





redis的四个问题:
1.Redis是基于内存存储,服务重启可能会丢失数据;
2.并发能力问题:单节点Redis能力虽然不错,但也无法满足如618这种高并发的场景(618并发
数量达到数十万甚至上百万);
3.如果reids宕机,服务不可用,则需要一种自动的故障恢复手段;
4.存储能力问题: Redis是基于内存,单节点存储的数据难以满足海量数量需求;
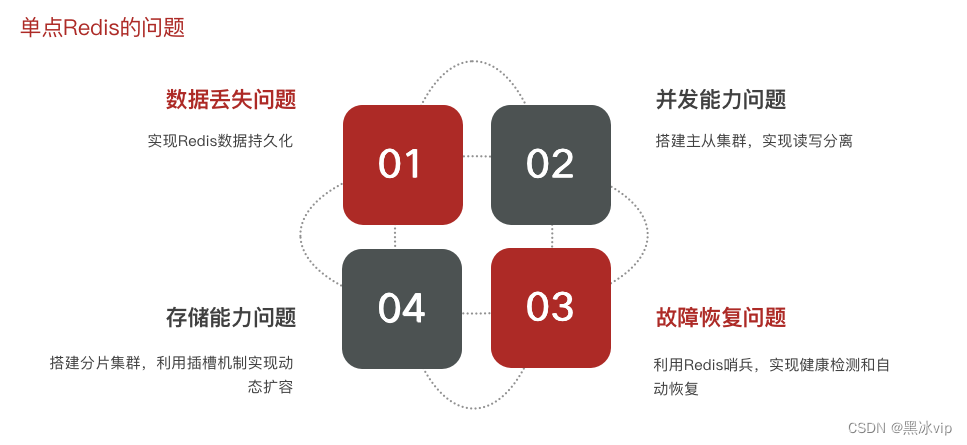
重要:
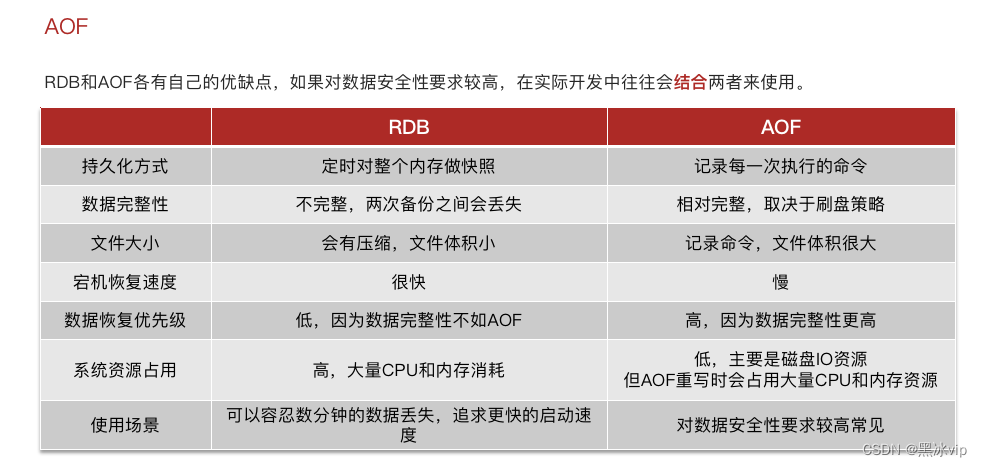
数据丢失:利用持久化,将数据写入磁盘,数据一但落盘数据就安全了;
并发能力问题:做负载均衡的集群,reids内部就有一种主从集群,其中从节点可以有很多个,彼此之前是负
载均衡的,主从节点之间可以实现读写分离(读写互斥并发能力会更强);高可用:主节点宕机了,从节点还能
顶上使用;
故障恢复问题:虽然主从模式具有高可用,但是如果一直挂掉不恢复还是会有问题(全部宕机);这时候就要
依赖哨兵机制:去监测主从节点的健康状况,一但发现有宕机的机器立马自动启动恢复机制;这样就实现了
高可用、高并发;
存储能力问题:由于数据的上限还是单个节点的上限;使用分片集群,利用插槽机制实现动态扩容;(理论
上是没有上限的)
1. Redis持久化
 1.1 RDB持久化
1.1 RDB持久化 
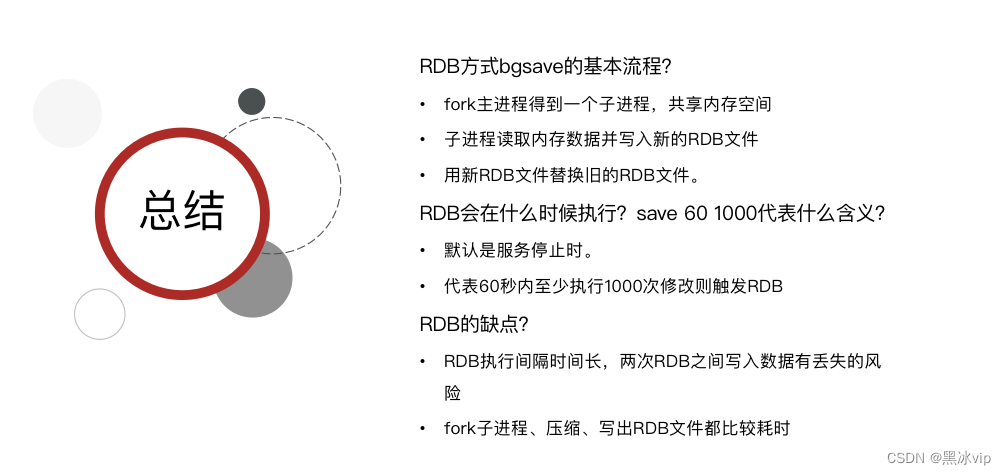
save:不推荐 主进程执行RDB,并且通过消耗大量io将数据存储到磁盘中(耗时比较久).影响redis
对外提供服务;
bsave:推荐
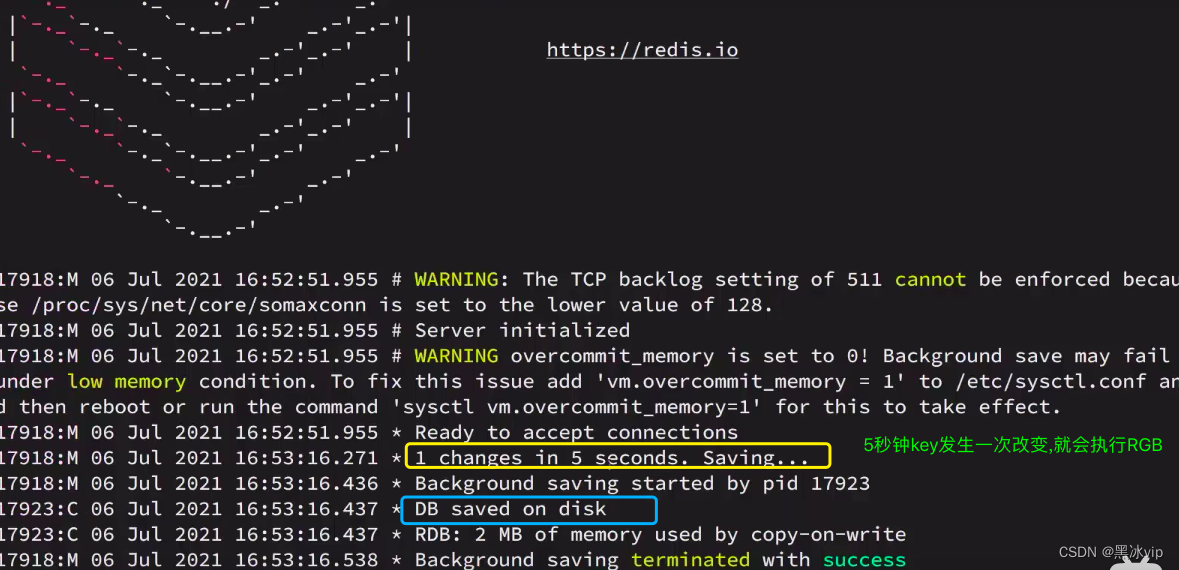
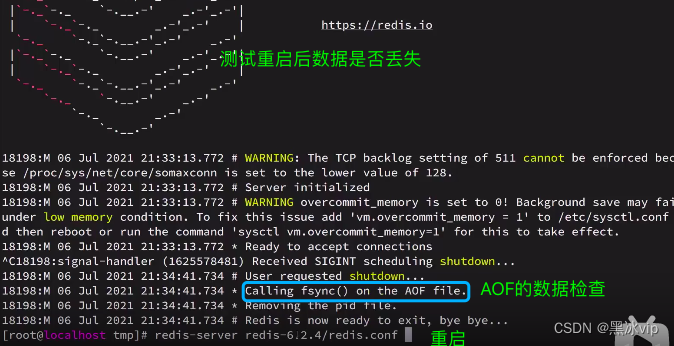
演示:Redis停机时会执行一次RDB
1.启动Redis


