




在 RAG(检索增强生成)技术中,ANN 和 ANNOY 是解决「高效知识库检索」的核心工具
核心作用是快速从海量知识库中找到与用户问题最相关的信息片段(替代低效的全量匹配)
ANN:近似最近邻检索(Approximate Nearest Neighbor)
本质:
一种「检索技术思想」,而非具体工具
核心目标:
在海量高维数据(比如 RAG 中「知识库片段的向量」)中,快速找到与「查询向量(用户问题的向量)」最相似的 Top-K 个结果(即 “最近邻”)
关键特点:
「近似」而非「精确」—— 为了换取毫秒级的检索速度,牺牲极微小的召回精度(对 RAG 场景完全可接受)
传统的「精确最近邻(Exact Nearest Neighbor, ENN)」
ENN 会遍历所有数据计算相似度,在百万级数据量下速度极慢(秒级甚至分钟级),而 ANN 通过算法优化,能将速度提升到毫秒级,是 RAG 支持大规模知识库的核心前提
ANNOY:Approximate Nearest Neighbors Oh Yeah
本质:
ANN 技术的「具体开源实现工具」(由 Spotify 开发并开源),是一款轻量级、高效的近似最近邻检索库
核心定位:
专门用于解决「高维向量的快速相似性检索」,直接落地 ANN 的技术思想,可直接集成到 RAG 的检索模块中,替代传统的全量匹配或低效检索方案
为什么 RAG 必须用 ANN(及 ANNOY 这类工具)?
RAG 的检索环节,核心是「将用户问题和知识库片段都转换成向量,再通过向量相似度判断相关性」
但知识库规模一旦扩大(比如 100 万 + 文档片段),直接计算查询向量与所有文档向量的相似度(ENN)会极其耗时,导致检索延迟过高,无法满足实时问答需求。
ANN(及 ANNOY)的核心价值就是「解决高维向量的快速检索问题」,让 RAG 的检索环节从 “不可用” 变得 “可用”:
数据量:支持百万级、千万级甚至亿级文档片段的向量检索
速度:检索延迟控制在毫秒级(比 ENN 快 100~1000 倍)
精度:虽然是 “近似”,但召回率能达到 95% 以上(对 RAG 生成准确答案足够)
ANNOY 如何实现 ANN 检索?
ANNOY 的底层算法是「随机森林 + 树状索引」,原理可简化为 “分而治之”,步骤如下:
向量预处理(离线构建索引)
把 RAG 知识库中所有文档片段,通过编码器(如 BERT、Sentence-BERT)转换成高维向量(比如 768 维)
ANNOY 对这些向量构建「多棵随机二叉树」:每棵树的每个节点,都会随机选择一个维度和阈值,将向量分成左右两个子集(类似分类)
多棵树组合形成「索引结构」(可持久化存储到磁盘,后续直接加载使用),构建过程仅需执行一次(知识库更新时重新构建)
在线检索(快速匹配最近邻)
用户问题通过同一编码器转换成查询向量
ANNOY 拿着查询向量,遍历每棵二叉树:从树根开始,根据向量在节点维度上的值,选择左 / 右子树继续向下,最终到达每棵树的叶子节点(叶子节点包含少量向量)
收集所有叶子节点中的向量,计算它们与查询向量的精确相似度,筛选出 Top-K 个最相似的向量,对应到知识库中的文档片段 —— 这就是 RAG 需要的「相关信息」
