




矩阵分解(Matrix Factorization)介绍
矩阵分解是一种常用的推荐系统技术,旨在通过将用户-物品评分矩阵分解为两个低维矩阵(用户特征矩阵和物品特征矩阵)来发现潜在的用户偏好和物品特性。这种方法能够有效处理稀疏数据,常用于协同过滤推荐系统。
基本原理
-
评分矩阵:通常是一个稀疏矩阵,其中行表示用户,列表示物品,元素表示用户对物品的评分。
-
分解:将评分矩阵 RR 分解为两个低维矩阵 U 和 V,使得:
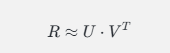
- U:用户特征矩阵,行数为用户数,列数为特征数。
- V:物品特征矩阵,行数为物品数,列数为特征数。
-
优化:通过最小化预测评分与实际评分之间的误差,使用梯度下降或其他优化算法来更新 U 和 V。
Python 代码示例
以下是一个使用 numpy 实现简单矩阵分解的示例。
安装依赖
确保安装了 numpy:
pip install numpy
示例代码
import numpy as np
# 示例评分矩阵(用户 x 物品)
R = np.array([[5, 3, 0, 1],
[4, 0, 0, 1],
[1, 1, 0, 5],
[1, 0, 0, 4],
[0, 1, 5, 4]])
# 参数设置
num_users, num_items = R.shape
num_features = 2 # 特征数
learning_rate = 0.01
num_iterations = 5000
lambda_reg = 0.02 # 正则化参数
# 随机初始化用户和物品特征矩阵
U = np.random.rand(num_users, num_features)
V = np.random.rand(num_items, num_features)
# 矩阵分解
for _ in range(num_iterations):
for i in range(num_users):
for j in range(num_items):
if R[i, j] > 0: # 仅对已评分的项进行更新
# 预测评分
prediction = np.dot(U[i, :], V[j, :].T)
# 计算误差
error = R[i, j] - prediction
# 更新用户和物品特征
U[i, :] += learning_rate * (error * V[j, :] - lambda_reg * U[i, :])
V[j, :] += learning_rate * (error * U[i, :] - lambda_reg * V[j, :])
# 预测评分矩阵
predicted_R = np.dot(U, V.T)
print("预测评分矩阵:\n", predicted_R)
# 为用户 0 推荐物品
user_id = 0
recommended_items = np.argsort(predicted_R[user_id])[::-1] # 按照预测评分降序排列
print("\n为用户 0 推荐的物品:\n", recommended_items)
Find More
代码解释
-
数据准备:创建一个简单的用户-物品评分矩阵 RR。
-
参数设置:
num_features:设置特征数。learning_rate:学习率用于梯度更新。num_iterations:迭代次数。lambda_reg:正则化参数,用于防止过拟合。
-
初始化:随机初始化用户特征矩阵 UU 和物品特征矩阵 VV。
-
矩阵分解:通过迭代更新 UU 和 VV:
- 对于每个用户和物品,如果用户对物品有评分,则计算预测评分和误差。
- 更新用户和物品特征矩阵。
-
预测评分:计算预测评分矩阵,并打印结果。
-
推荐物品:为指定用户(例如用户 0)推荐物品,根据预测评分降序排列。
总结
矩阵分解是一种强大的推荐系统技术,通过将用户-物品评分矩阵分解为低维特征矩阵,能够有效捕捉用户偏好和物品特性。以上示例展示了如何使用简单的矩阵分解方法实现推荐功能,实际应用中可以根据需求进行扩展和优化。




















 91
91

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











