



1. 进程简介
进程是程序的一次运行活动,不仅包括代码本身,还涉及程序运行时所需的资源(如内存、文件句柄、CPU时间等)。总结来说,进程 = 内核数据结构对象 + 自己的代码和数据。
运行一个程序,操作系统会使用一个struct结构体对该程序进行描述,记录该进程的一系列信息,这个结构体就是该进程的内核数据结构对象,程序在执行时,内存会从磁盘上将代码和数据拷贝到内存中,这部分就是自己的代码和数据。

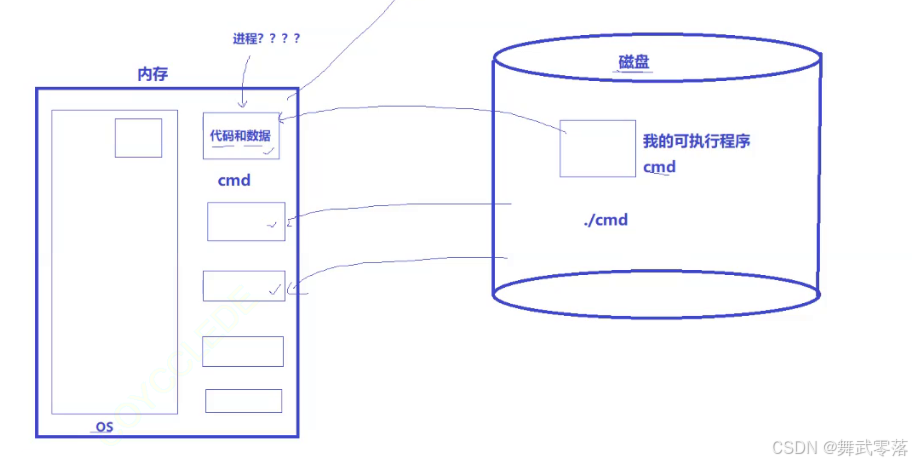
(1)进程的基本概念
课本概念:程序的一个执行实例,正在执行的程序等
内核观点:担当分配系统资源(CPU时间,内存)的实体。
(2)进程的基本操作
1. 创建进程:通过系统调用(如 fork)生成新的进程。
2. 查看进程:使用工具(如ps、top)获取系统中所有活跃进程的信息。
3. 终止进程:通过信号或系统调用(如 kill)结束一个进程。
2.PCB与task_struct
2.1.描述进程的PCB(Process Control Block)
进程控制块(PCB)是操作系统中用于描述进程的关键数据结构。它如同进程的“身份证”,记录了进程的核心信息,包括:
- 进程标识符(PID):唯一编号,便于区分不同进程。
- 进程状态:运行、等待、就绪等。
- CPU寄存器内容:记录进程切换时的上下文信息。
- 内存地址:进程代码段、数据段、堆栈段的位置。
PCB就是上面介绍的内核数据结构对象:

我们通过 PCB 结构体来描述进程的代码和数据,该结构体中包含指针以将各个进程连接起来。因此,对进程的管理就变成了对进程链表的增、删、查、改操作。
可以说,PCB是进程的档案袋,里面装满了进程的身份信息和工作记录。
2.2.Linux中的task_struct
在Linux中描述进程的结构体叫做 task_struct,用来管理进程的核心数据结构。它包含了与进程相关的所有信息:
- 进程ID
- 进程状态
- 优先级
- 内存信息
- 打开的文件描述符表
...
进程的所有属性都可以直接或间接通过tast_struct找到。
通过内核源码,可以查看task_struct定义:
struct task_struct {
pid_t pid; // 进程ID
long state; // 进程状态
struct mm_struct *mm; // 内存信息
struct files_struct *files; // 打开的文件信息
...
