 HBase与MapReduce集成及批量数据操作
HBase与MapReduce集成及批量数据操作





 本文详细介绍了HBase的API,包括DML操作如Put、Get、Scan(使用Filter)和Delete,以及DDL操作如创建命名空间和表。在批量数据处理方面,讨论了使用sqoop、flume、kettle以及自定义MapReduce和Spark程序的方法。针对MapReduce与HBase的集成,解释了如何解决因缺少HBase jar包导致的报错问题,并演示了rowcounter工具快速统计rowkey数量。此外,介绍了hbase的importtsv工具,用于批量导入TSV数据,以及通过转换为HFile以高效导入大量数据。最后,概述了HBase与MapReduce的集成,包括Driver类、Mapper类和Reducer类的使用。
本文详细介绍了HBase的API,包括DML操作如Put、Get、Scan(使用Filter)和Delete,以及DDL操作如创建命名空间和表。在批量数据处理方面,讨论了使用sqoop、flume、kettle以及自定义MapReduce和Spark程序的方法。针对MapReduce与HBase的集成,解释了如何解决因缺少HBase jar包导致的报错问题,并演示了rowcounter工具快速统计rowkey数量。此外,介绍了hbase的importtsv工具,用于批量导入TSV数据,以及通过转换为HFile以高效导入大量数据。最后,概述了HBase与MapReduce的集成,包括Driver类、Mapper类和Reducer类的使用。
一、Hbase API
-》DML:
Put
Get
Scan:
-》Filter:
MultipleColumnPrefixFilter
SingleColumnValueFilter
Delete
-》API
ResultScanner:对应多个rowkey
Result:对应一个rowkey的值
cell:对应一列
-》DDL
-》创建namespace
-》创建表
二、如何批量往hbase中读写数据
-》批量写:
-》sqoop/flume
-》kettle
-》自己写程序:MapReduce/spark
MapReduce:
-》读hbase数据
-》写入hbase
-》从hbase中读取数据,经过处理将数据写入hbase
官方自带的程序用于实现hbase与MapReduce集成
![]()
bin/yarn jar /opt/cdh-5.7.6/hbase-1.2.0-cdh5.7.6/lib/hbase-server-1.2.0-cdh5.7.6.jar
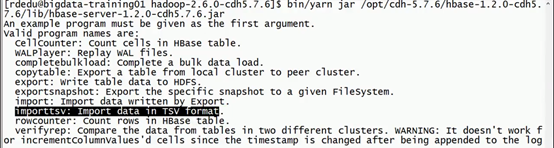
报错:找不到hbase jar包
原因:jar包是在hbase中的,但是运行在hadoop上,hadoop上是没有这个jar包
解决:将MapReduce需要的hbase的jar包添加到hadoop的classpath中
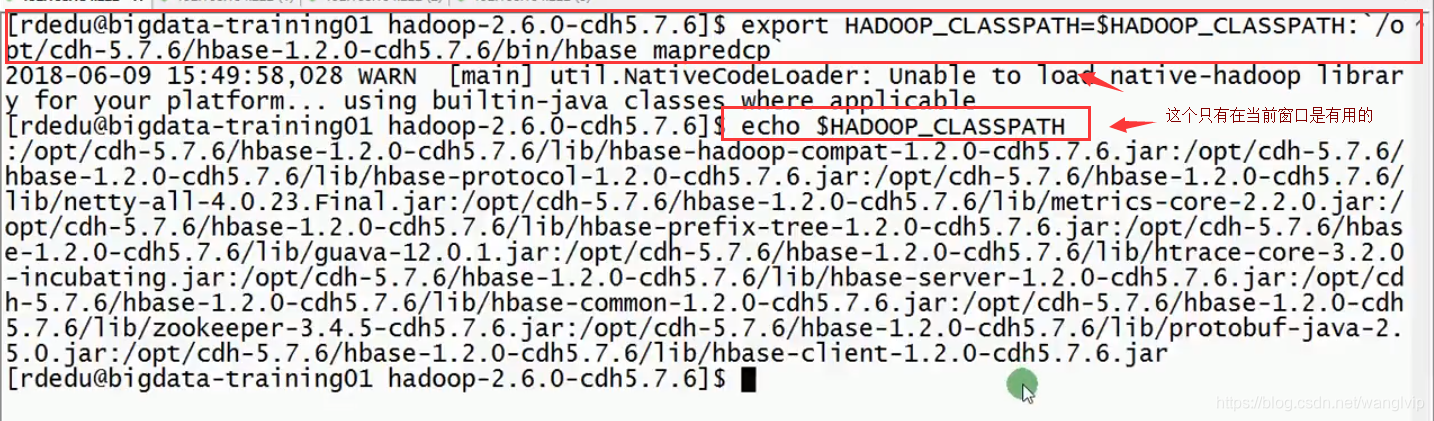
##将`/opt/cdh-5.7.6/hbase-1.2.0-cdh5.7.6/bin/hbase mapredcp`命令执行的结果放到HADOOP_CLASSPATH中
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:`/opt/cdh-5.7.6/hbase-1.2.0-cdh5.7.6/bin/hbase mapredcp`
![]()
rowcounter
功能:统计hbase表中一共有多少个rowkey
语法:Usage: RowCounter [options] <tablename>
[--starttime=[start] --endtime=[end] [--range=[startKey],[endKey]]
[<column1> <column2>...]