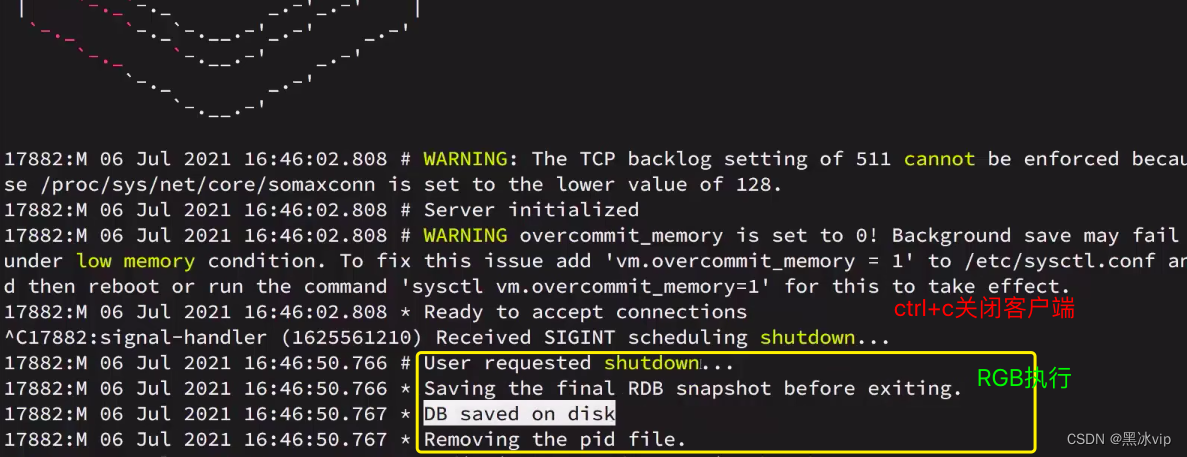
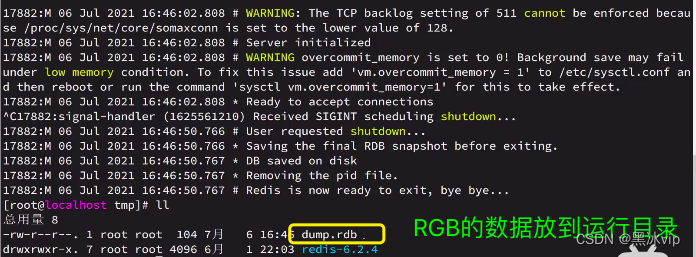 再一次启动客户端,数据就会恢复
再一次启动客户端,数据就会恢复