};
在linux中 task_struct 就是内核数据结构对象:

3.通过系统调用获取进程标识符
我们执行的所有指令、工具、自己的程序,运行起来全部都是进程。
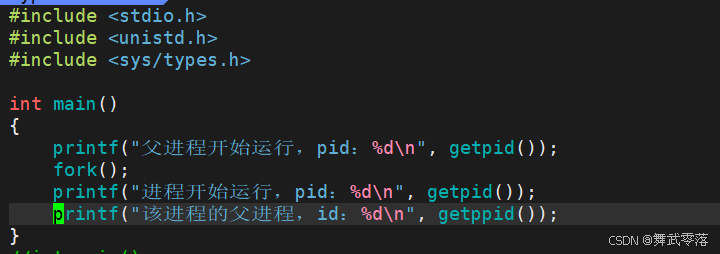
3.1.getpid()
getpid是 Linux 中的一个系统调用,用于获取当前进程的进程 ID (PID)
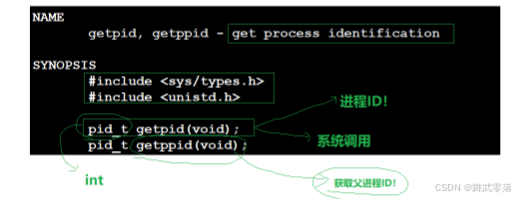
3.2.getppid()
getppid用于获取当前进程父进程ID (PPID)
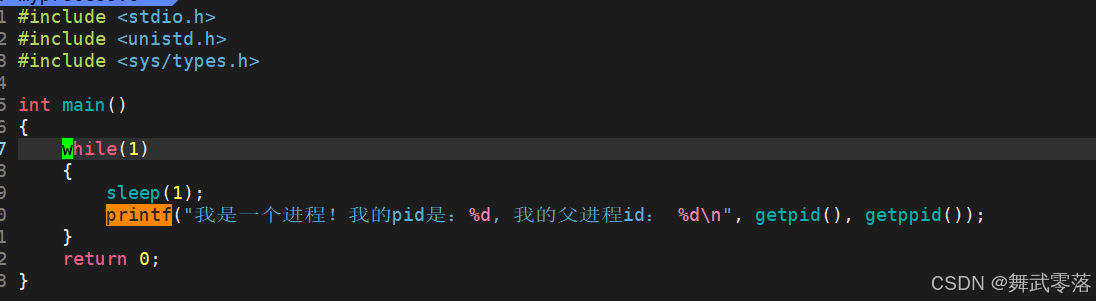
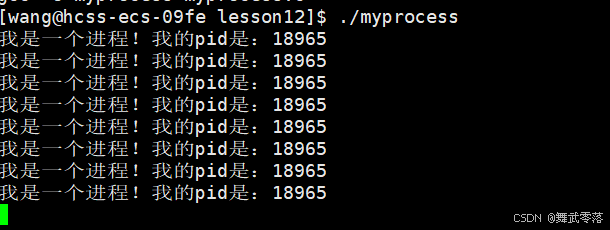
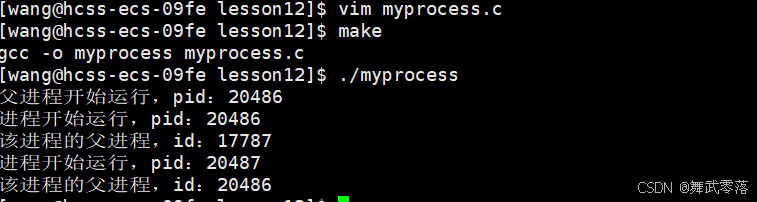
运行程序
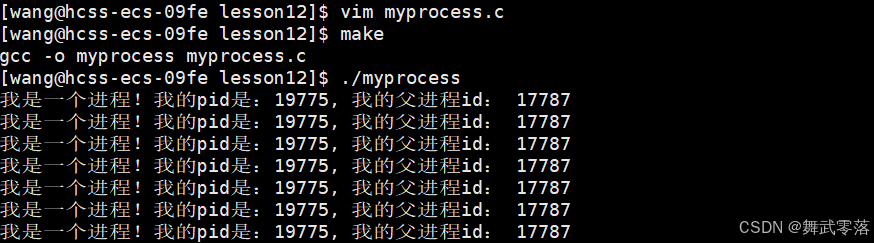
 通过上面的结果,我们发现子进程的id一直在变化,而父进程的id不变。
通过上面的结果,我们发现子进程的id一直在变化,而父进程的id不变。
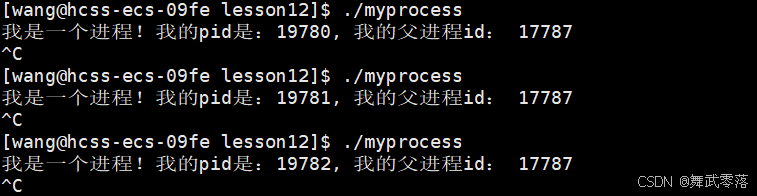
我们通过 ps ajx | head -1 && ps ajx | grep 17787 | grep -v grep 查看父进程

发现父进程是一个bash(命令行解释器),所以说bash也是一个进程。
4. 如何查看进程?
