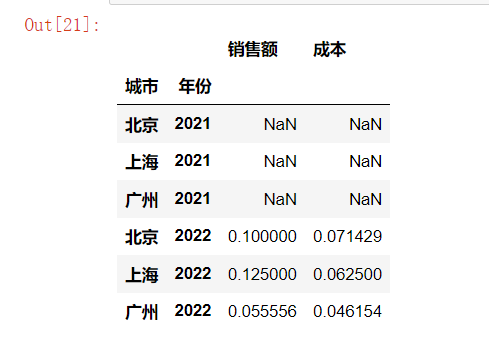
growth = df.groupby(level="城市").pct_change()
growth
# 在多级索引键转化
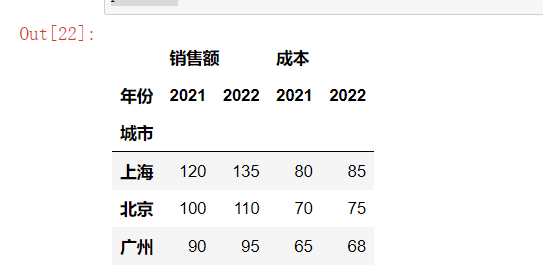
pivoted = df.unstack(level="年份") # 将年份从索引变为列
pivoted
stacked = pivoted.stack() # 将列转回索引
stacked
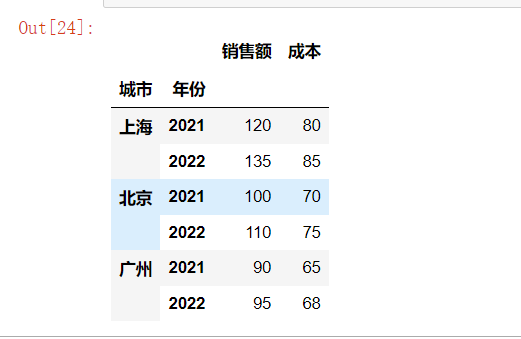
多级索引可以更优雅地组织复杂的数据结构,减少数据冗余。
四、列数据类型转换与内存优化
优化 DataFrame 的内存使用是处理大数据的重要技巧
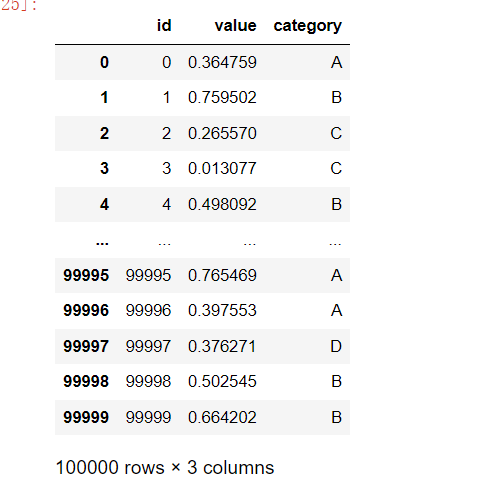
# 创建数据示例
df = pd.DataFrame({
"id": range(100000),
"value": np.random.rand(100000),
"category": np.random.choice(["A", "B", "C", "D"], 100000)
})
df
# 查看初始内存使用
print(f"初始内存使用: {df.memory_usage().sum() / 1024 ** 2:.2f} MB")
# 初始内存使用: 2.29 MB
# 优化整数列
df["id"] = pd.to_numeric(df["id"], downcast="integer")
df
# 优化浮点列
df["value"] = pd.to_numeric(df["value"], downcast="float")
df
# 将分类数据转化为 category 类型
df["category"] = df["category"].astype("category")
df
# 查看优化后使用的内存
print(f"优化后内存使用情况:{df.memory_usage().sum() / 1024 ** 2:.2f} MB")
# 优化后内存使用情况:0.86 MB
通过合理设置数据结构,可以显著减少 DataFrame 的内存占用,有事能节省 70% 以上的内存。
五、使用 apply 和 map 进行高效数据转化
pandas 提供了多种方法来转化数据,选择合适的方法能够显著提升性能:
# 创建示例数据
df = pd.DataFrame({
"A": range(100000),
"B": range(100000)
})
df
# 不同数据转化方式
# 1. 使用向量化操作(最快)
df["C"] = df["A"] + df["B"]
df
# 2.使用 apply(对于无法向量化的复杂操作)
def complex_operation(row):
# 模拟复杂计算
return np.sqrt(row["A"] ** 2 + row["B"] ** 2)
df["D"] = df.apply(complex_operation, axis=1)
df
# 3.使用 map(适用于Series 上的元素级别转换)
mapping = {i: i**2 for i in range(10)} # 小型映射字典
df["E"] = df["A"].map(lambda x: x%10).map(mapping)
df
# 4.使用列表推导式(有时比 apply 更快)
df["F"] = [a * b for a, b in zip(df["A"], df["B"])]
df
# 5.使用 Numpy 方法(通常最高效)
df["G"] = np.sqrt(np.square(df["A"]) + np.square(df["B"]))
df
在实际应用中,应尽量使用向量化操作或者 Numpy 函数,他们通常比 apply 和 map快 10 ~ 100 倍。
六、时间序列数据操作
Pandas 的时间序列功能非常强大,适合处理金融、传感器等时间相关数据:
# 创建日期范围
date_range = pd.date_range(start="2024-01-01", end="2024-12-31", freq="D")
date_range

df = pd.DataFrame({
"date": date_range,
"value": np.random.randn(len(date_range)).cumsum()
})
df
df.set_index("date", inplace=True)
df
# 重采样 - 降低频率(如日期数据转为月数据)
monthly_avg = df.resample("M").mean()
monthly_avg
weekly_max = df.resample("W").max()
weekly_max