ANNOY 的核心优势(适配 RAG 场景)
轻量级:代码量小、部署简单,无需复杂的分布式架构,单机即可支持百万级数据
速度快:树状索引 + 近似匹配,检索延迟极低,适合实时问答
支持增量更新:知识库新增文档时,可快速更新索引(无需全量重建)
跨语言 / 跨平台:支持 Python、C++ 等多种语言,适配 RAG 的各类技术栈
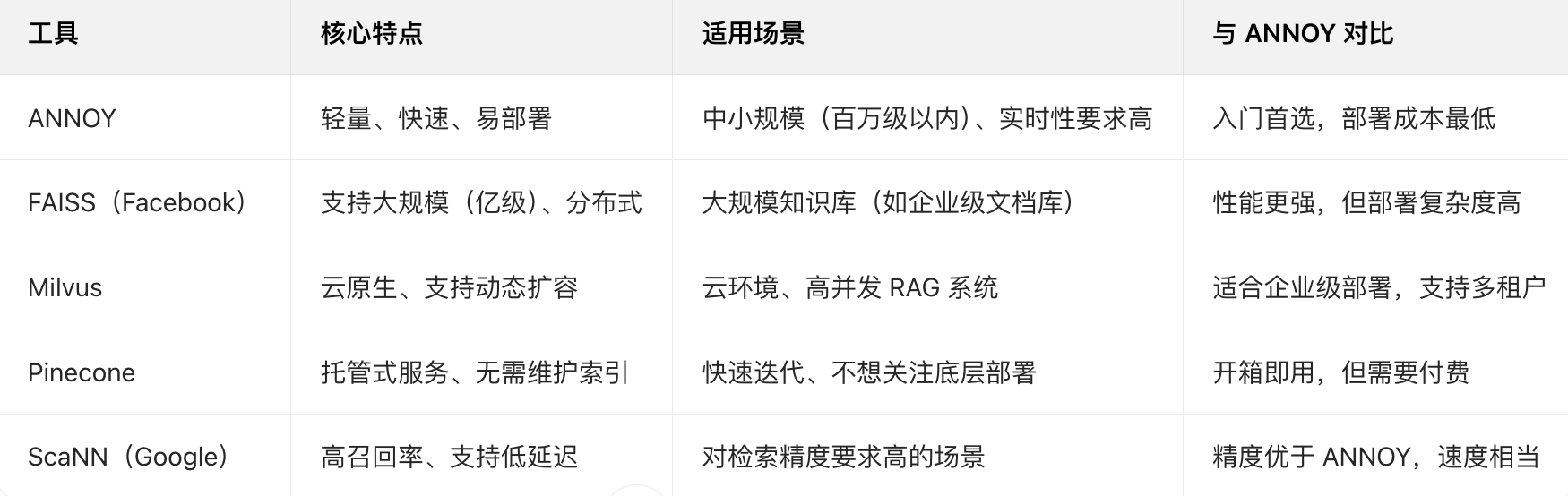
ANN 家族其他常见工具(与 ANNOY 对比)
ANNOY 是 ANN 的「轻量型选择」,RAG 场景中还有其他常用的 ANN 工具,可根据数据量和需求选择:
ANNOY 在 RAG 中的完整工作流程
离线准备(知识库构建):
- 拆分知识库:将长文档(如 PDF、Word)拆分成短片段(如每段 200 字),避免向量语义模糊
- 向量编码:用 Sentence-BERT 等编码器,将每个文档片段转换成高维向量
- 构建 ANNOY 索引:用 ANNOY 对所有向量构建索引,存储到本地或服务器
在线推理(用户问答):
- 用户提问:用户输入问题(如 “公司 2025 年年假政策是什么?”)
- 问题编码:将问题转换成与文档片段同维度的查询向量
- ANNOY 检索:用查询向量在 ANNOY 索引中快速检索,返回 Top-5~Top-10 个最相关的文档片段
- 生成答案:将「问题 + 检索到的相关片段」输入大模型,生成精准答案
核心总结
ANN:是 RAG 检索环节的「核心技术思想」(近似最近邻检索),解决了海量高维向量的快速匹配问题
ANNOY:是 ANN 思想的「轻量级实现工具」,由 Spotify 开源,适配 RAG 的中小规模场景,特点是快速、易部署、低成本
ANNOY 是 ANN 的 “子集”,是 RAG 中实现高效检索的「入门级首选工具」,更大规模场景可替换为 FAISS、Milvus 等
在 RAG 中,ANNOY(或其他 ANN 工具)就是「知识库的智能搜索引擎」,快速帮大模型找到 “答题需要的参考资料”,是 RAG 实现 “精准、实时、大规模” 问答的关键环节。
示例
在 RAG 的检索环节中,向量预处理(离线) 和 在线检索(实时) 是前后衔接的核心流程
前者是 “提前把知识库整理成可快速查找的格式”
后者是 “用户提问时,快速从整理好的知识库中找到相关信息”
二者共同解决了 “海量文档如何快速匹配用户问题” 的核心痛点
向量预处理:离线 “整理知识库”,为快速检索铺路
向量预处理是离线执行的(用户没提问时就做好)
核心目标是:
把原始的非结构化文档(如 PDF、Word、网页文本),转换成 “机器能快速计算相似度” 的高维向量
并构建索引结构,避免后续检索时 “逐字逐句遍历所有文档”
第一步:文档拆分(碎化知识库)
为什么要做?
长文档(比如一篇 1 万字的产品手册)直接转换成向量,会导致 “语义模糊”
向量无法精准代表文档的核心信息(比如用户问 “产品退款流程”,但长文档向量包含了功能介绍、售后政策等所有内容,无法聚焦)
就像图书馆整理书籍时,不会把一本厚书直接堆在架子上,而是按章节拆分后,给每个章节贴标签,方便快速查找。
怎么做?