查看进程是操作系统管理的重要环节。在Linux中,可以使用多种工具查看和监控进程:
- ps命令:列出系统中所有运行的进程。
- top命令:动态显示进程的实时运行状态。
- htop工具:功能强大的交互式进程管理工具。
4.1.ps命令
(1)ps axj命令用于显示当前所有正在运行的进程的详细信息。下面是其中一部分的截图
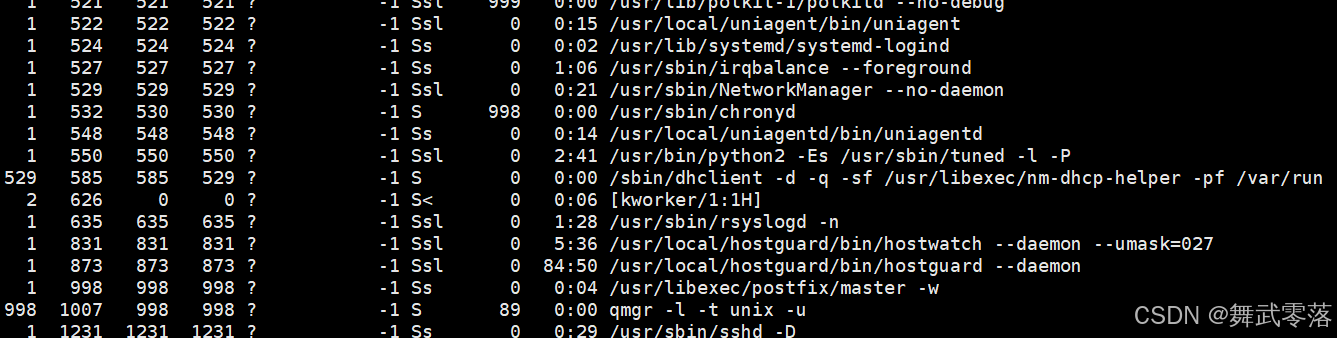
(2)ps axj | grep process查看指定进程
ps axj:列出系统中所有进程的详细信息
|:将前一个命令的输出作为后一个命令的输入
grep process:过滤出包含 “process” 字符串的行
当myprocess程序正在运行时:

grep也是一个进程,因此显示两个进程。
显示进程信息第一行
![]()
; 和 && 都用于在同一行中分隔多个命令。