如何定时触发RDB:
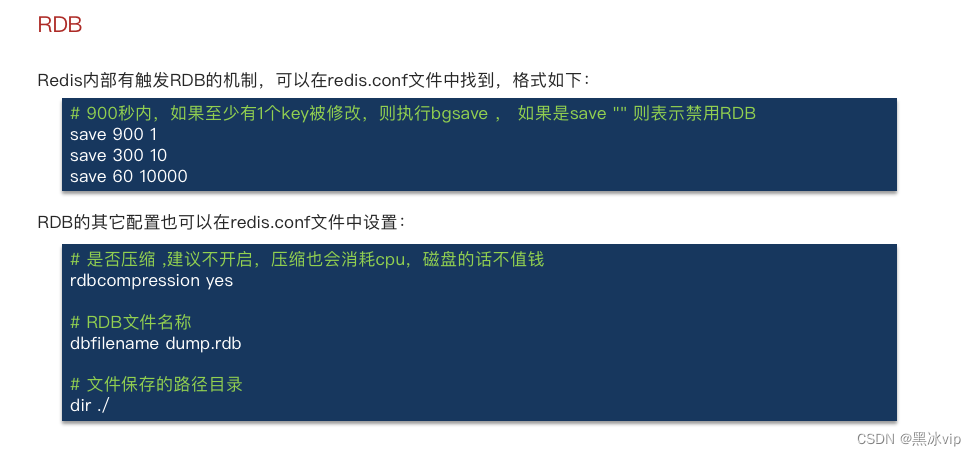
演示:
redis.conf
save 5 1
dbfilename test.rdb
 RDB的问题:比如设置30秒钟,30秒中发生宕机就会有 数据丢失
RDB的问题:比如设置30秒钟,30秒中发生宕机就会有 数据丢失
20:04- RDB的底层原理
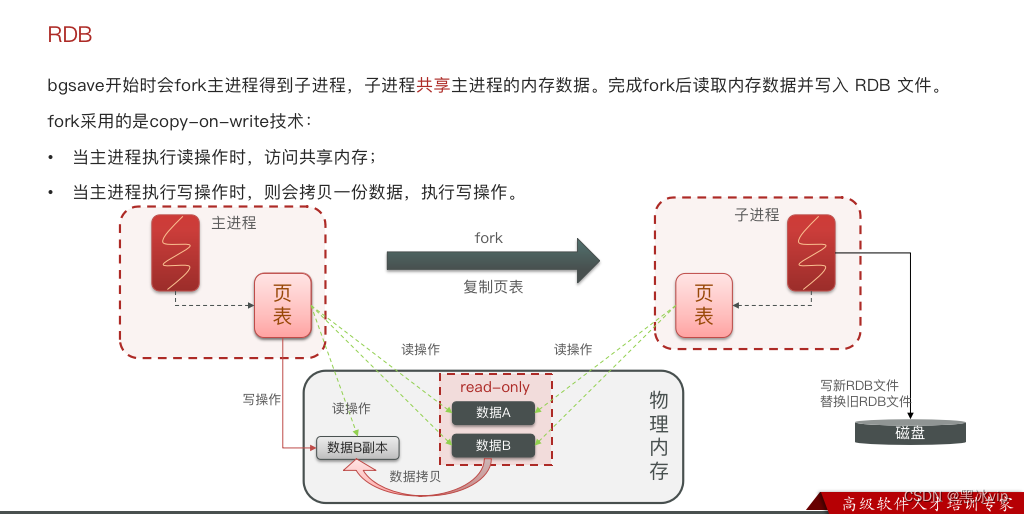
2.1 AOF持久化
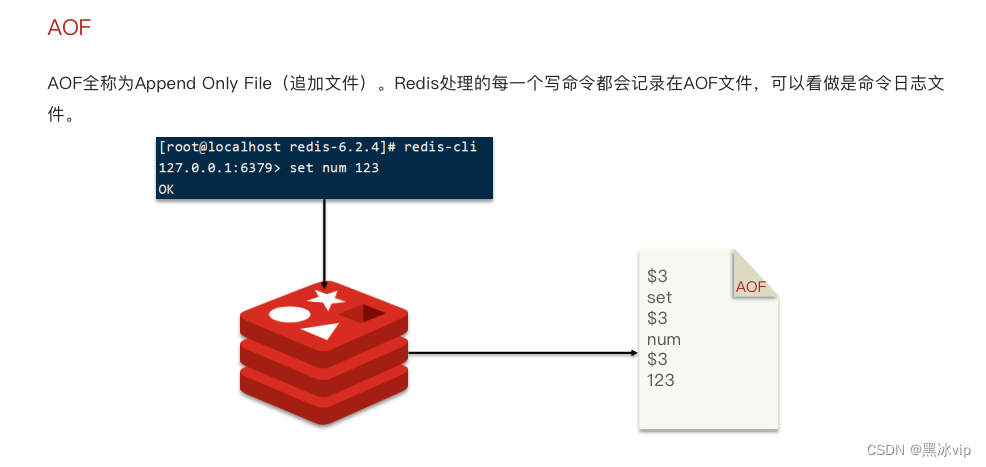

演示:
redis.conf
save "" #禁用RGB
appendonly yes #开启AOF功能
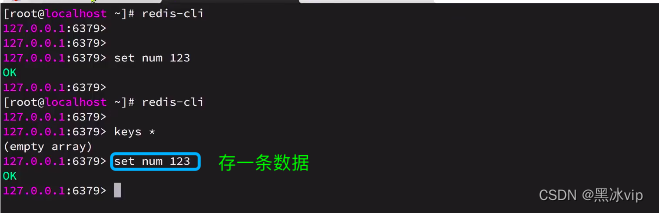
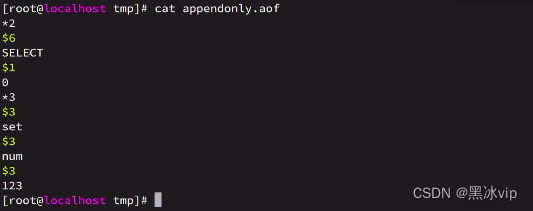
aof文件已经产生(接着存储就接着记录):
如何解决对同一个key的多次写操作:
用最少得命令达到相同的效果,减少AOF 文件的体积
什么时候重写AOF文件?



如果同时启动了RDB和AOF,AOF优先级更高点(因为AOF的数据更完整)
一般会结合使用:RDB(做数据备份,异地容灾) 、AOF(宕机后数据恢复)
2. Redis主从

2.1 搭建主从架构
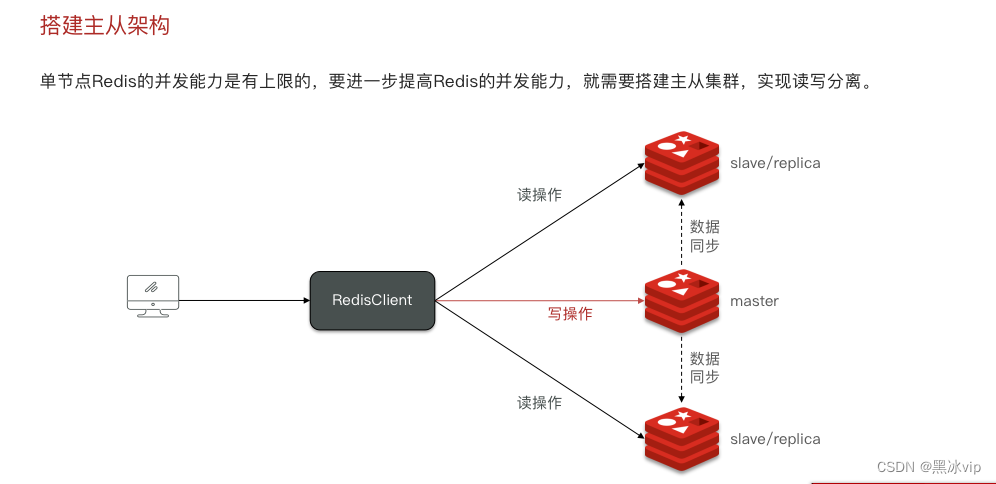
1.读写分离
2.提高从节点的并行度
 2.2 数据同步原理
2.2 数据同步原理
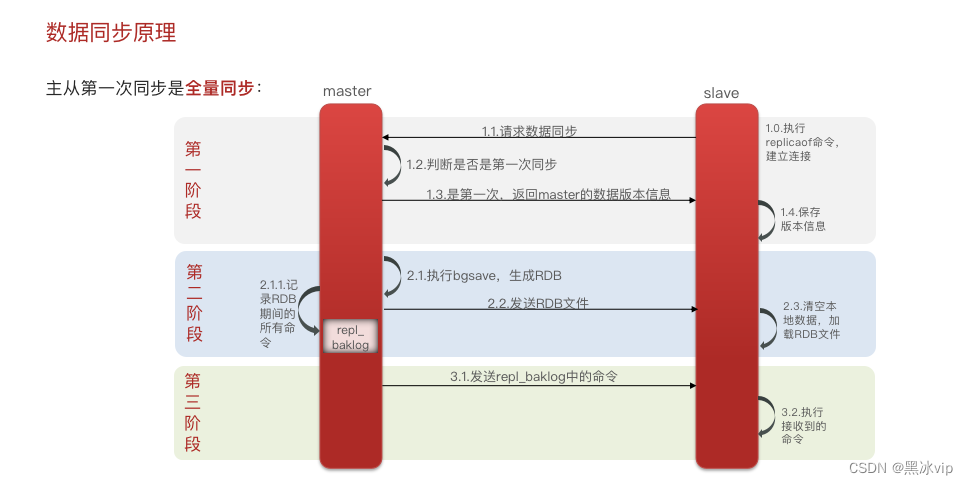

