



在已完成Hadoop伪分布式的前提下进行
1.准备工作
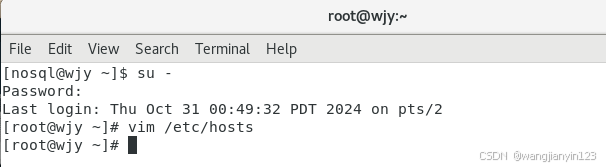
打开在虚拟机中进行命令的输入,进入root用户,"su -"命令。
查看此虚拟机的IP地址,"ifconfig"命令。查到我自己的IP地址是192.168.91.131
然后映射IP地址和主机名(注:克隆的IP地址是按原IP地址顺延的)
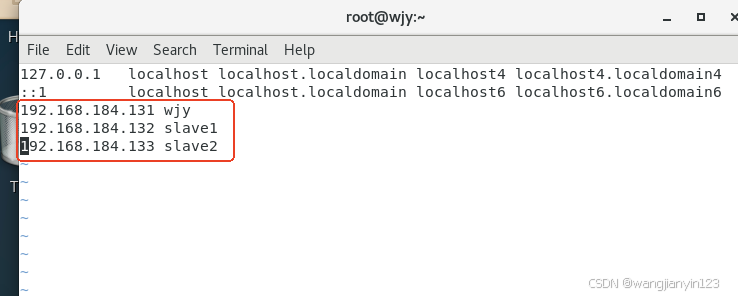
“vim /etc/hosts”命令在文件末尾添加如下内容:
192.168.91.131 xx(自己的IP地址 主机名)
192.168.91.132 slave1(克隆的第一台虚拟机IP地址 主机名)
192.168.91.133 slave2(克隆的第二台虚拟机IP地址 主机名)
2.在已配置好的虚拟机上,克隆出两台虚拟机(slave1和slave2)
在关机的状态下进行:虚拟机-->管理-->克隆-->下一页-->下一页-->完整克隆(注意:克隆的虚拟机安装路径要和原虚拟机处于同一路径下)