# 移动窗口统计
df["7D_rolling_avg"] = df["value"].rolling(window="7D").mean()
df
df["30D_rolling_std"] = df["value"].rolling(window="30D").std()
df
# 时间偏移
df["prev_month"] = df["value"].shift(30) # 前30天的值
df
df["yoy_change"] = df["value"] - df["value"].shift(365)
df
# 按季度、月份分组
quarterly_data = df.groupby(pd.Grouper(freq='Q')).agg(['mean', 'min', 'max'])
quarterly_data
month_of_year = df.groupby(df.index.month).mean() # 各月平均值
month_of_year
这些方法可以轻松处理复杂的时间序列分析任务,如趋势分析、季节性分析等。
七、高效合并和连接多个 DataFrame
数据合并是日常数据处理的常见操作,Pandas 提供了多种方式
# 创建示例数据
df1 = pd.DataFrame({
"key": ["A", "B", "C", "D"],
"value1": [1, 2, 3, 4]
})
df2 = pd.DataFrame({
"key": ["B", "D", "E", "F"],
"value2": [5, 6, 7, 8]
})
display(df1, df2)
# 1.使用 merge 进行 sql 风格的连接
inner_join = pd.merge(df1, df2, on='key') # 内连接
inner_join
left_join = pd.merge(df1, df2, on='key', how='left') # 左连接
left_join
outer_join = pd.merge(df1, df2, on='key', how='outer') # 外连接
outer_join
# 2.使用concat 垂直或者水平组合数据
vertical_concat = pd.concat([df1, df2], ignore_index=True) # 垂直合并
vertical_concat