判断是不是第一次同步?
有没有replication id
28:35-30:57 讲解原理

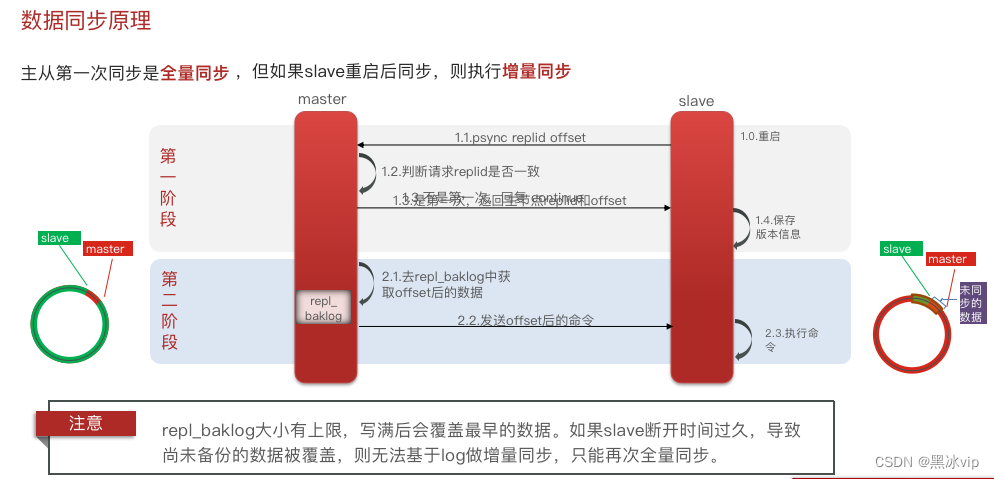
slave重启的时候必然会有数据落后,这时候就需要做增量同步
Repl_baklog如何记录命令?如何找到之后需要执行的命令?
Repl_baklog:是一个环形数组,存储记录的命令
需要执行的命令=master和slave之前差异的缓存区
如右图:超过上限需要做全量同步(从master的内存中同步)
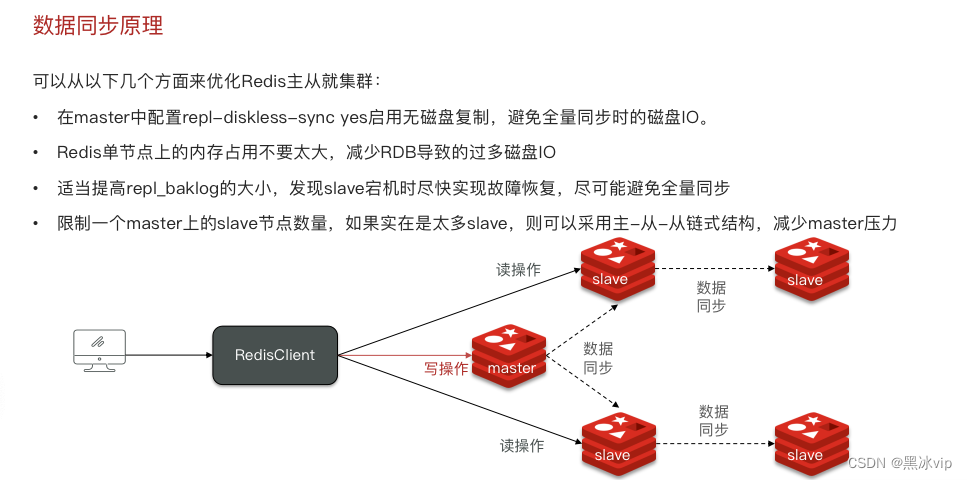
1.repl-diskeless-sync=yes
适合的场景:磁盘比较慢,网络比较快
不适合:网络带宽比较慢,会造成一定程度的网络阻塞
正常的拷贝:master会将RDB文件写入到磁盘中(占用大量IO流),然后通过网络发送给slave
配置后, 直接通过网络发送给slave 性能能提高很多