把长文档拆分成 短文本片段(Chunk),常见拆分规则:
长度:每段 100~300 字(根据文档类型调整,比如技术文档可短些,散文可长些)
重叠:相邻片段保留 20%~30% 的重叠内容(比如第一段是 “1-200 字”,第二段是 “150-350 字”),避免拆分时割裂语义
工具:常用 LangChain、Haystack 等框架的 RecursiveCharacterTextSplitter 工具自动拆分
输出:一堆语义完整、长度适中的短文本片段(比如 10 万字的产品手册,拆成 500 个片段)
比如 “退款流程需先提交申请,审核通过后 3 个工作日到账”,不会被拆成 “退款流程需先提交申请” 和 “审核通过后 3 个工作日到账”
导致语义断裂
第二步:向量编码(把文本 “翻译成” 机器能懂的语言)
为什么要做?
计算机无法直接理解文本的语义(比如 “退款” 和 “退货” 的相关性),只能处理数值
向量编码就是把文本片段转换成 高维向量(比如 768 维、1024 维)
向量的 “距离” 代表语义的 “相似度”—— 两个向量越近,文本语义越相关
怎么做?
用 文本编码器(Embedding Model) 完成转换,核心要求是 “编码器能捕捉语义”:
常用编码器:
Sentence-BERT(开源首选,比如 all-MiniLM-L6-v2,轻量且效果好)
OpenAI Embeddings(闭源,精度高但付费)
ERNIE(百度开源,适配中文)
编码逻辑:
编码器会把文本中的关键词、语义逻辑映射到高维空间
(比如 “退款” 和 “退货” 的向量在空间中距离很近,“退款” 和 “登录” 的向量距离很远)
注意:
用户问题后续也要用同一个编码器编码,保证向量维度、语义映射规则一致
(就像中英文翻译要统一字典,不能一个用英汉词典,一个用法汉词典)
输出:
每个文本片段对应的高维向量(比如 500 个片段 → 500 个 768 维向量)
第三步:构建索引(给向量建 “快速查找目录”)
为什么要做?
如果不建索引,用户提问时,需要计算 “查询向量” 与所有 500 个(甚至百万个)文档向量的相似度
相当于在图书馆找书时,一本本翻遍所有书架,速度极慢(百万级数据下可能要几秒甚至几分钟)
索引就像图书馆的 “分类目录”(按主题、作者分类),能直接定位到目标书籍所在的区域,无需全量遍历
怎么做?
用前面提到的 ANN 工具(如 ANNOY、FAISS、Milvus) 构建索引,以 ANNOY 为例:
离线构建:
把所有文档向量输入 ANNOY,ANNOY 会用 “随机二叉树” 算法,把向量按语义相似度分组(比如 “退款流程”“售后政策” 相关的向量分到同一组),形成树状索引结构
索引存储:
把构建好的索引保存磁盘(比如 .ann 文件),后续在线检索直接加载,无需重构建(知识库更新时只需增量更新索引,不用全量重建)
输出:可持久化的向量索引文件(比如 knowledge_base.ann)
第四步:元数据关联(给向量 “贴标签”,方便溯源)
为什么要做?
检索后需要返回原始文本片段给大模型生成答案,还需要知道片段来自哪份文档、哪个章节(比如用户问 “退款流程”,返回的结果要标注 “来自《产品售后手册》第 3 章”,方便用户验证)。
怎么做?
给每个向量和对应的文本片段,添加元数据(键值对格式),常见元数据:
文档来源:{"source": "产品售后手册.pdf"}
章节 / 页码:{"chapter": "第 3 章", "page": 15}
片段 ID:{"chunk_id": "chunk_001"}(方便后续定位和更新)
输出:包含 “向量 + 文本片段 + 元数据” 的结构化知识库(比如存储在本地文件或数据库中)
向量预处理总结
核心动作:拆分 → 编码 → 建索引 → 关联元数据
核心目的:把 “不可快速检索的原始文档”,转换成 “可毫秒级检索的向量索引库”
执行时机:知识库初始化时执行一次,后续知识库更新(新增 / 删除文档)时,增量更新(只处理新增 / 删除的片段,不用全量重做)
在线检索:实时 “匹配用户问题”,找到相关信息
在线检索是用户提问时实时执行的
核心目标:把用户问题转换成向量后,快速从离线构建的向量索引库中,找到与问题语义最相关的 Top-K 个文本片段(比如 Top-5、Top-10),作为 “参考资料” 传给大模型
第一步:问题预处理(让问题更 “易匹配”)
为什么要做?
用户的提问可能不规范(比如口语化、冗余、歧义)
比如 “我想退掉上周买的产品,怎么操作呀?”,直接编码可能会因为冗余信息(“上周买的”“怎么操作呀”)影响匹配精度。
怎么做?
