



一、YOLOv5 原理
yolo系列的检测网络是典型的one-stage网络。YOLOv5的网络结构如下图。
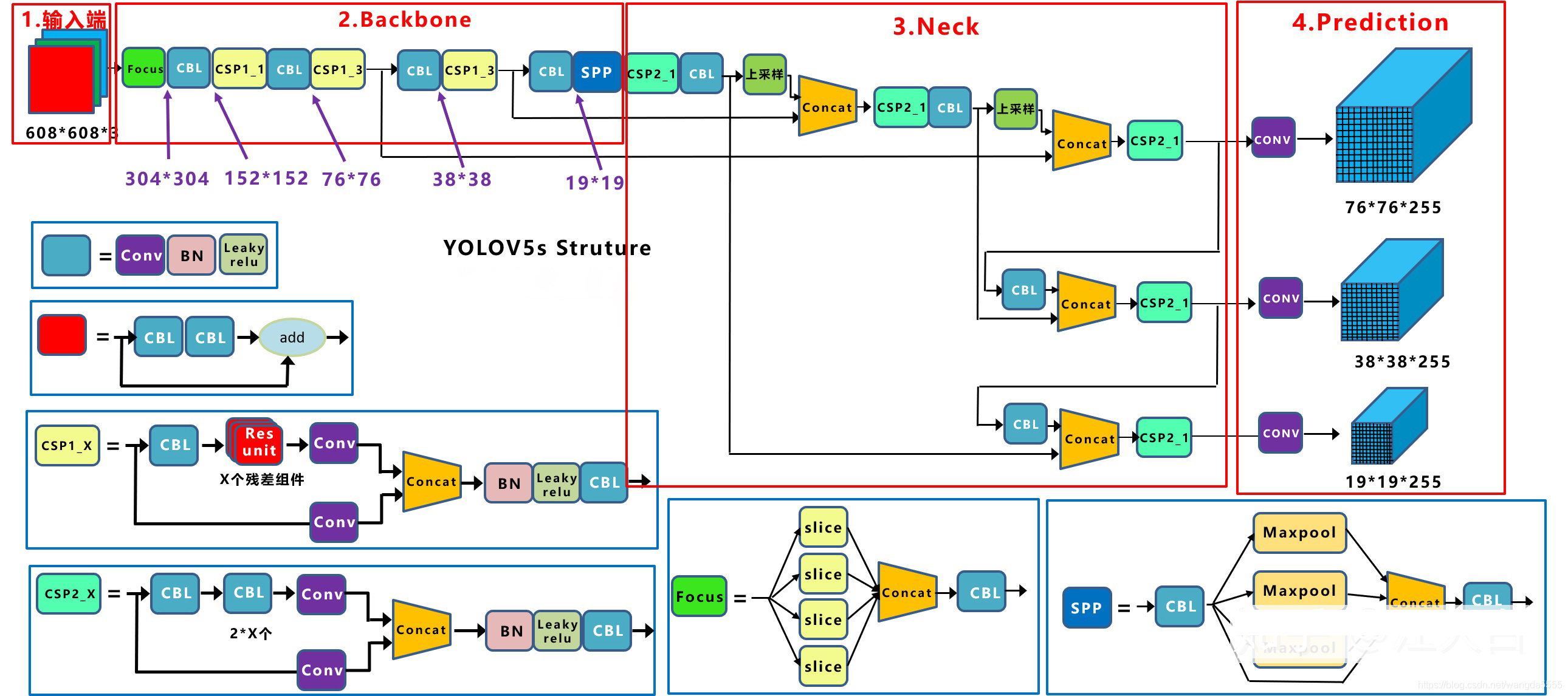
上图中给出的为yolov5s的网络结构,还有三种:yolov5m、yolov5l、yolov5x。这四种网络只是网络的深度和宽度有所不同,其中yolov5s是参数最少的结构。
目标检测网络一般分为输入端、Backbone、Neck、Prediction四个部分。接下来依次介绍一下yolov5的这四个部分。
1.输入端
采取Mosaic数据增强方式、自适应anchor计算、自适应图片缩放。
(1)Mosaic数据增强方式:是Yolov4中使用的,其受CutMix数据增强的启发,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。示意图如下。
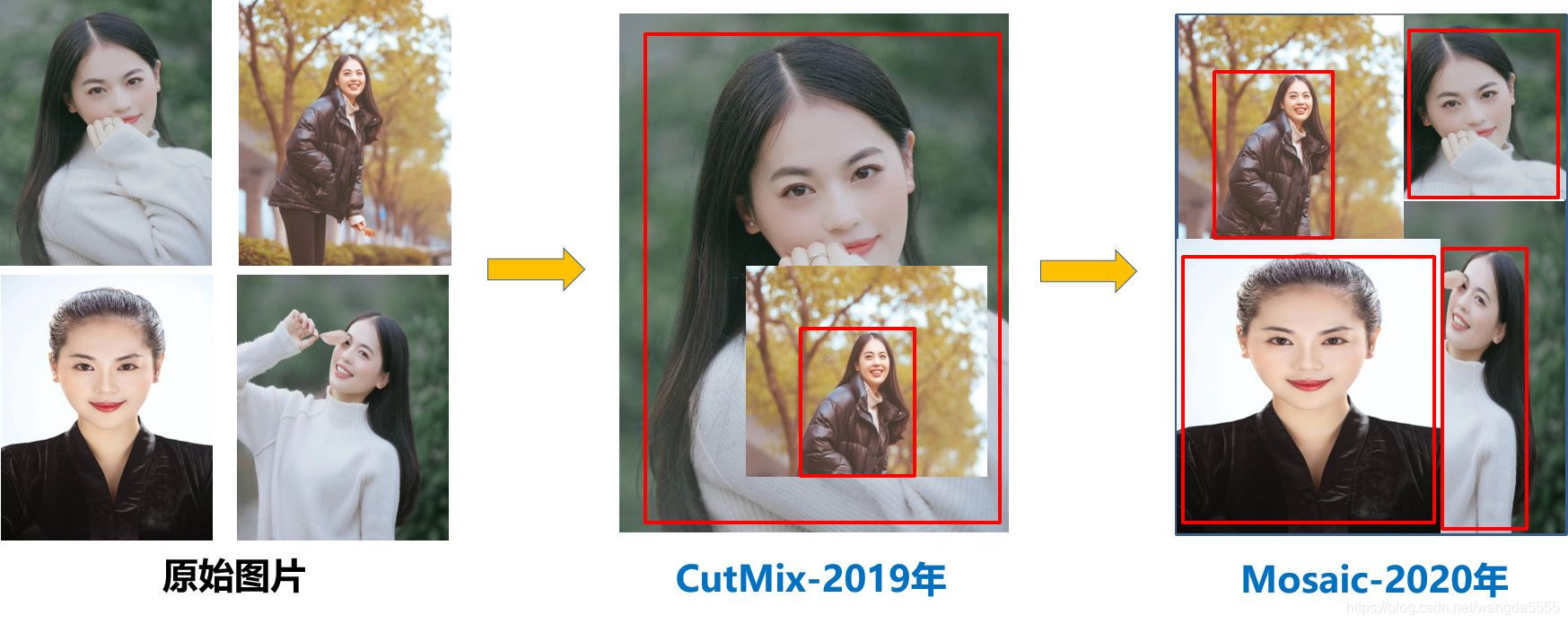
使用Mosaic数据增强方式可以大大丰富数据集,并且可以增加很多小目标(拼接成一张图像会使原图的目标变小)。
(2)自适应anchor计算:在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框进行比对,计算两者差距,再反向更新,迭代网络参数。Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。(通过k-means聚类得到先验框)