克隆出来后,做一个规放,在我的计算机处右击新建文件夹,然后把三个虚拟机都放在此文件下
3.更改克隆的IP地址
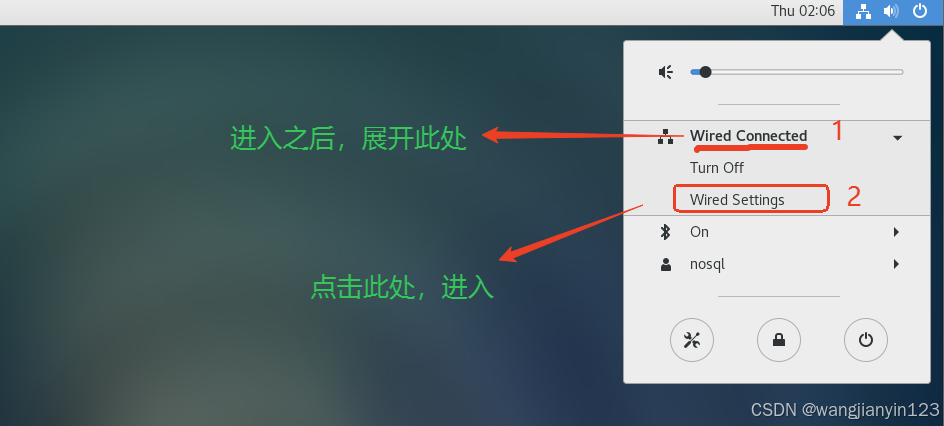
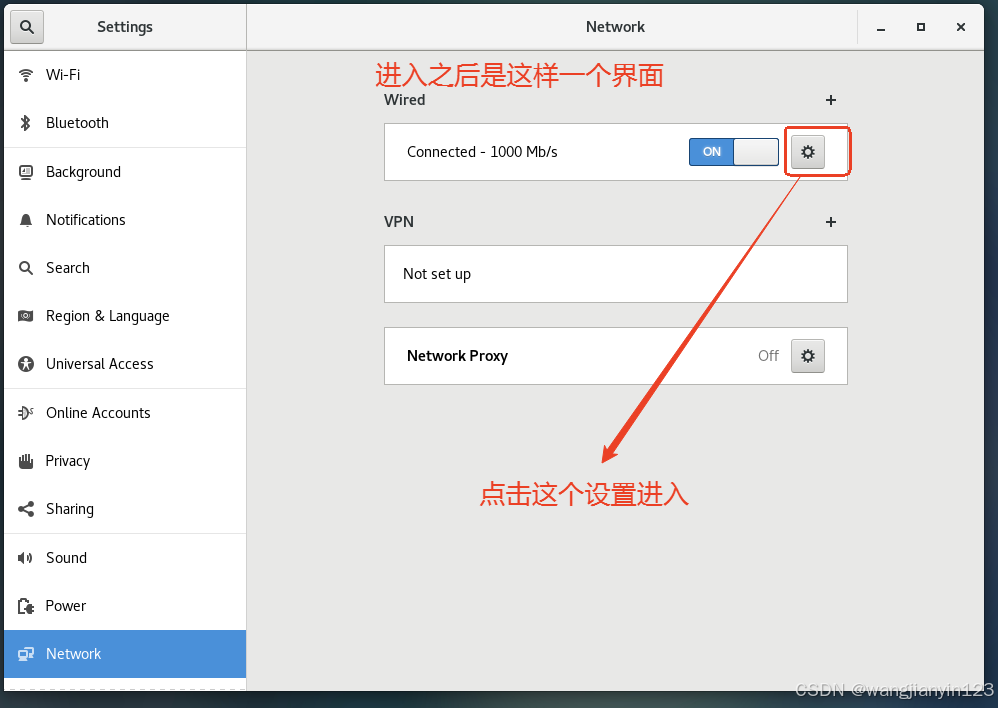
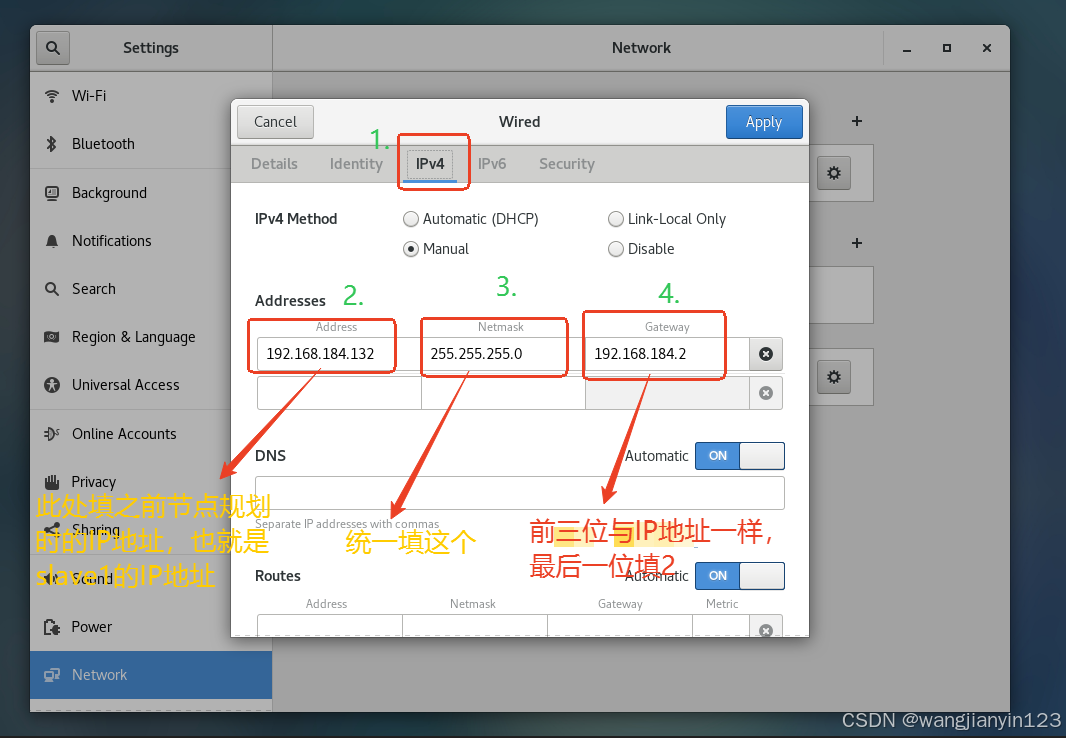
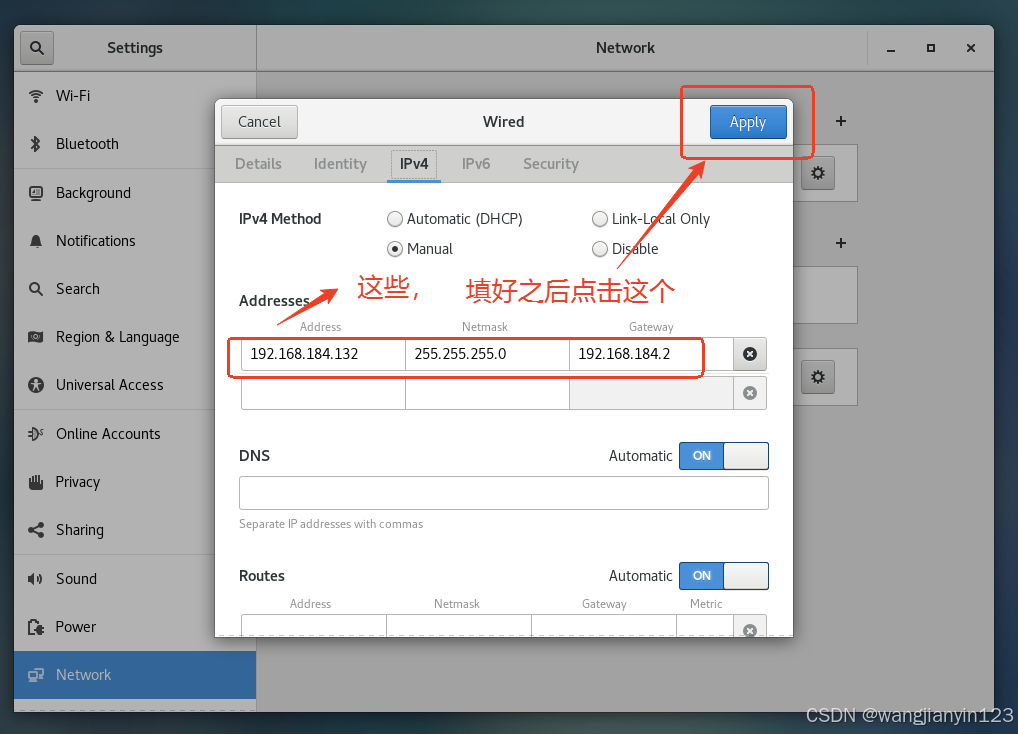
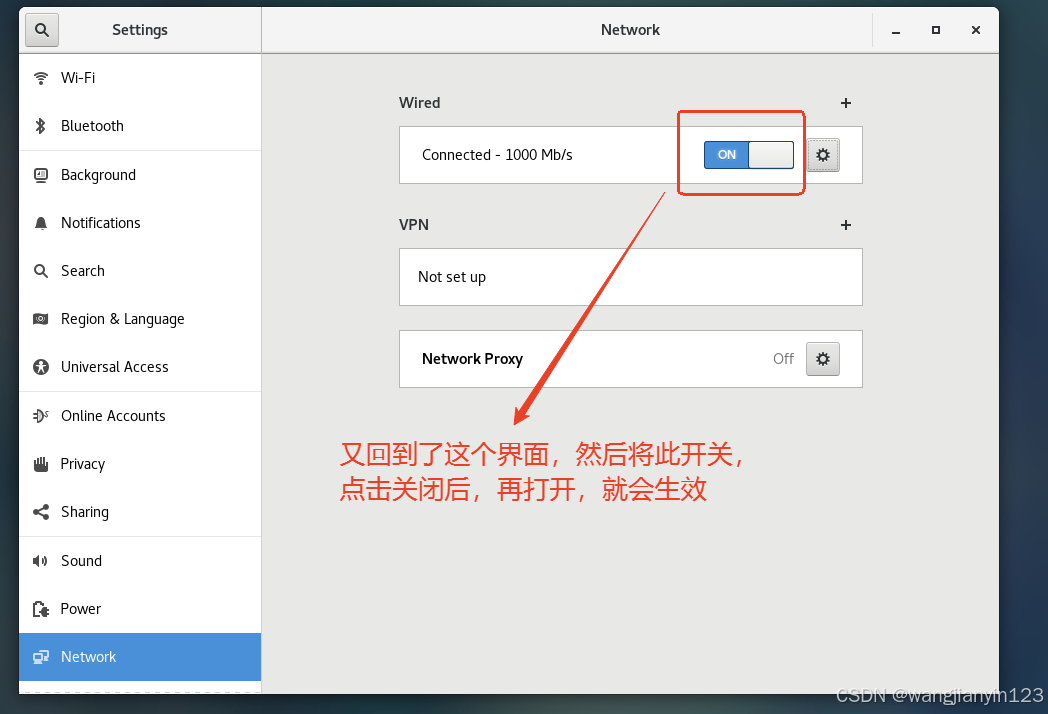
将克隆的两台虚拟机打开,进行更改IP地址,步骤如图:
现在先到slave1中进行如下操作:

4.更改主机名
IP地址改好之后,更改主机名
打开克隆出来的第一台主机(slave1),编辑/etc/hostname文件,输入命令
vim /etc/hostname
将原有内容删除,添加如下内容
slave1(注:主机名称)
输入命令“ reboot ”重启后生效
5.更改克隆出来的第二个虚拟机的IP地址和主机名
操作步骤和第一台的一样。