HBase中的count比MapReduce中count速度快很多:
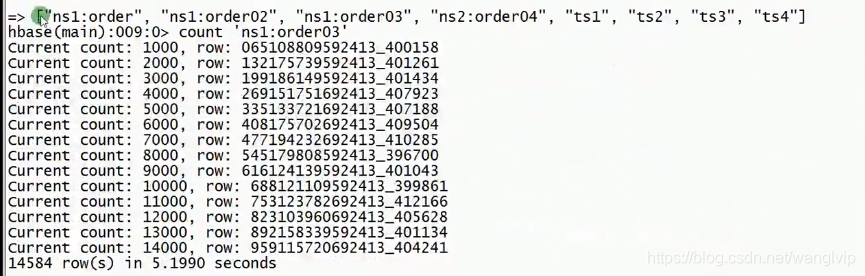

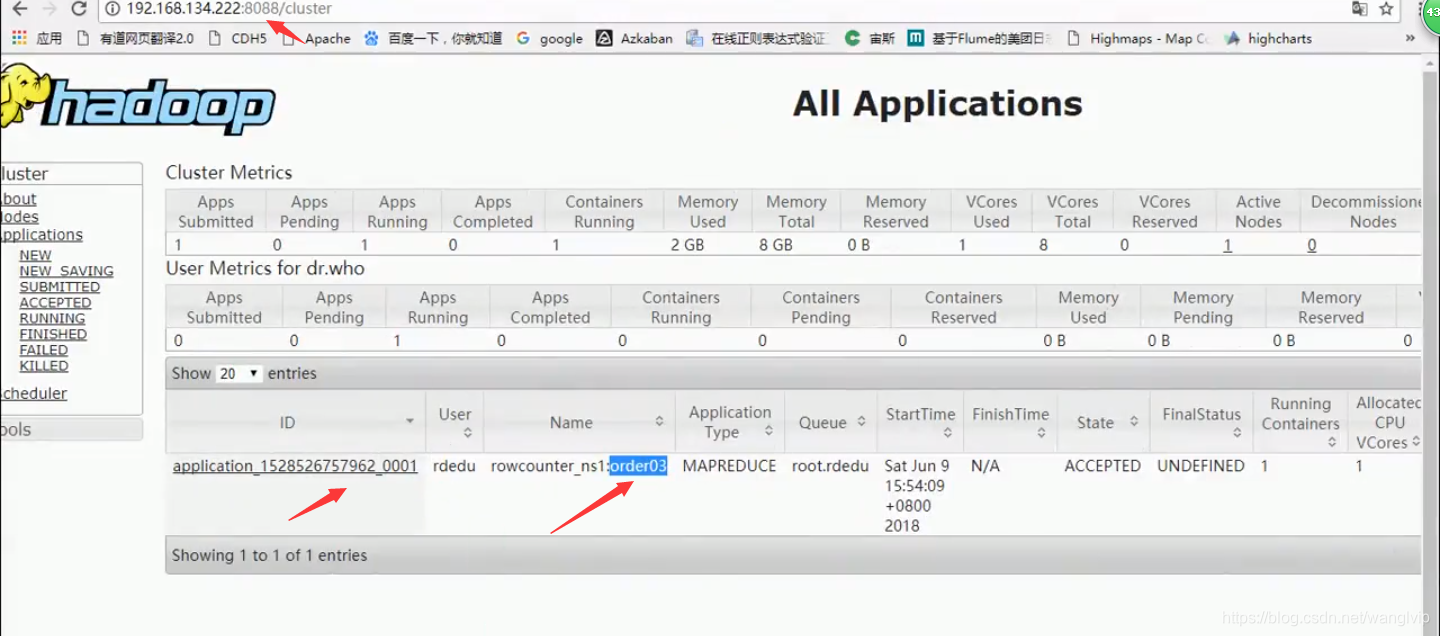
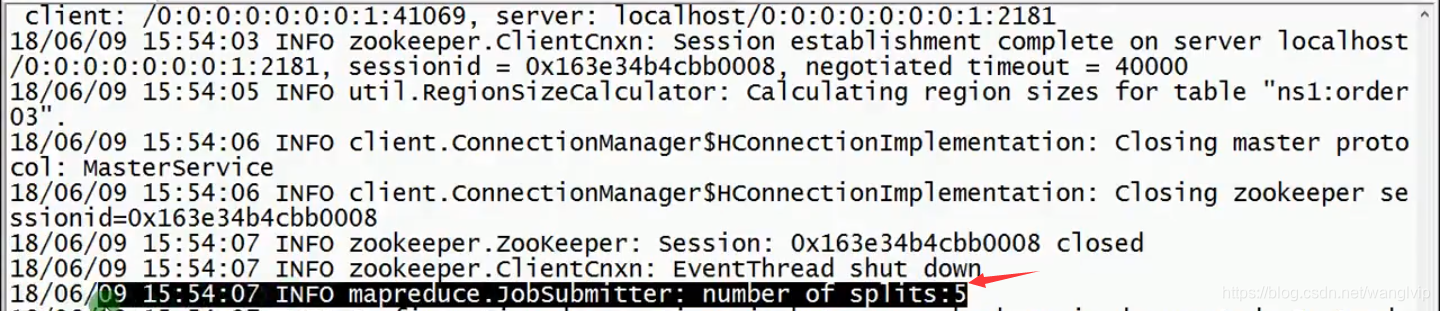
5个是region的个数:
三、importtsv: Import data in TSV format
hbase自带的MapReduce程序
小批量数据选择功能一
大批量数据选择功能二
功能一:用于将tsv(默认)文件内容导入hbase表
缺点:如果数据量过大:导致hbase负载,IO会很高
语法:Usage: importtsv
-Dimporttsv.columns=a,b,c
<tablename>
<inputdir>
示例:
bin/yarn jar /opt/cdh-5.7.6/hbase-1.2.0-cdh5.7.6/lib/
hbase-server-1.2.0-cdh5.7.6.jar
importtsv
-Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:age,info:sex –导入的列簇
ns2:import01 –导入的表名
/user/rdedu/import –导入表存放的目录
-》注意:
-》写入hbase时由什么类型变成字节类型,读出时就要将字节类型转换为原先的类型
>>比如String类型写进去,就得用String类型读出来
创建文件improt.tsv:
注意:每行用制表符(TAB键)隔开
![]()

