






 给定一个整数n,返回2 x n棋盘上使用多米诺和托米诺形状进行平铺的不同方式数。返回答案模10^9 + 7。示例和约束见题面。
给定一个整数n,返回2 x n棋盘上使用多米诺和托米诺形状进行平铺的不同方式数。返回答案模10^9 + 7。示例和约束见题面。
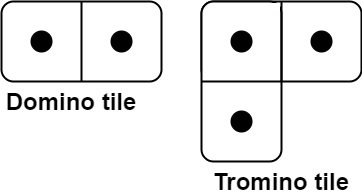
You have two types of tiles: a 2 x 1 domino shape and a tromino shape. You may rotate these shapes.
Given an integer n, return the number of ways to tile an 2 x n board. Since the answer may be very large, return it modulo 109 + 7.
In a tiling, every square must be covered by a tile. Two tilings are different if and only if there are two 4-directionally adjacent cells on the board such that exactly one of the tilings has both squares occupied by a tile.
Example 1:
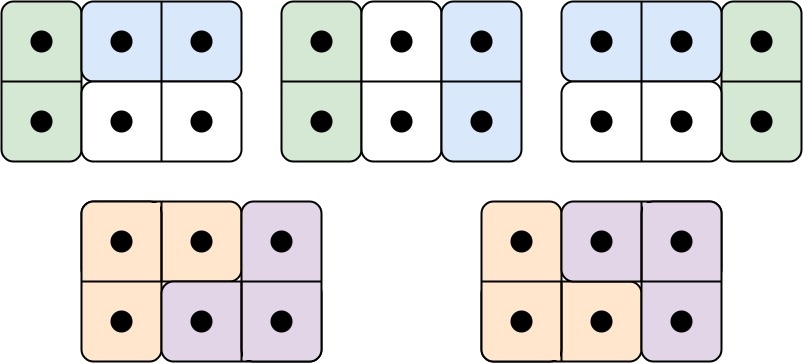
Input: n = 3
Output: 5
Explanation: The five different ways are show above.
Example 2:
Input: n = 1
Output: 1
Constraints:
- 1 <= n <= 1000
一个 board 我们从左往右排 tile, 分两种情况, 一种是排满,也就是是个严格的矩形, 另一种是部分排满,是一个矩形缺少右上角的一个方块或者右下角的一个方块。
假设 f(k)代表排满长度为 k 的 board 的排列方法的数量, p(k)代表部分排满长度为 k 的 board 的排列方法数量。这里要注意 p(k)当中的 k 要理解为缺一个角的矩形的长度,而不是多一个角的矩形的长度, 例如题中的 Tromino tile 它的长度是 2 而不是 1。还有要注意的是部分排满的情况我们只考虑缺右上角或者右下角的一种, 因为这两种情况是对称的
f(k) = f(k-1) + f(k-2) + 2 * p(k-1)
f(k)的情况可以从如下三种情况转换而来:
- f(k-1)再加一条竖着的 Domino tile
- f(k-2)加两条竖着的 Domino tile 或者加两条横着的 Domino tile
- p(k-1)加上对应的 Tromino tile, 因为有两种缺角情况所以乘以 2
impl Solution {
pub fn num_tilings(n: i32) -> i32 {
if n == 1 {
return 1;
}
if n == 2 {
return 2;
}
const M: i64 = 10i64.pow(9) + 7;
let mut f = vec![0i64; n as usize];
let mut p = vec![0i64; n as usize];
f[0] = 1;
f[1] = 2;
p[1] = 1;
for i in 2..n as usize {
f[i] = (f[i - 1] + f[i - 2] + 2 * p[i - 1]) % M;
p[i] = (p[i - 1] + f[i - 2]) % M;
}
*f.last().unwrap() as i32
}
}

















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