horizontal_concat = pd.concat([df1, df2], axis=1) # 水平合并
horizontal_concat
# 3.使用 join 基于索引合并
df1.set_index('key', inplace=True)
df2.set_index('key', inplace=True)
joined = df1.join(df2, how='inner') #基于索引合并
joined
# 4.高性能合并大型数据集
df1_sorted = df1.sort_index()
df2_sorted = df2.sort_index()
efficient_join = pd.merge_asof(df1_sorted, df2_sorted, left_index=True, right_index=True)
efficient_join
选择合适的合并方法取决于具体需求和数据结构,合理使用可以避免不必要的数据赋值和内存消耗
八、使用分组操作进行高效数据分析
分组运算是数据分析的核心功能之一
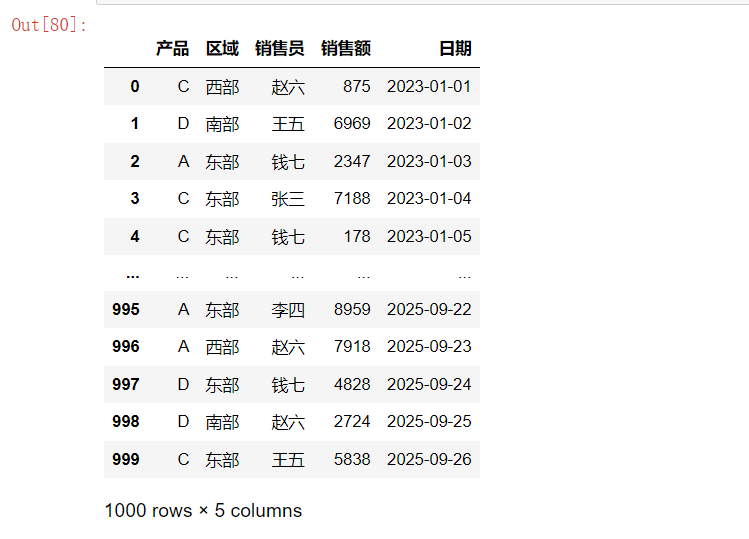
# 创建示例销售数据
np.random.seed(42)
df = pd.DataFrame({
"产品": np.random.choice(['A', 'B', 'C', 'D'], 1000),
"区域": np.random.choice(['东部', '西部', '南部', '北部'], 1000),
"销售员": np.random.choice(['张三', '李四', '王五', '赵六', '钱七'], 1000),
"销售额": np.random.randint(100, 10000, 1000),
"日期": pd.date_range('2023-01-01', periods=1000)
})
df
# 1.基本分组统计
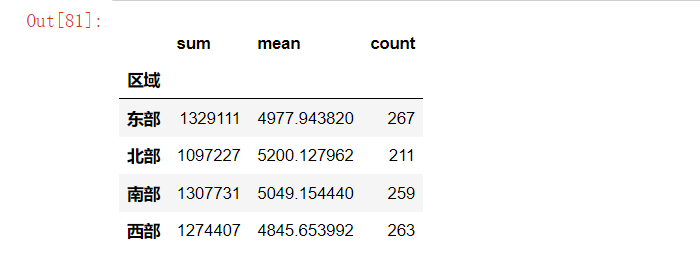
region_stats = df.groupby('区域')['销售额'].agg(['sum', 'mean', 'count'])
region_stats
# 2.多级分组
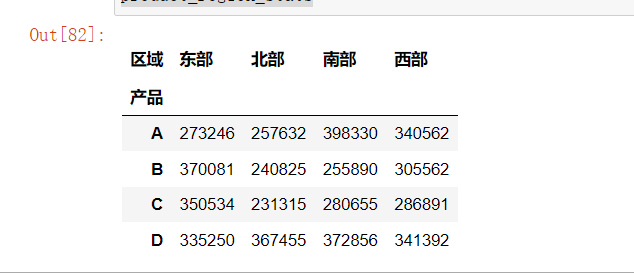
product_region_stats = df.groupby(["产品", "区域"])['销售额'].sum().unstack()