3.Redis哨兵

3.1 哨兵的作用和原理
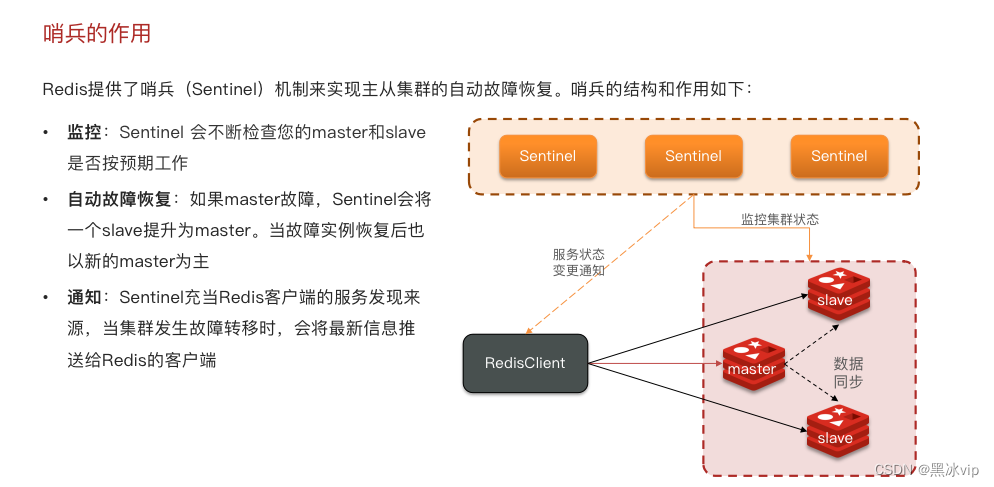
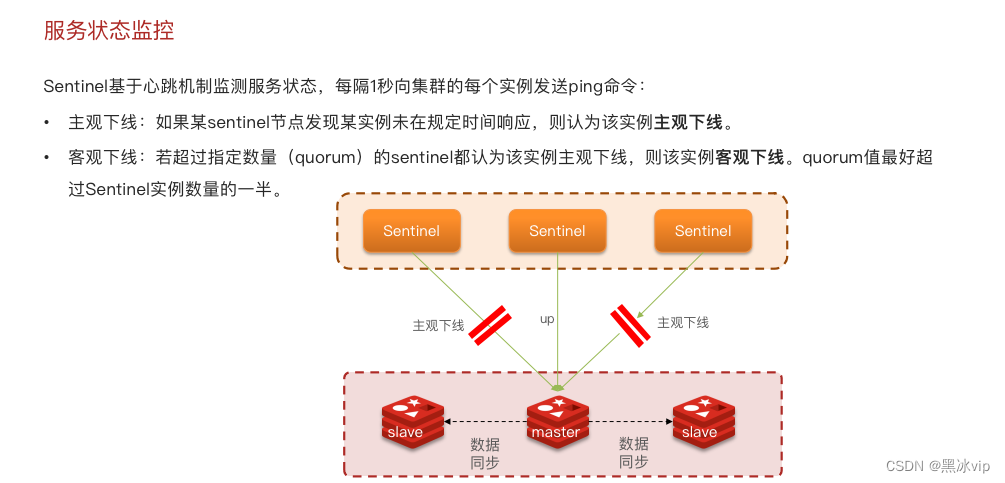
主观下线不一定是真的下线,有可能是网络阻塞;

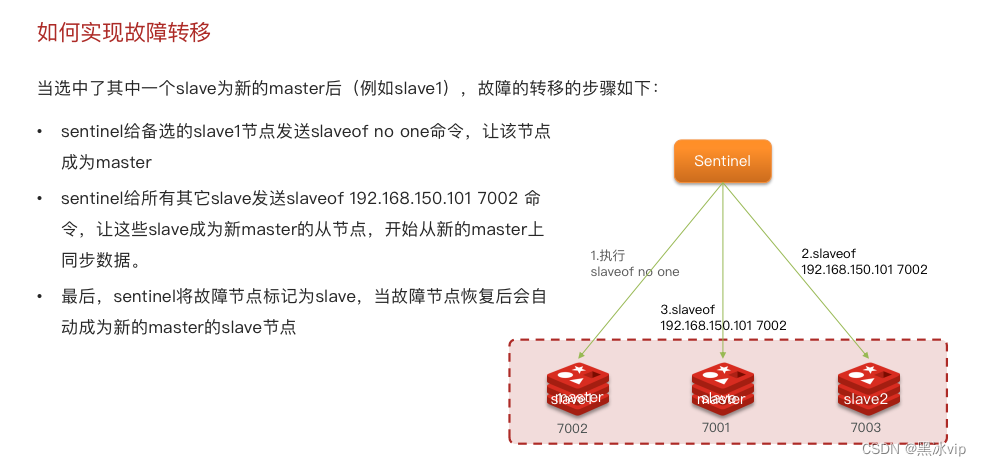
3.2 搭建哨兵架构

21:54-27:00 测试redis的哨兵模式日志讲解
3.3 RedisTemplate的哨兵模式

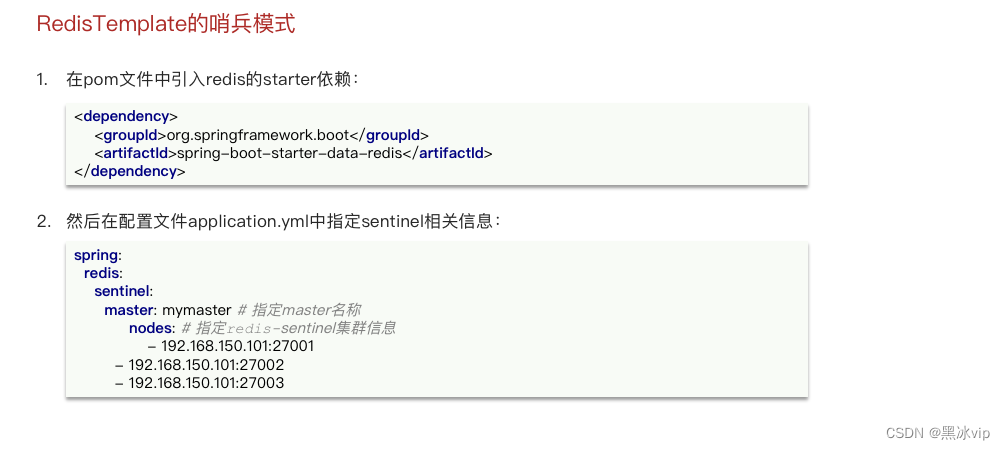

36:40-end 讲解哨兵机制打印日志
4. Redis分片集群
4.1 搭建分片集群
以上集群存在的问题:
1.单个节点数据内存上限不易过大(比如:10G),海量数据如何存储
2.上面集群只解决了并发读取的问题,但是没有解决并发写的问题
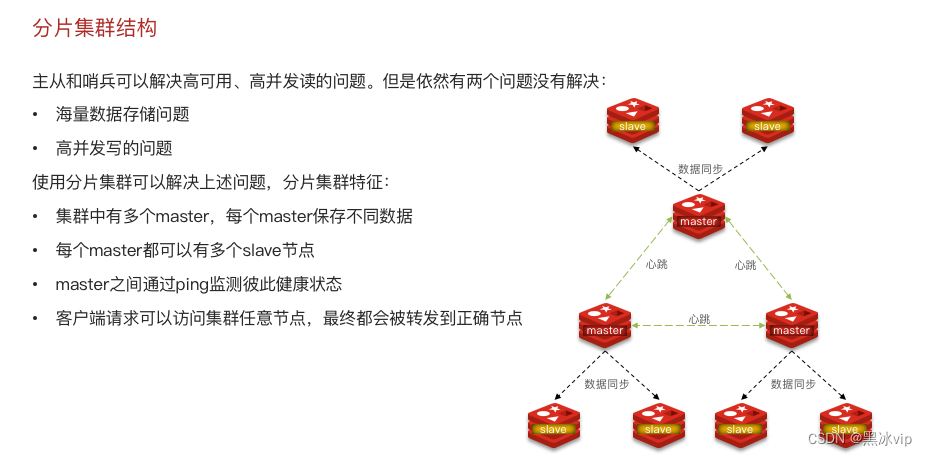
解决方案:
问题一:多个master存储不同的数据(比如每个master都能存储20G,三个master存储60G)解决了
海量数据存储的问题;
问题二:因为有多个master节点就可以很好的解决并发写入的问题(每个master都可以写入数据);
这个集群为什么不需要哨兵机制?
回答:因为多个master之间都通过心跳机制去检测彼此的健康状态;
客户端要去访问哪个节点?
回答:客户端请求可以访问集群的任意节点,最终通过路由到正确节点上;

