







 本文分析了MySQL死锁的检测、隔离级别与锁的关系、成因,提出避免死锁的策略。通过wait-for graph算法理解死锁检测,探讨了主键和二级索引的锁行为,以及不同隔离级别下的幻读问题。建议固定访问顺序、拆分大事务、一次性锁定资源和降低隔离级别来预防死锁。
本文分析了MySQL死锁的检测、隔离级别与锁的关系、成因,提出避免死锁的策略。通过wait-for graph算法理解死锁检测,探讨了主键和二级索引的锁行为,以及不同隔离级别下的幻读问题。建议固定访问顺序、拆分大事务、一次性锁定资源和降低隔离级别来预防死锁。
线上某服务时不时报出如下异常(大约一天二十多次):“Deadlock found when trying to get lock;”。
Oh, My God! 是死锁问题。尽管报错不多,对性能目前看来也无太大影响,但还是需要解决,保不齐哪天成为性能瓶颈。
为了更系统的分析问题,本文将从死锁检测、索引隔离级别与锁的关系、死锁成因、问题定位这五个方面来展开讨论。
(想自学习编程的小伙伴请搜索圈T社区,更多行业相关资讯更有行业相关免费视频教程。完全免费哦!)
一、死锁是怎么被发现的?
1.1 死锁成因&&检测方法
左图那两辆车造成死锁了吗?不是!右图四辆车造成死锁了吗?是!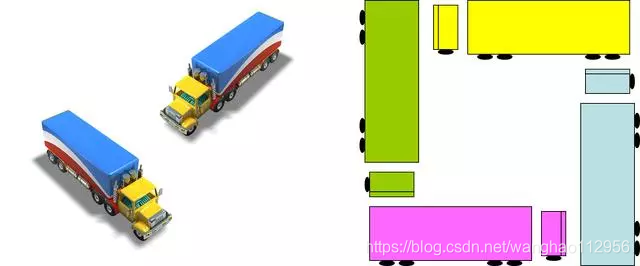
我们mysql用的存储引擎是innodb,从日志来看,innodb主动探知到死锁,并回滚了某一苦苦等待的事务。问题来了,innodb是怎么探知死锁的?
直观方法是在两个事务相互等待时,当一个等待时间超过设置的某一阀值时,对其中一个事务进行回滚,另一个事务就能继续执行。这种方法简单有效,在innodb中,参数innodb_lock_wait_timeout用来设置超时时间。
仅用上述方法来检测死锁太过被动,innodb还提供了wait-for graph算法来主动进行死锁检测,每当加锁请求无法立即满足需要并进入等待时,wait-for graph算法都会被触发
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