不同点在于使用'; ',shell 会按照从左到右的顺序依次执行这些命令,无论前一个命令执行成功(返回状态码为 0)还是失败(返回非零状态码),后续命令都会继续执行。
而 && 存在逻辑判断机制。shell 会按顺序执行命令,只有当前一个命令成功执行(返回状态码为 0)时,才会继续执行后续命令。


(3)隐藏grep进程
4.2.ls命令
ls /proc同样可以用来查看进程,proc目录里记录当前系统里所有进程的信息,每一个数字目录代表特定进程的pid,内容包含该进程在运行时的的动态属性,一旦退出该目录会被系统自动移除
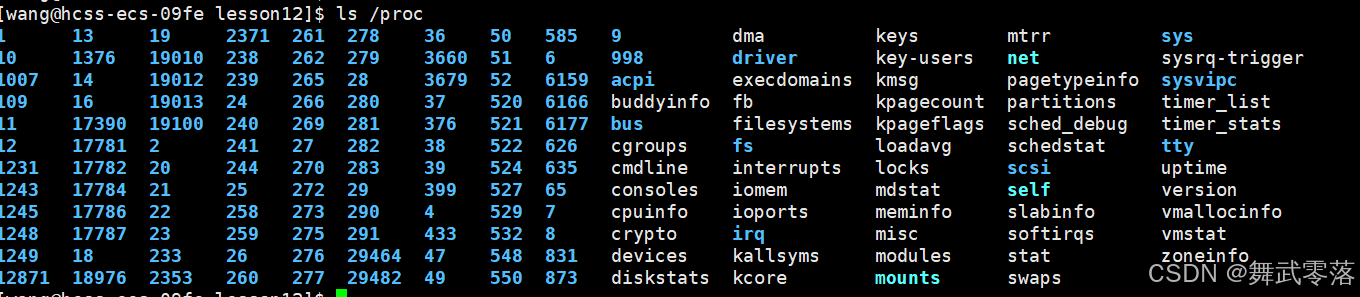
当下面程序运行时:

我们可以通过pid查到该进程
![]()
杀死该进程后则无法查到

4.3.杀掉进程
(1)ctrl + c
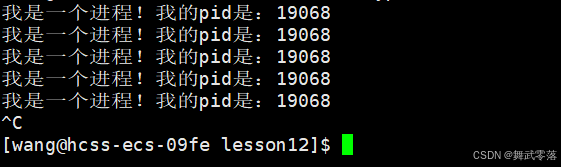
(2)kill -9 pid