4.2 散列插槽
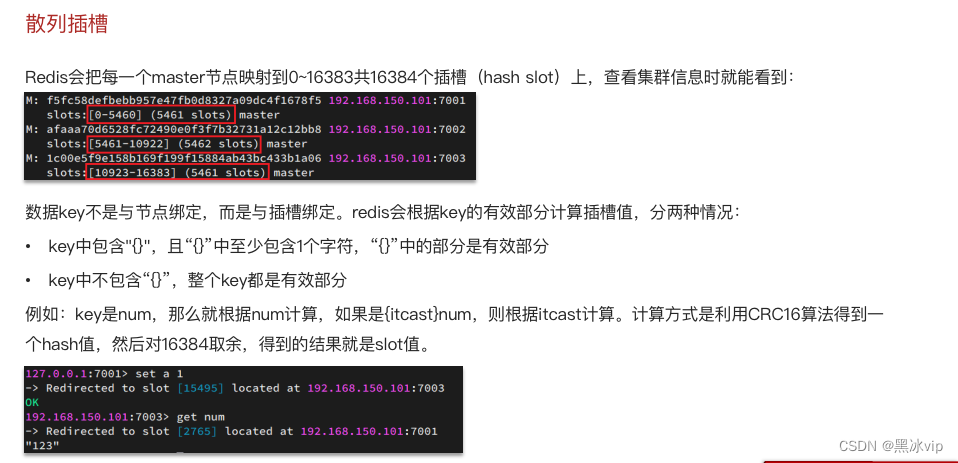
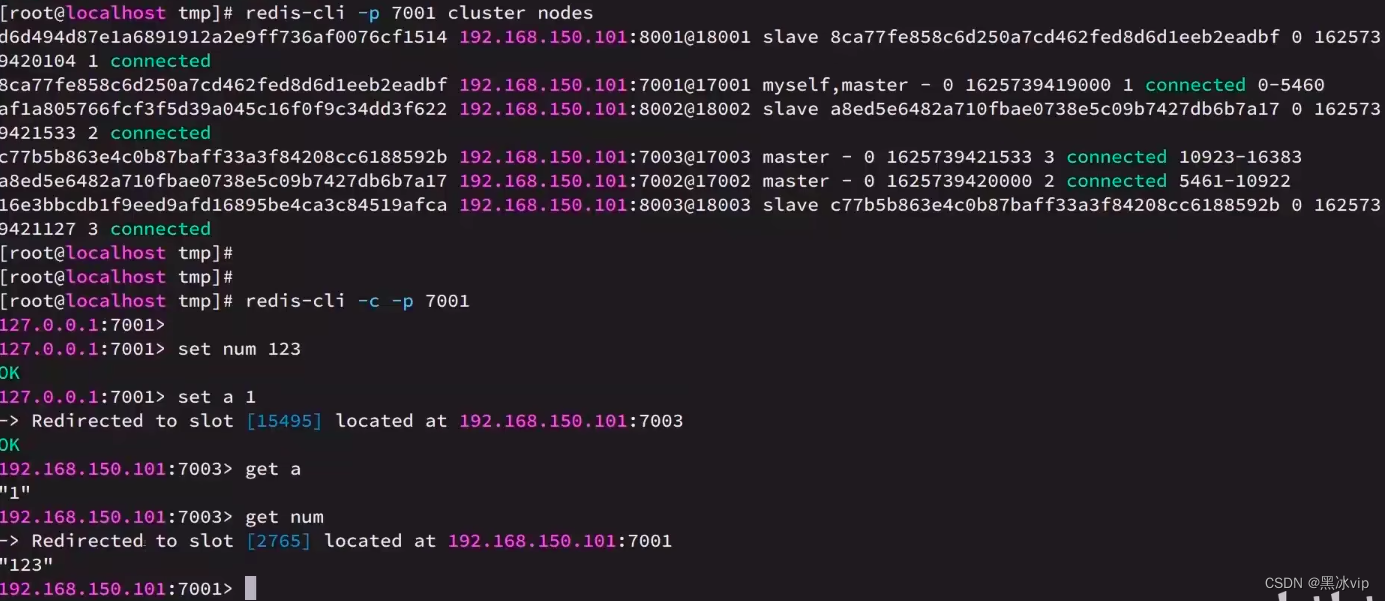