只是IP地址和主机名称改成slave2的 192.168.91.133
6. 设置SSH 无密码登录
1.在原虚拟机中进入root用户,然后输入命令“ cd ~/.ssh ”后,输入“ LL(小写) ”查看里面有没有内容,然后输入命令“ rm -rf * ”删除里面的内容,然后再输入LL查看是否删除掉。(每台主机都要做一次)
以下(2-5步)操作也是每台主机都要做
2.进入根目录下,命令 cd ~ ,然后再输入ssh-keygen -t rsa(一直回车)。
3.回车完成后。进入~/.ssh目录
cd ~/.ssh
4.依次输入命令,期间会输入yes
ssh-copy-id wjy (自己的主机名)
ssh-copy-id slave1 (克隆的第一台主机名)
ssh-copy-id slave2 (克隆的第二台主机名)
5.验证免密登录是否成功
ssh wjy
exit
ssh slave1
exit
ssh slave2
exit
7.通过FinalShell远程连接工具进行连接,以下操作都在finalshell中进行
1.连接之后,在原主机上输入命令
cd /export/server/hadoop/etc/hadoop/
2.然后更改配置文件
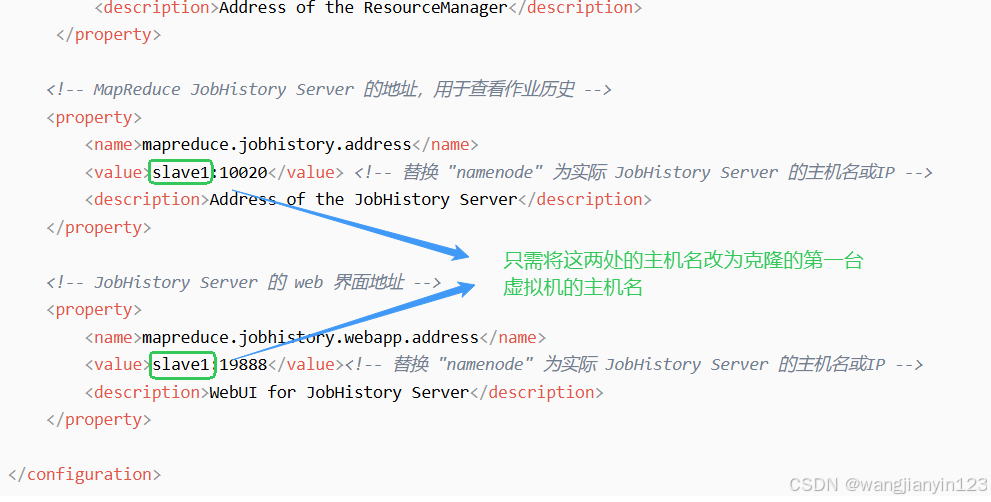
vim hdfs-site.xml

vim mapred-site.xml
3.设置 workers 文件
vim workers 进入后删除原有内容,添加以下内容:(千万注意,后面不要有空格,也不要有空行)
slave1
slave2
4.分发配置,分别输入以下命令
scp core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml hadoop-env.sh root@slave1:/export/server/hadoop/etc/hadoop/
scp core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml hadoop-env.sh root@slave2:/export/server/hadoop/etc/hadoop/
5.在主节点启动集群