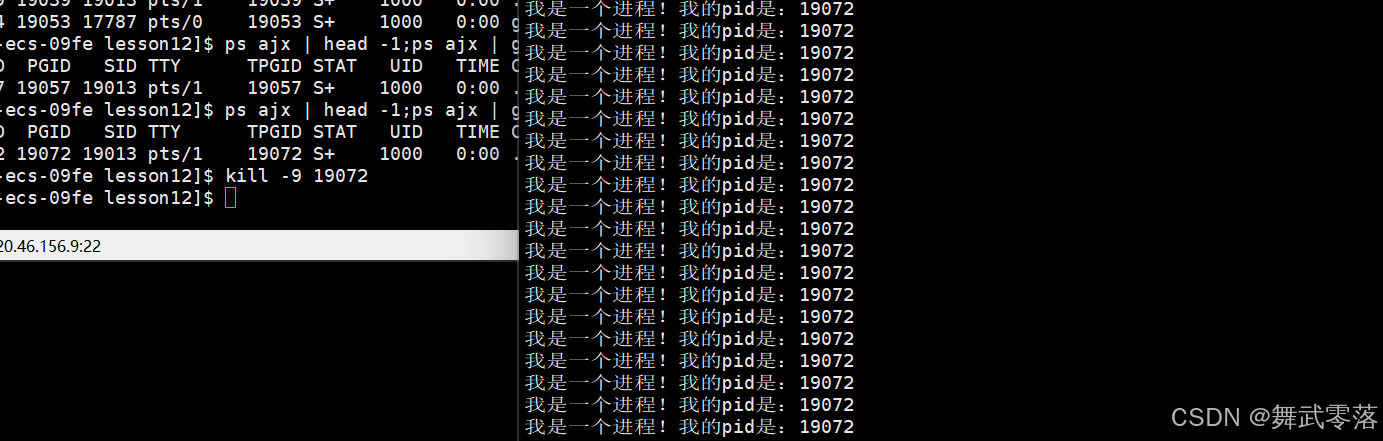
4.4.查看进程的属性
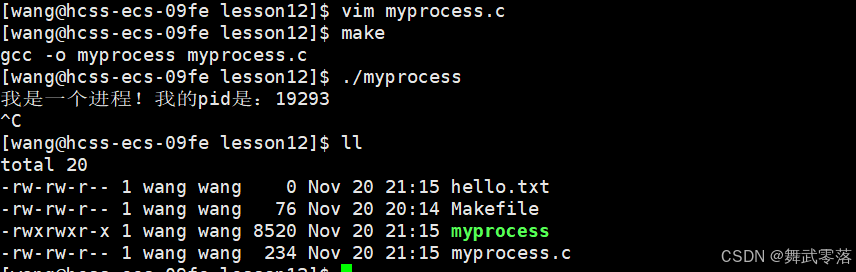
ls /proc/pid
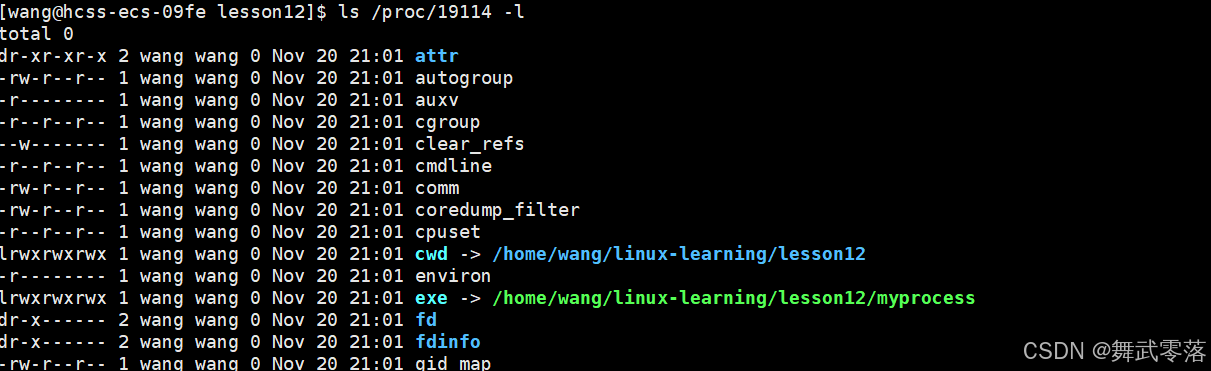
(1)cwd是当前目录,这说明进程会记录下自己的当前路径。
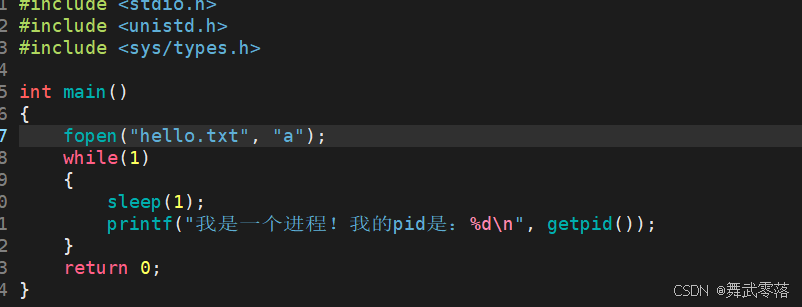
我们在文件中使用fopen,在运行程序可以发现,当前目录下新建了一个文件hello.txt
使用chdir改变文件所在目录

文件被创建在了指定路径下
查看进程属性可以发现,进程所在目录为我们所指定目录
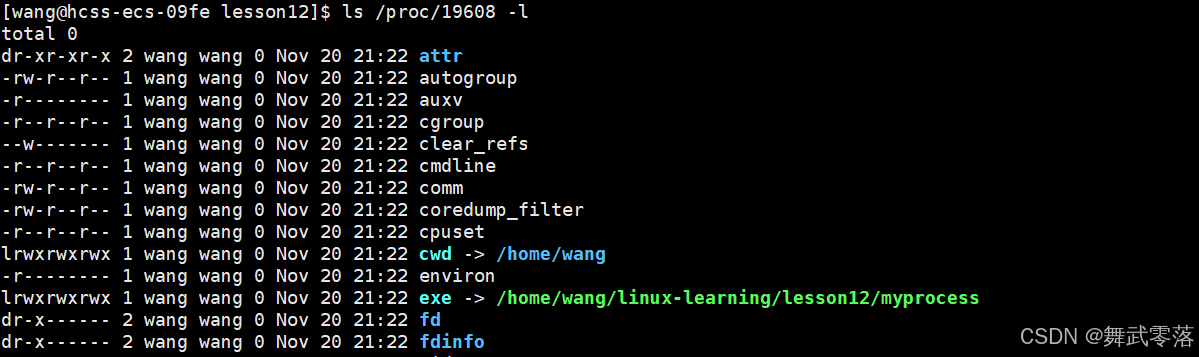
(2)exe是进程所对应的可执行文件