创建表ns2:import01,info:

创建导入的存储表目录并put import.tsv文件
![]()
将tsv文件导入到HBase表中
bin/yarn
jar /opt/cdh-5.7.6/hbase-1.2.0-cdh5.7.6/lib/hbase-server-1.2.0-cdh5.7.6.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:age,info:sex ns2:import01 /user/rdedu/import
![]()
注意:这里操作只是导入、导出没有聚合操作,所以只有Map操作,没有Reduce操作
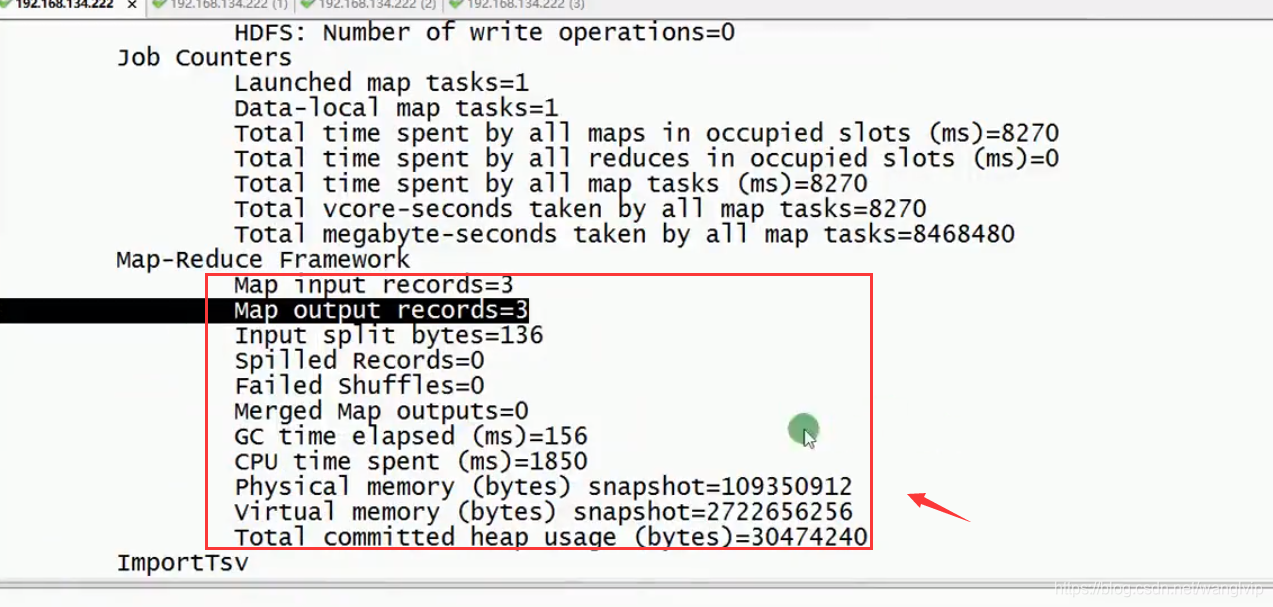
导入完成后验证数据:
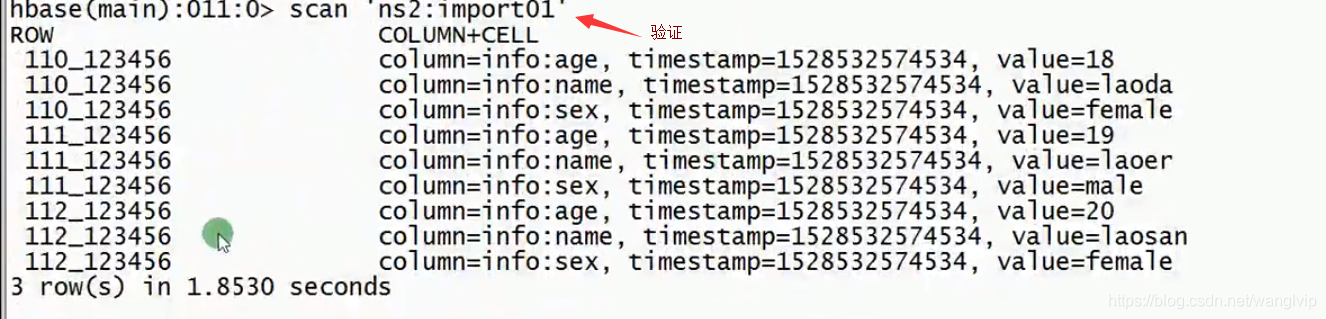
功能二:将tsv文件(默认)转换成HFILE(常用)
避免了功能一的缺点,直接将数据文件放到hdfs中去
HBase底层是HFILE文件,这样就可以将tsv文件转换成hfile文件放到HBase中
注意:hfile文件要与表中列簇一定要相同
将Hfile文件导入hbase表:适合于大数据量导入
**问题:不会将文件放如预选日志,因为都是放在wals并不是内存中,这样,wal并没有记录数据的
写入。如果写入产生问题的话就导致整个数据的丢失。
但是开发中并不影响,可以不写入wlas,或者可以修改配置文件的写入级别。
bin/yarn jar /opt/cdh-5.7.6/hbase-1.2.0-cdh5.7.6/lib/hbase-server-1.2.0-cdh5.7.6.jar