product_region_stats
# 3.按时间分组
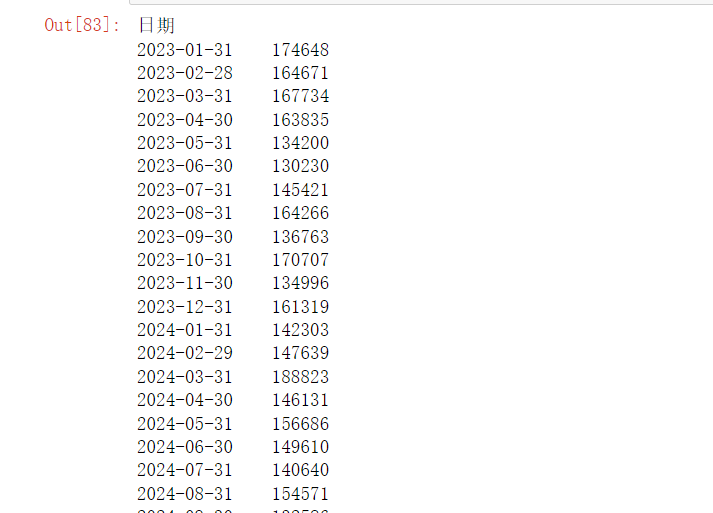
monthly_sales = df.groupby(pd.Grouper(key='日期', freq='M'))['销售额'].sum()
monthly_sales
# 4.使用自定义聚合函数
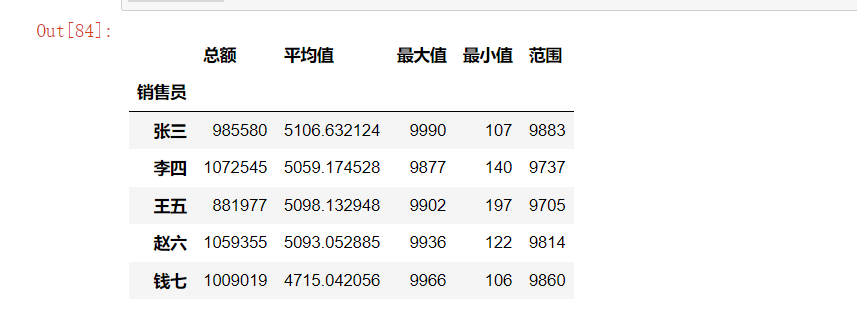
def range_stat(x):
return x.max() - x.min()
custom_agg = df.groupby('销售员')['销售额'].agg([
('总额', 'sum'),
('平均值', 'mean'),
('最大值', 'max'),
('最小值', 'min'),
('范围', range_stat)
])
custom_agg
# 5、分组转化和过滤
# 标准化每个组内的销售额
df['标准化销售额'] = df.groupby('产品')['销售额'].transform(lambda x: (x - x.mean()) / x.std())
df
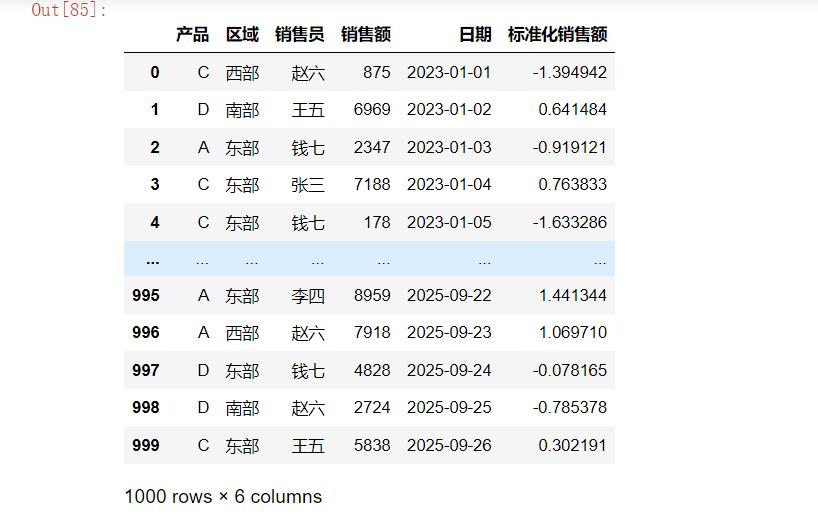
# 筛选销售额高于组平均值的记录
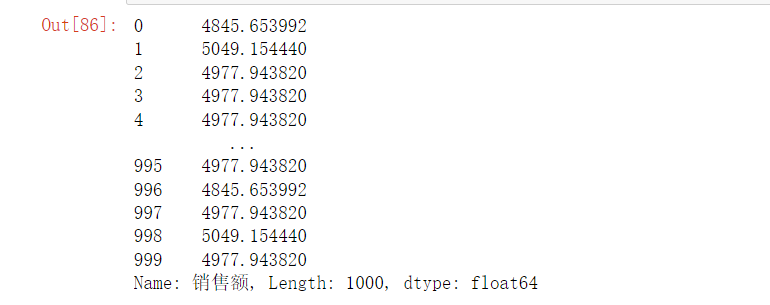
group_means = df.groupby('区域')['销售额'].transform('mean')
group_means
high_performers = df[df['销售额'] > group_means]
high_performers
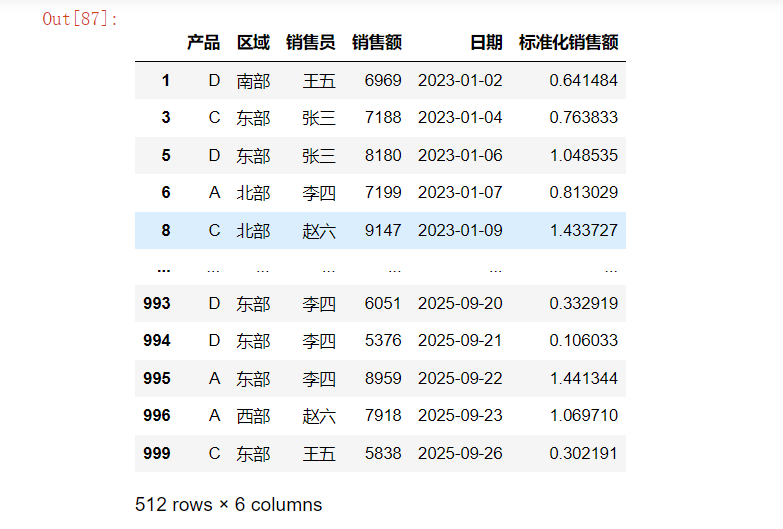
分组操作可以深入挖掘数据中的关系和模式
九、处理缺失值
实际数据集常常包含缺失值,正确处理它们对于数据分析至关重要:
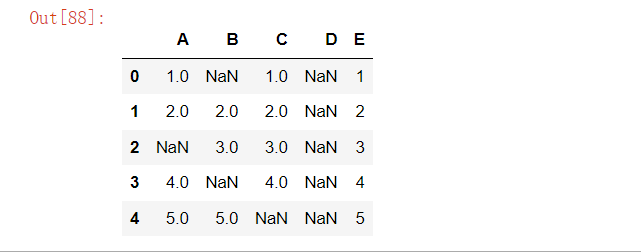
# 创建带有缺失值的数据
df = pd.DataFrame({
'A': [1, 2, np.nan, 4, 5],
'B': [np.nan, 2, 3, np.nan, 5],
'C': [1, 2, 3, 4, np.nan],
'D': [np.nan, np.nan, np.nan, np.nan, np.nan],