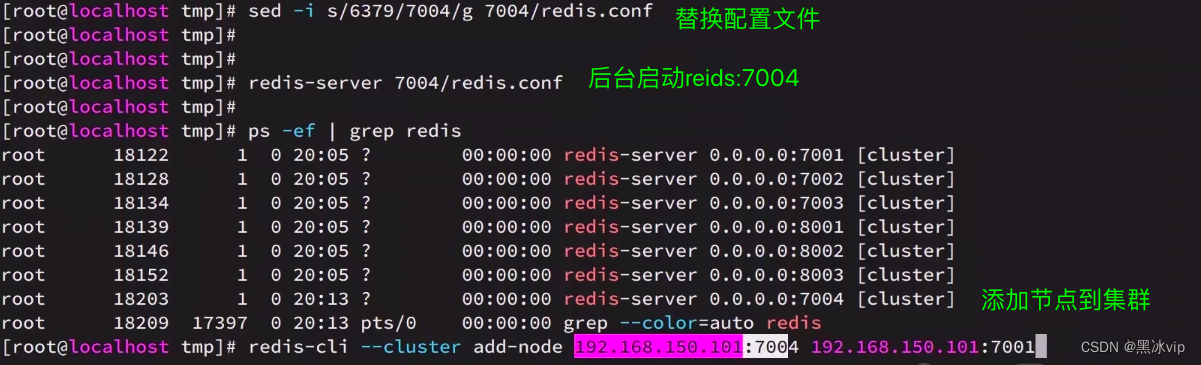
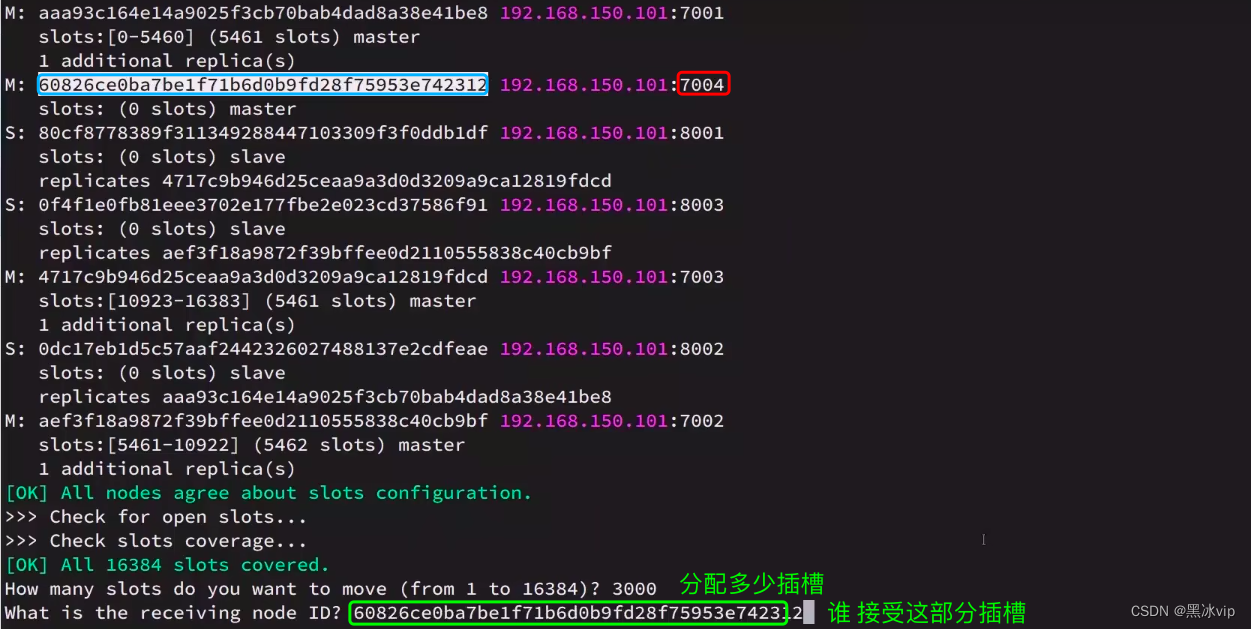
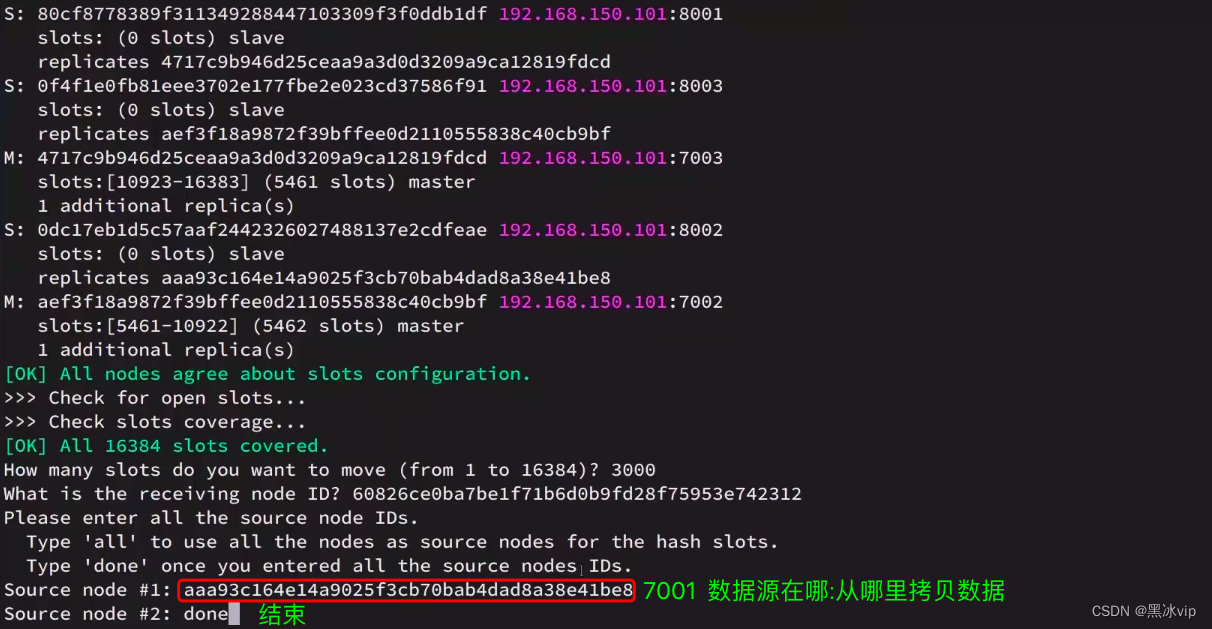
4.3 集群伸缩
集群伸缩:可以动态的增加节点和移除节点
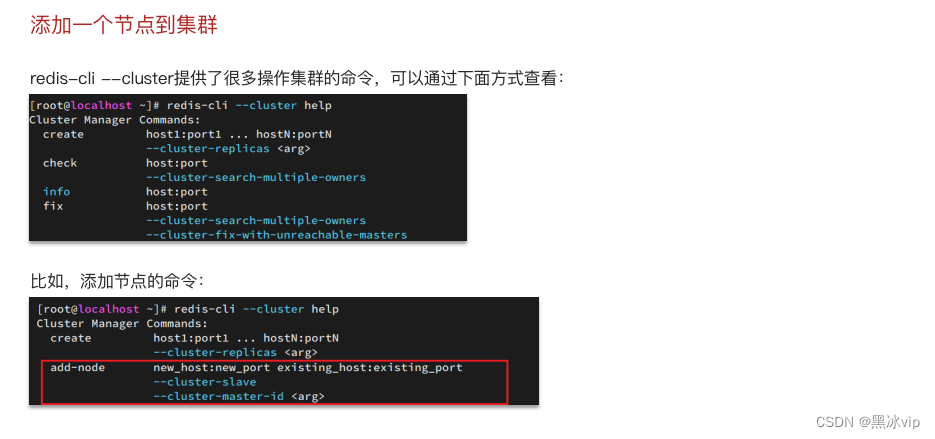