我们将这个文件删除 ,如果程序正在运行中,则程序不会终止,因为我们删除的是磁盘上对应的文件,而进程启动时,该进程的拷贝已经到内存了。
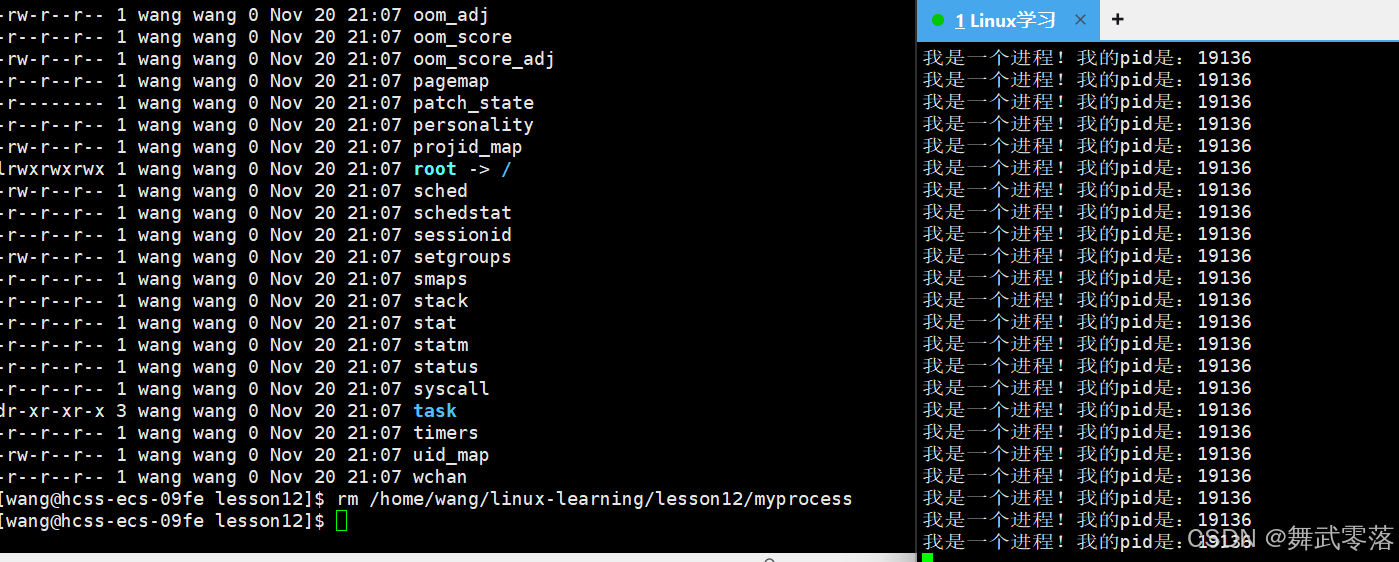
此时我们再来查当前进程的属性:

5.通过系统调用创建进程-fork初识
fork() 是Linux中创建新进程的核心系统调用。它通过复制当前进程,生成一个新的子进程。
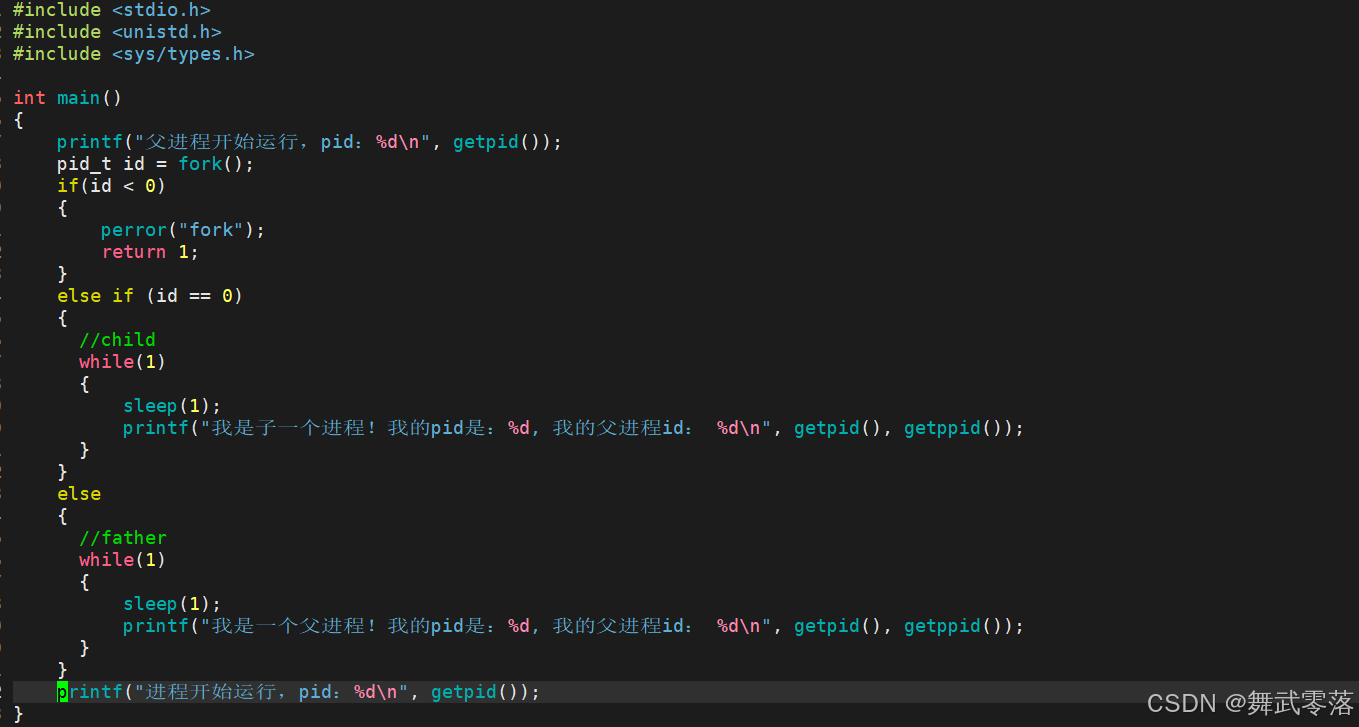
5.1.fork用来创建一个子进程
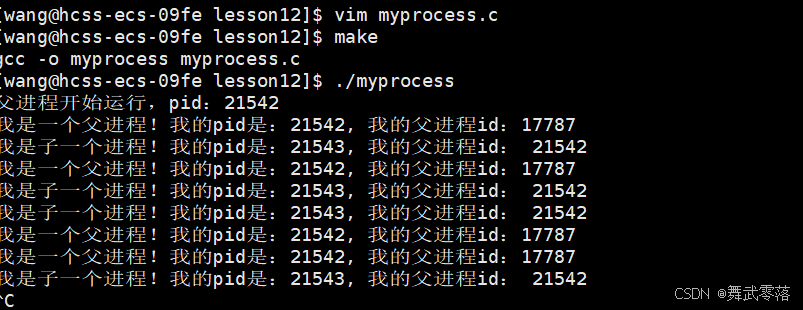
开始只有一个进程,通过fork创建后会有两个进程,并且这两个进程都会执行fork之后的代码
为什么两个进程都会执行之后的代码呢?
- 通常是因为子进程会复制父进程的进程控制块(PCB),其中包含 程序计数器(PC) —— 这个字段记录了父进程当前执行到的代码位置。子进程继承的 PC 值和父进程完全相同,意味着它会从 fork() 调用的下一行代码开始执行,而非从头运行程序
- 程序的代码段(存放可执行指令的区域)是只读的,父子进程无需各自复制一份,而是通过页表映射到同一块物理内存。因此两者能访问完全相同的代码,自然能执行后续相同的代码逻辑。
- 此时子进程没有自己的数据和代码,因为fork() 创建子进程时,采用写时拷贝机制:内核仅复制父进程的元数据(如 task_struct 进程控制块、页表等),而代码段、数据段等内存页通过页表映射共享物理内存(代码段因只读特性始终共享,数据相关内存页标记为只读)。只有当父子进程中任意一方修改共享内存页时,内核才会为该页创建独立副本。
5.2.fork() 的返回值

如果调用成功,子进程的ID作为返回值返回给父进程(这是一个整数),0 返回给子进程。调用失败-1被返回给父进程。
5.3.父子执行不同代码
为什么fork给父子进程各自返回不同的返回值呢?