'E': [1, 2, 3, 4, 5]
})
df
# 1.检查缺失值
missing_count = df.isnull().sum()
missing_count

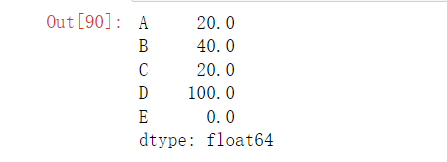
missing_percent = (df.isnull().sum() / len(df)) * 100
missing_percent
# 2.基于条件填充缺失值
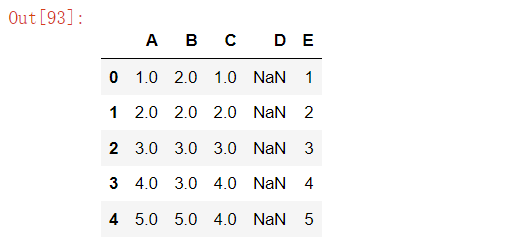
df['A'] = df['A'].fillna(df['A'].mean()) # 使用平均值填充 A 列
df['B'] = df['B'].fillna(method='bfill') # 使用向前填充法
df['C'] = df['C'].fillna(method='ffill') # 使用向后填充法
df
# 3.使用插值法填充缺失值
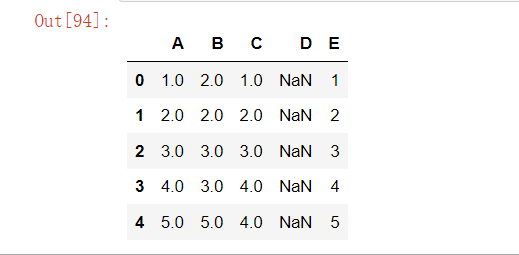
df['D'] = df['D'].interpolate(methods='linear') # 线性插值
df['D'] = df['D'].interpolate(methods='polynomial', order=2) # 多项式插值
df
# 4.基于多列填充缺失值
# 使用其他列构建预测模型填充缺失值
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=2)
df_filled = pd.DataFrame(
imputer.fit_transform(df),
columns=df.columns
)
df_filled
# 5、按组填充缺失值
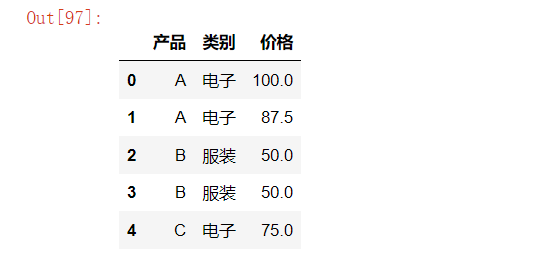
# 例如 按照产品类别的平均价格填充缺失值的价格
product_df = pd.DataFrame({
'产品': ['A', 'A', 'B', 'B', 'C'],
'类别': ['电子', '电子', '服装', '服装', '电子'],
'价格': [100, np.nan, 50, np.nan, 75]
})
product_df
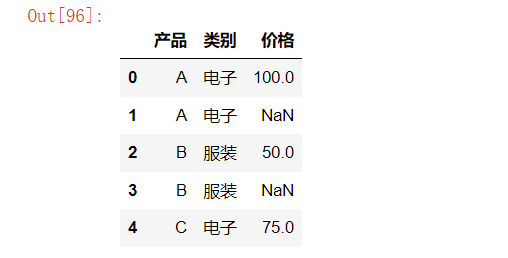
