







 超级会员免费看
超级会员免费看
 这篇博客介绍了机器学习的基本概念,包括有监督学习、无监督学习、欠拟合和过拟合。重点讨论了如何形成模型、选择合适模型的方法,如K-Fold交叉验证,并详细解析了K-Nearest Neighbors (KNN) 分类器的工作原理、优缺点及其在不同K值下的模型复杂度和误差趋势。
这篇博客介绍了机器学习的基本概念,包括有监督学习、无监督学习、欠拟合和过拟合。重点讨论了如何形成模型、选择合适模型的方法,如K-Fold交叉验证,并详细解析了K-Nearest Neighbors (KNN) 分类器的工作原理、优缺点及其在不同K值下的模型复杂度和误差趋势。
目录
四、K-Nearest Neighbors (KNN) classifier(Tutorial内容)
一、什么是机器学习
1、过程:学习一组属性(或可通过数据整理获得的输入变量)与相关响应或目标变量之间的函数关系。
话句话说就是:从训练集中学习输入属性和目标值之间的功能或统计依赖性模型,然后,使用此模型对测试集上未见过的示例进行预测。
2、目的:
(1)预测:预测属性变量的任何(可能是新的)值的目标/响应值
(2)推理:理解目标变量随着输入变量的变化而受到影响的方式
3. 机器学习的模型:
(1)线性模型:

(2)非线性模型(多项式模型)
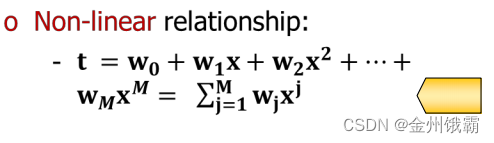

3、重要参数
(1)训练集
(2)测试集
(3)泛化性:测与训练集中使用的数据不同的新数据(或测试集)的目标的

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 525
525





 到【灌水乐园】发言
到【灌水乐园】发言