(3)自适应图片缩放:针对不同的目标检测算法而言,通常需要执行图片缩放操作,即将原始的输入图片缩放到一个固定的尺寸,再将其送入检测网络中。YOLO系列算法中常用的尺寸包括416*416,608 *608等尺寸。原始的缩放方法存在着一些问题,由于在实际的使用中的很多图片的长宽比不同,因此缩放填充之后,两端的黑边大小都不相同,然而如果填充的过多,则会存在大量的信息冗余,从而影响整个算法的推理速度。为了进一步提升YOLOv5算法的推理速度,提出一种方法能够自适应的添加最少的黑边到缩放之后的图片中。该操作仅在模型推理阶段执行。
2.Backbone
yolov5在Backbone中使用了focus结构和CSP结构。其中CSP结构如网络结构图所示。focus结构如下所示。
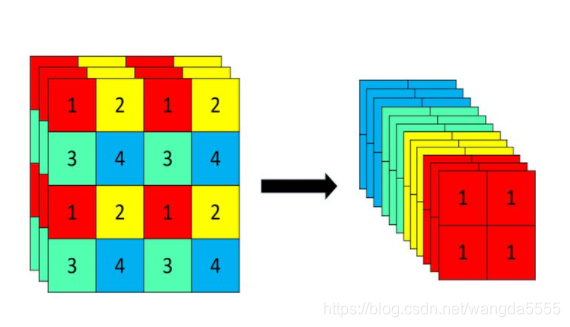
输入为608*608*3,经过focus结构后变为304*304*12.Focus模块可以提高每个点感受野,并减少原始信息的丢失,该模块的设计主要是减少计算量加快速度。
3.Neck
yolov5在Neck仍然采用FPN(特征金字塔网络,后面卷积层经过上采样与前面的层concate,从而提升网络的多尺度检测能力)
4.Prediction
Yolov5中采用其中的GIOU_Loss做Bounding box的损失函数。此外,将nms中IOU修改成DIOU_nms。对于一些遮挡重叠的目标,会有一些改进。
二、YOLOv5总结
YOLOv5的优势:
- 使用PyTorch进行编写。https://github.com/ultralytics/yolov5
- 可以轻松编译成ONNX和CoreML。
- 体积小,速度极快,精度高。。
- 集成了YOLOv3-spp和YOLOv4部分特性。


















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