product_df['价格'] = product_df.groupby('类别')['价格'].transform(
lambda x: x.fillna(x.mean())
)
product_df
选择合适的缺失值处理方法应基于数据的性质和分析目标,而不是机械的删除或者填充
十、高级索引和查询
在处理大型数据集时,高效的索引和查询方法可以显著提升性能
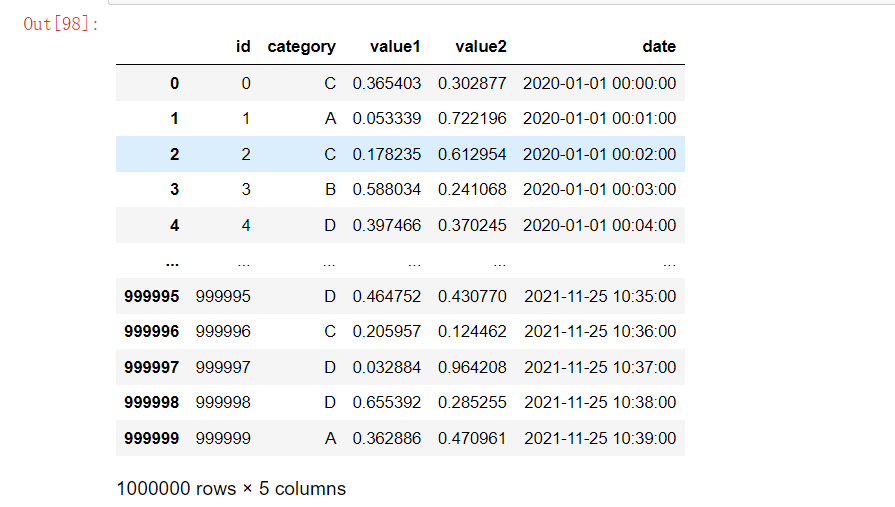
# 创建大型数据集
df = pd.DataFrame({
"id": range(1000000),
"category": np.random.choice(['A', 'B', 'C', 'D', 'E'], 1000000),
"value1": np.random.rand(1000000),
"value2": np.random.rand(1000000),
"date": pd.date_range("2020-01-01", periods=1000000, freq='T')
})
df
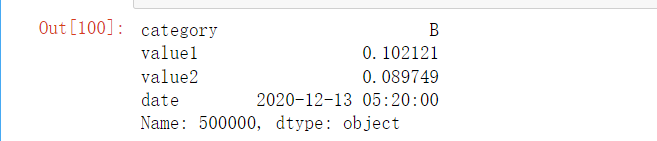
# 1.设置正确的索引加速查询
df.set_index("id", inplace=True) # 设置主键索引
# 查询单个记录
result1 = df.loc[500000] # 通过索引直接访问
result1
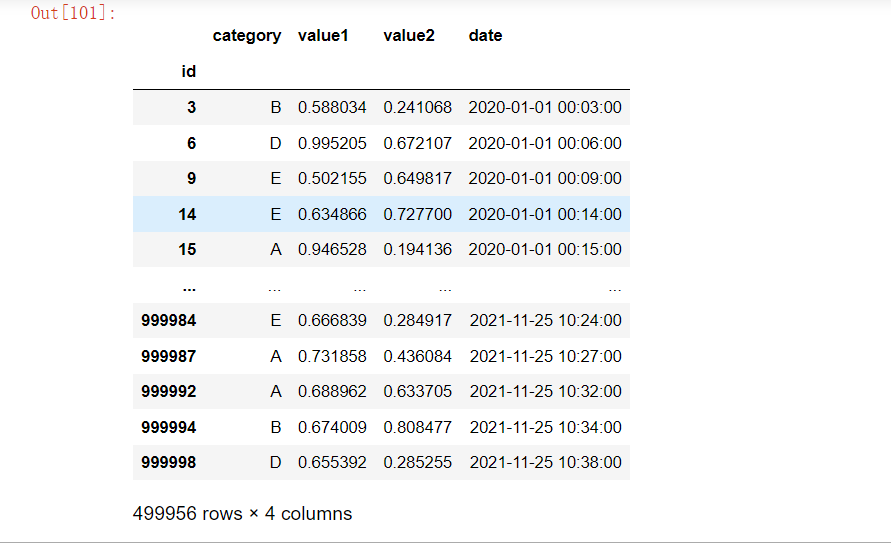
# 2.使用布尔索引的高效方法
# 较低效的方法(生成完整的 布尔数组)
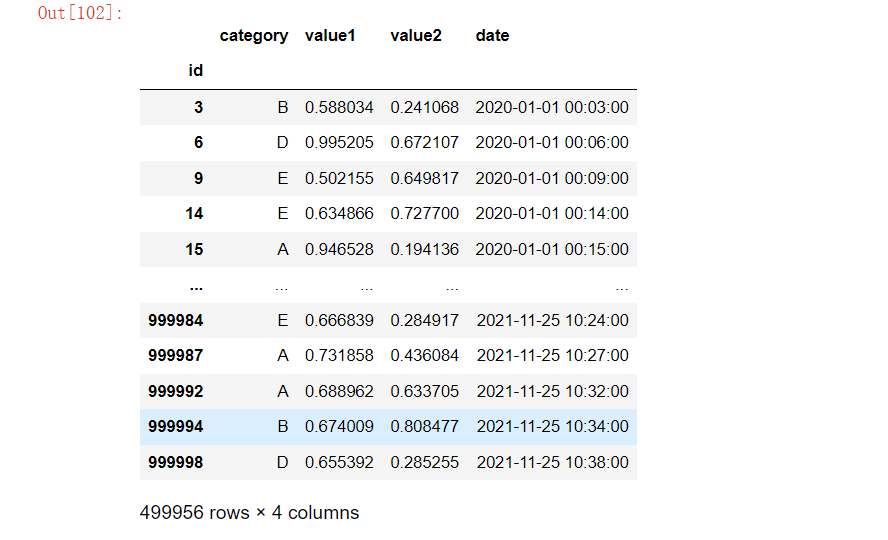
result2 = df[df['value1'] > 0.5]
result2
# 更高效的方法
result3 = df.query('value1 > 0.5')
result3
# 3.使用分类类型加速
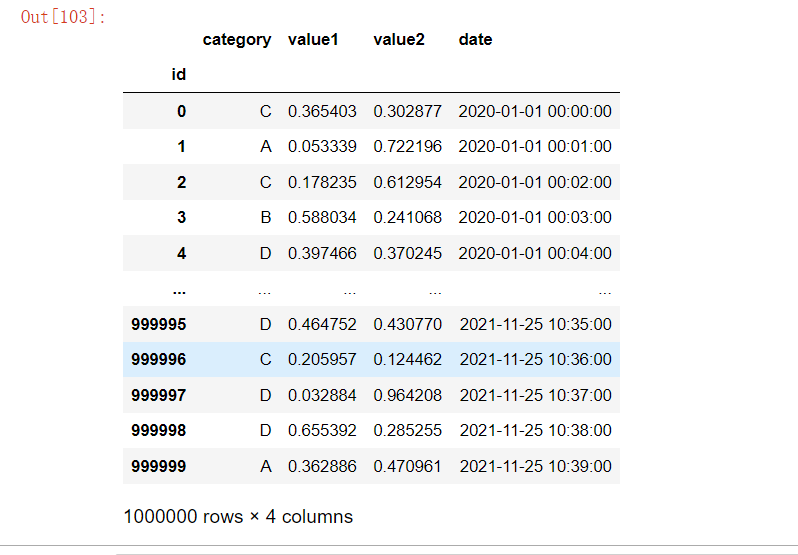
df['category'] = df['category'].astype('category') # 转化为分类类型
df
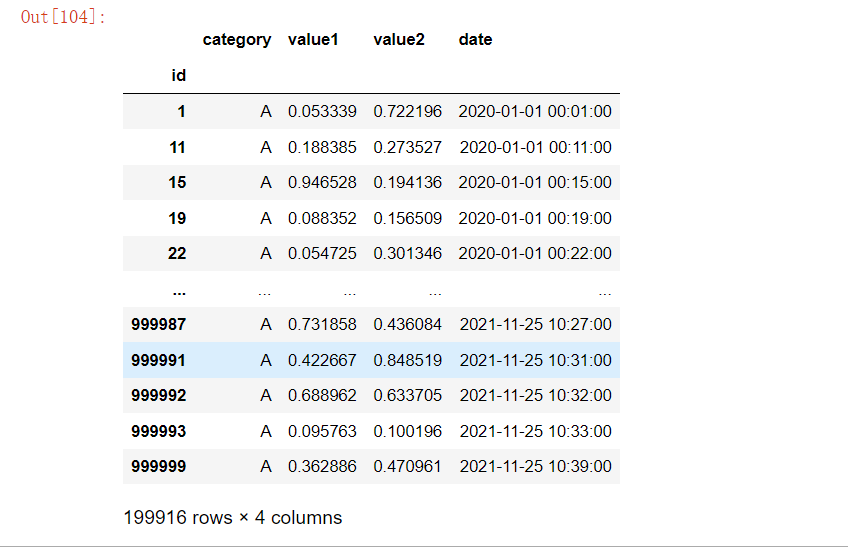
result4 = df[df['category'] == "A"]
result4