对用户问题做简单清洗和优化:
- 去冗余:删除口语化词汇(“呀”“呢”“其实”)、无关信息(“上周买的” 对 “退款流程” 查询无影响)
- 明确意图:把模糊问题转化为清晰查询(比如 “产品好像有问题,能退吗?” → “产品质量问题能否退款”)
工具:简单场景可手动写规则,复杂场景可用大模型做 “查询改写”(比如用 GPT-3.5 把用户问题改写为 “精准检索查询”)
输出:规范、清晰的查询文本(比如 “产品退款流程”)
第二步:问题编码(和预处理用同一个 “字典” 翻译)
为什么要做?
要和向量索引库中的向量做相似度计算,必须保证查询向量的维度、语义映射规则和文档向量一致
(比如预处理用了 Sentence-BERT 编码,这里也必须用同一个模型)
怎么做?
用和向量预处理阶段 完全相同的编码器,把规范后的查询文本转换成向量(比如 768 维向量)
输出:查询向量(比如 [0.123, 0.456, …, 0.789],共 768 个数值)
第三步:向量检索(快速找到 “最相关” 的片段)
为什么要做?
这是在线检索的核心,目的是在百万级向量中,毫秒级找到与查询向量最相似的 Top-K 个文档向量
怎么做?
加载离线构建的向量索引库,用 ANN 工具执行检索,以 ANNOY 为例:
- 加载索引:把磁盘上的 knowledge_base.ann 索引文件加载到内存
- 近似匹配:ANNOY 拿着查询向量,遍历树状索引,快速定位到语义相近的向量组(比如 “退款流程” 相关的向量组),无需遍历所有向量
- 精确排序:从匹配到的向量组中,计算查询向量与每个文档向量的 “余弦相似度”(常用相似度指标,取值范围 [-1,1],越接近 1 相似度越高),按相似度从高到低排序
- 筛选结果:取 Top-K 个(比如 Top-5)相似度最高的向量,对应的文本片段就是 “最相关的参考资料”(K 值可调整,K 太小可能漏关键信息,K 太大可能引入冗余信息,通常取 5~10)
- 输出:Top-K 个相关文本片段(含元数据,比如 “来自《产品售后手册》第 3 章”)
第四步:结果过滤(剔除 “无效信息”)
为什么要做?
近似检索可能返回一些低相似度的 “噪音片段”(比如相似度低于 0.5,语义关联度极低),如果直接传给大模型,会增加生成负担,甚至导致答案不准确。
怎么做?
设定相似度阈值(比如 0.5),剔除相似度低于阈值的片段;同时可过滤重复片段(比如多个片段内容高度一致,只保留一个)。
输出:经过筛选的、高相关的文本片段(比如 3~5 个片段)
在线检索总结
核心动作:问题预处理 → 问题编码 → 向量检索 → 结果过滤
核心目的:实时、快速地从海量知识库中,找到与用户问题最相关的 “参考资料”
关键指标:检索延迟(毫秒级)、召回率(能否找到所有相关片段)、精确率(找到的片段是否真的相关)
向量预处理与在线检索的衔接逻辑(完整流程串讲)
以 “用户查询‘公司 2025 年年假政策’” 为例,看两者如何配合:
离线预处理:
把《公司员工手册》(5 万字)拆成 200 个短片段(其中第 35 片段是 “2025 年年假政策:入职满 1 年可休 5 天,满 3 年可休 10 天”);
用 Sentence-BERT 把 200 个片段编码成 768 维向量;
用 ANNOY 构建向量索引,关联元数据(“第 35 片段 → 员工手册第 4 章”)
在线检索:
用户提问 “公司 2025 年年假政策”,预处理后变成规范查询 “2025 年年假政策”;
用同一个 Sentence-BERT 编码成查询向量;
ANNOY 加载索引,快速匹配到第 35 片段(相似度 0.85),以及另外 2 个相关片段(相似度 0.72、0.68);
过滤掉相似度低于 0.5 的片段,最终输出 3 个相关片段;
把 “用户问题 + 3 个相关片段” 传给大模型,生成精准答案
关键注意事项
编码器一致性:预处理和在线检索必须用同一个编码器,否则向量维度、语义映射不一致,无法计算相似度
片段长度合理:片段太长会导致语义模糊,太短会割裂语义,需根据文档类型调整
索引更新:知识库新增 / 删除文档时,要增量更新索引(比如新增 1 篇文档,只拆分、编码该文档的片段,添加到原有索引中),避免全量重建的耗时;
阈值调整:相似度阈值需根据实际场景调试(比如专业领域可提高阈值到 0.6,通用场景可降低到 0.4)
总结
向量预处理是 “提前搭好图书馆的分类目录”,在线检索是 “用户借书时,按目录快速找到想要的书”
两者配合,才能让 RAG 实现 “快速、精准” 的问答


















介绍&spm=1001.2101.3001.5002&articleId=154914051&d=1&t=3&u=fab83b2b435448cb8a57f287114fd087)
 132
132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