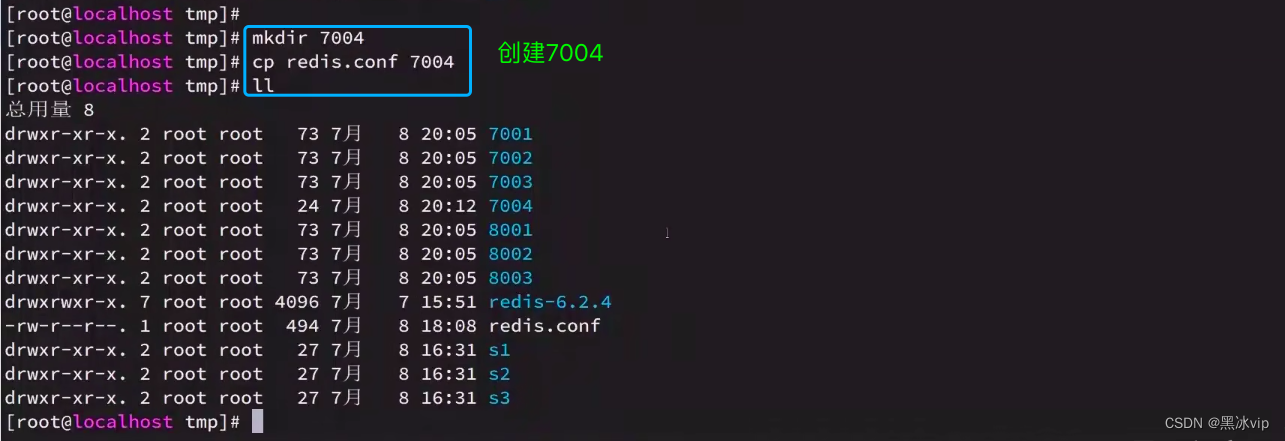




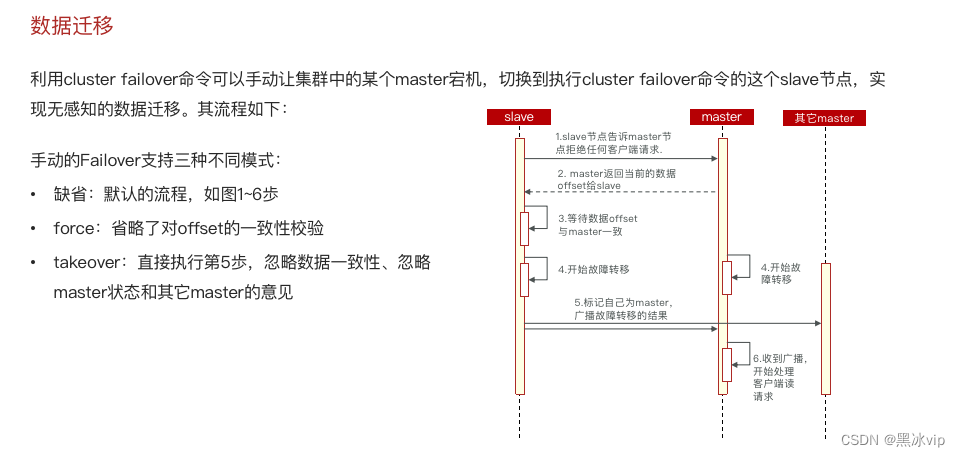
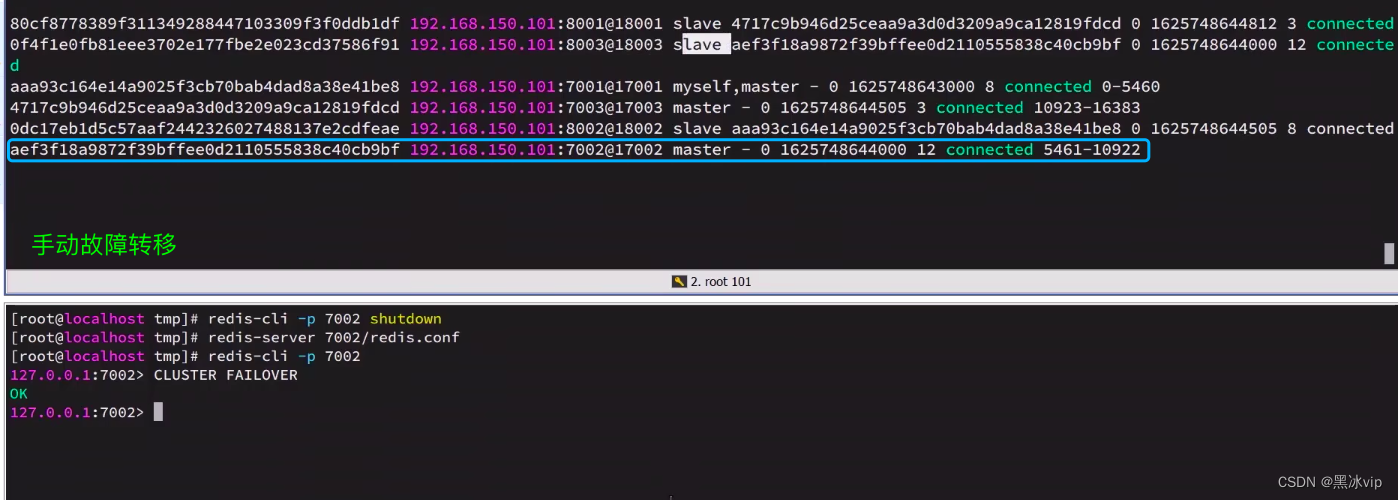
4.4 故障转移


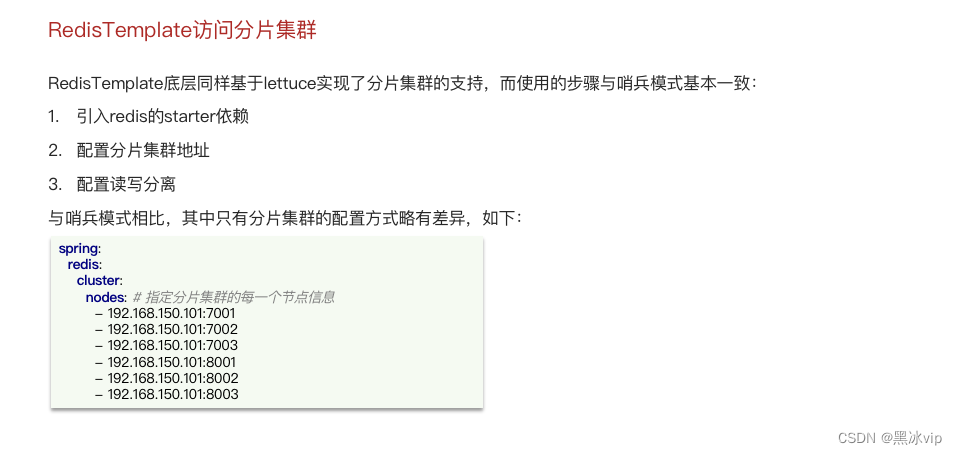
4.5 RedisTemplate访问分片集群

















 8870
8870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