# 4、时间序列高效索引
df.set_index('date', inplace=True)
# 使用部分索引查询
result5 = df['2020-06']
result5
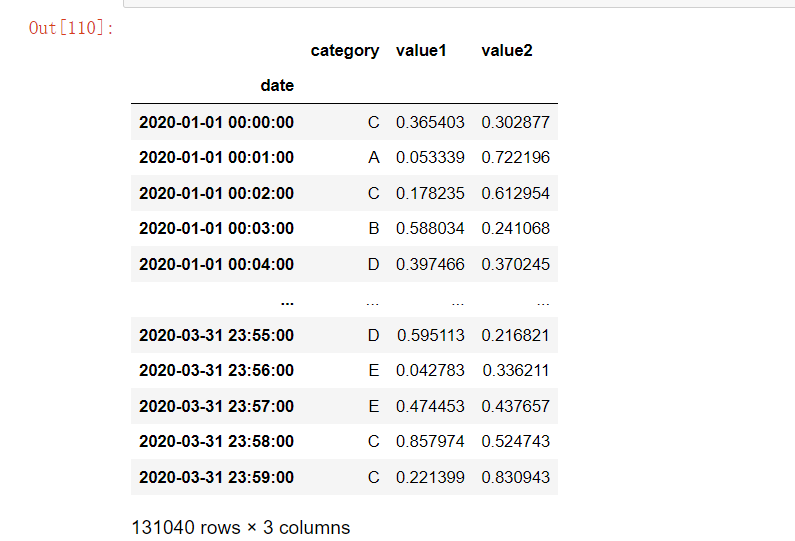
result6 = df.loc['2020-01-01': '2020-03-31']
result6
# 4、使用 .at 和 .iat 进行单元格访问
value1 = df.loc['2020-01-01 00:30:00', 'value1']
value1
value1 = df.at['2020-01-01 00:30:00', 'value1']
value1
# 使用整数位置更快的访问
first_cell = df.iat[0, 0] #访问第一列和第一行
first_cell
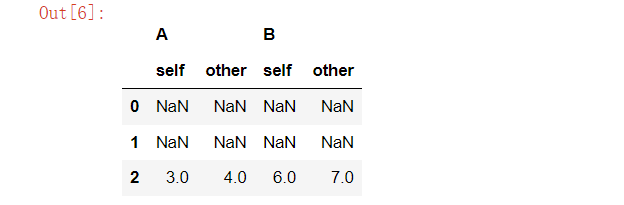
十一、比较两个相同形状的DataFrame 或者 Series对象,快速找出差异
import pandas as pd
df1 = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
})
df2 = pd.DataFrame({
'A': [1, 2, 4],
'B': [4, 5, 7]
})
display(df1, df2)

diff = df1.compare(df2, keep_shape=True)
diff
"""
默认情况下,结果 DataFrame 的列将被重新命名为多级列索引 (column, self/other) 格式,其中 self 表示第一个操作数(调用 compare 方法的对象),而 other 表示作为参数传递的对象。例如,在上面的例子中,如果两者的 'A' 列有不同之处,则结果中的列名将是 ('A', 'self') 和 ('A', 'other')。
keep_shape: 如果设置为 True,即使值相同,也会保留原DataFrame的形状,并且相同值的地方将填充 NaN。
keep_equal: 如果设置为 True 并且 keep_shape=True,则相同值的地方将保持原值而不是填充 NaN。
"""


















 2627
2627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