start-all.sh
6.然后输入分别在主机,克隆的第一台机,第二台机输入 jps 查看进程,
主机会出现:
NameNode
ResourceManager
克隆的第一台机会出现:
NodeManager
DataNode
克隆的第二台机会出现:
NodeManager
DataNode
SecondaryNameNode
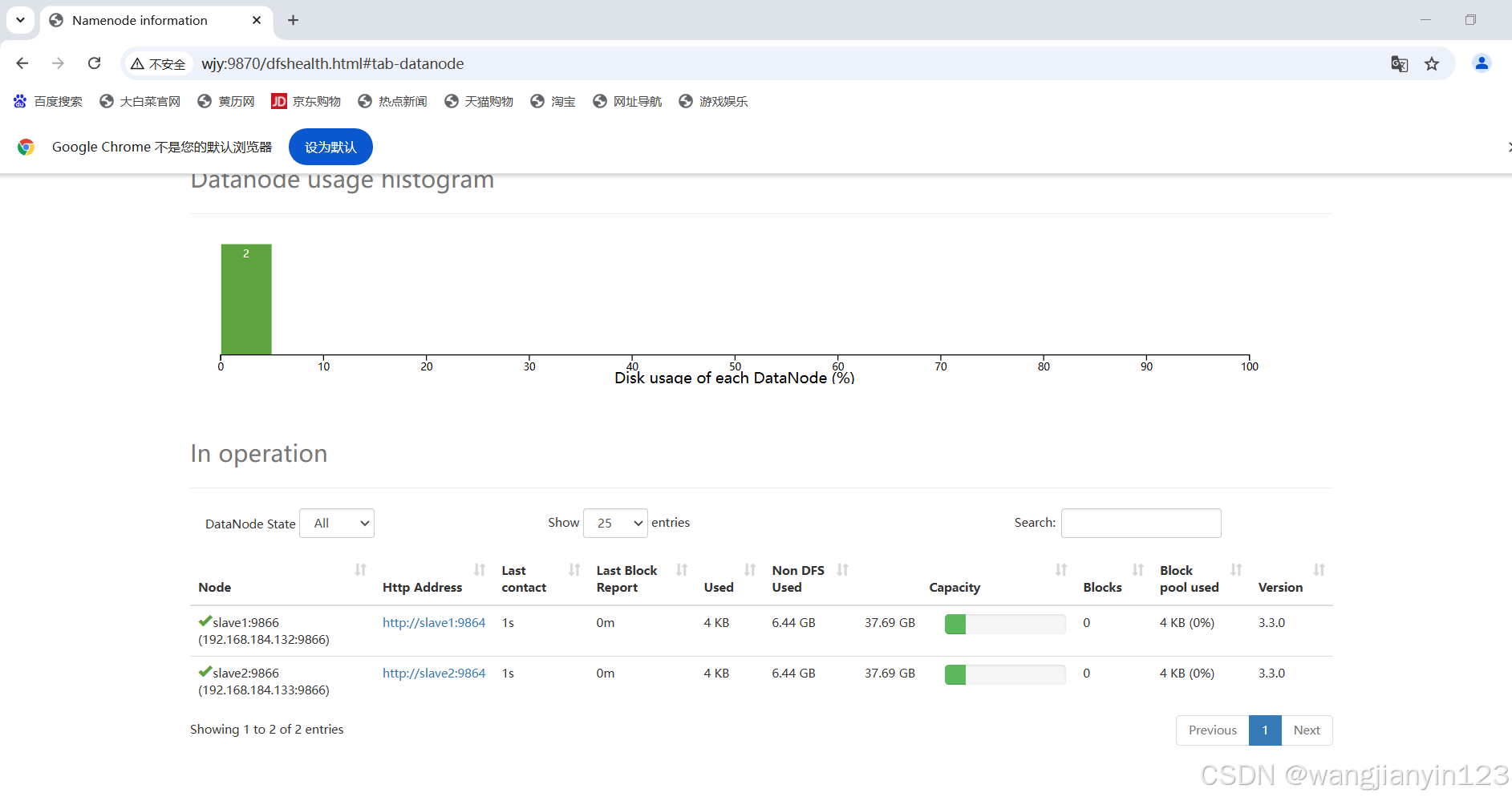
7.在网页界面http://wjy:9870中显示有两个DataNode(slave1、slave2)则成功。
假如只有一个,则在原主机上输入命令 stop-all.sh ,停止集群。
然后分别在克隆的第一台虚拟机机和第二台虚拟机中输入命令:
rm -rf /export/server/hadoop/dfs/data/*
然后再重新启动(start-all.sh),就会出现。

















 2557
2557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