importtsv
-Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:age,info:sex
-Dimporttsv.bulk.output=/user/rdedu/output
ns2:import01
/user/rdedu/import
创建n2:imprort,info:

第一步:讲tsv文件转换为HFile文件
bin/yarn jar /opt/cdh-5.7.6/hbase-1.2.0-cdh5.7.6/lib/hbase-server-1.2.0-cdh5.7.6.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:age,info:sex -Dimporttsv.bulk.output=/user/rdedu/output ns2:import01 /user/rdedu/import
蓝框就是hfile文件:
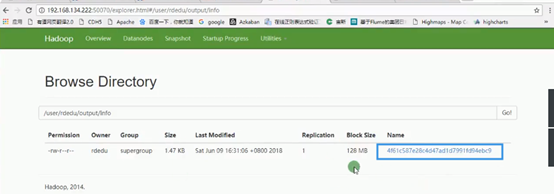
第二步:使用bulkload导入到hbase
语法:completebulkload /path/to/hfileoutputformat-output tablename
Hfile存放的文件夹 表名
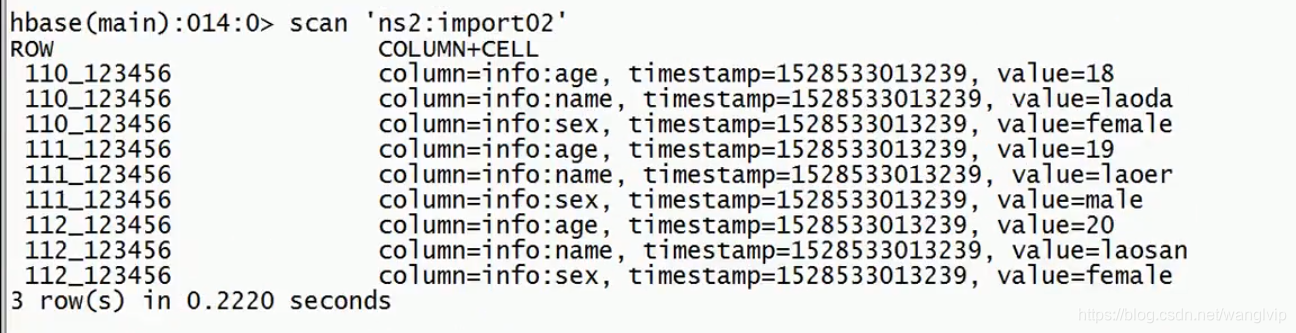
bin/yarn jar /opt/cdh-5.7.6/hbase-1.2.0-cdh5.7.6/lib/hbase-server-1.2.0-cdh5.7.6.jar completebulkload /user/rdedu/output ns2:import02
