







Spark 是一个分布式数据处理引擎,其各种组件在一个集群上协同工作,下面是各个组件之间的关系图。
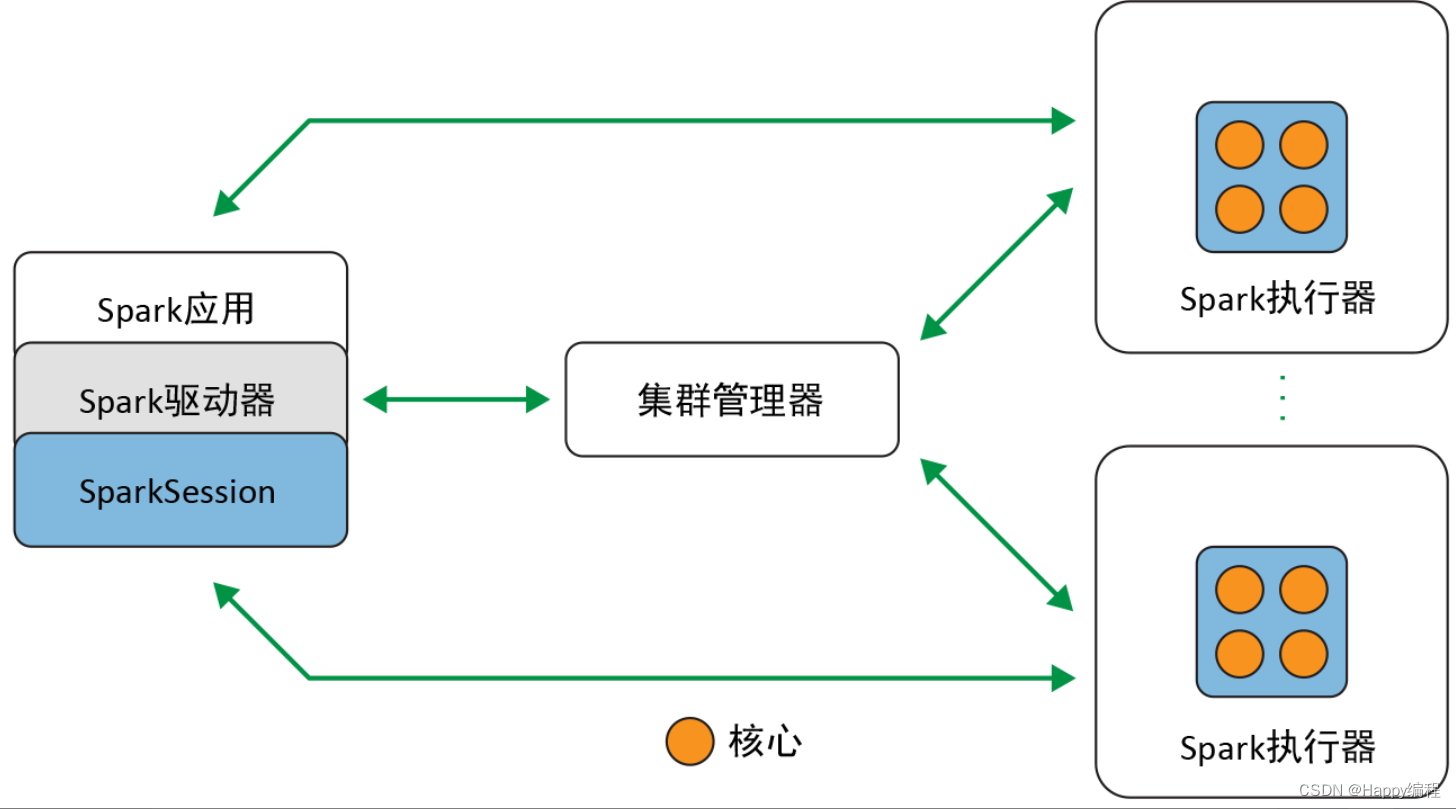
Spark驱动器
作为 Spark 应用中负责初始化 SparkSession 的部分,Spark 驱动器扮演着多个角色:它与集群管理器打交道;它向集群管理器申请 Spark 执行器(JVM)所需要的资源(CPU、内存等);它还会将所有的 Spark 操作转换为 DAG 运算,并负责调度,还要将这些计算分成任务分发到 Spark 执行器上。一旦资源分配完成,创建好执行器后,驱动器就会直接与执行器通信。
SparkSession
在 Spark 2.0 中,SparkSession 是所有 Spark 操作和数据的统一入口。它不仅封装了 Spark 程序之前的各种入口(如 SparkContext、SQLContext、HiveContext、S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4761
4761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