![]()
会连接zookeeper,向Zookeeper中注册表:
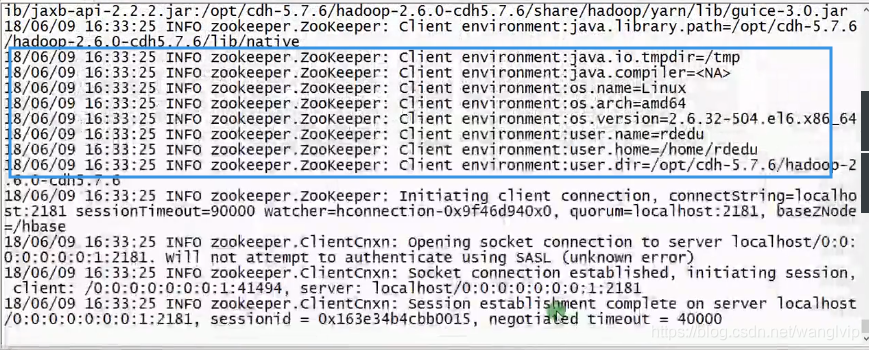
四、Hbase与MapReduce集成
详见代码需求:
-》从hbase中读,写入hbase
-》MapReduce
Driver类:
configuration conf = HbaseConfiguration.create()
TableMapReduceUtil.initTableMapperJob(
table, //从那张表读
scan, //使用哪个scan对象从表中读
mapper, //mapper类
outputKeyClass, //map的输出key
outputValueClass, //map的输出value
job);
TableMapReduceUtil.initTableReducerJob(
table,//输出到哪张表
reducer, //指定reduce的类
job);
Mapper类
extends TableMapper
keyin:ImmutableBytesWritable, rowkey
valuein:Result 一个rowkey对应的所有列
-》MapReduce默认一个region会启动一个map task进行处理
-》一个rowkey会调用一次map方法
Reduce类
extends TableReducer

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