这是因为父 : 子 = 1 :n,意思是一个父进程可以有多个子进程,所以要给父进程返回子进程的id来区分不同的子进程,方便对子进程进行管理。
为什么一个变量,能够既等于0,又大于0,同时满足 if 和 else?
本质是进程独立性与写时拷贝机制共同作用的结果。
- 当通过 fork() 创建子进程时,系统会为子进程复制父进程的进程控制块(PCB)及页表等元数据,但核心的内存资源(包括变量所在的内存页)会暂时共享。此时父子进程看似操作 “同一个变量”,实则指向同一块物理内存。
- 但是进程是独立的,一个进程的消失不影响其它进程,这决定了进程必须拥有各自的执行环境。
- 对于父子进程,如果其中一方修改了数据,OS(操作系统)会把修改的数据在底层拷贝一份,让修改方在新副本中操作,而另一方仍使用原内存页,这就是写时拷贝。
下面的结果可以看到,子进程的gval和父进程的gval是不一样的
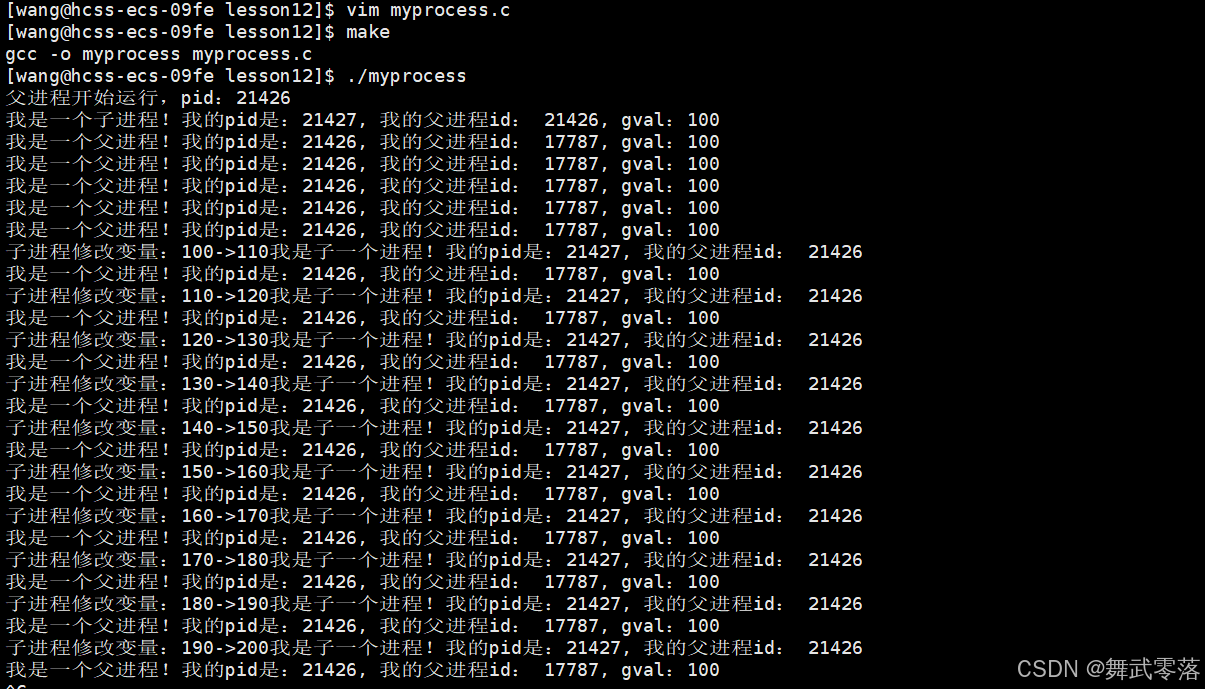
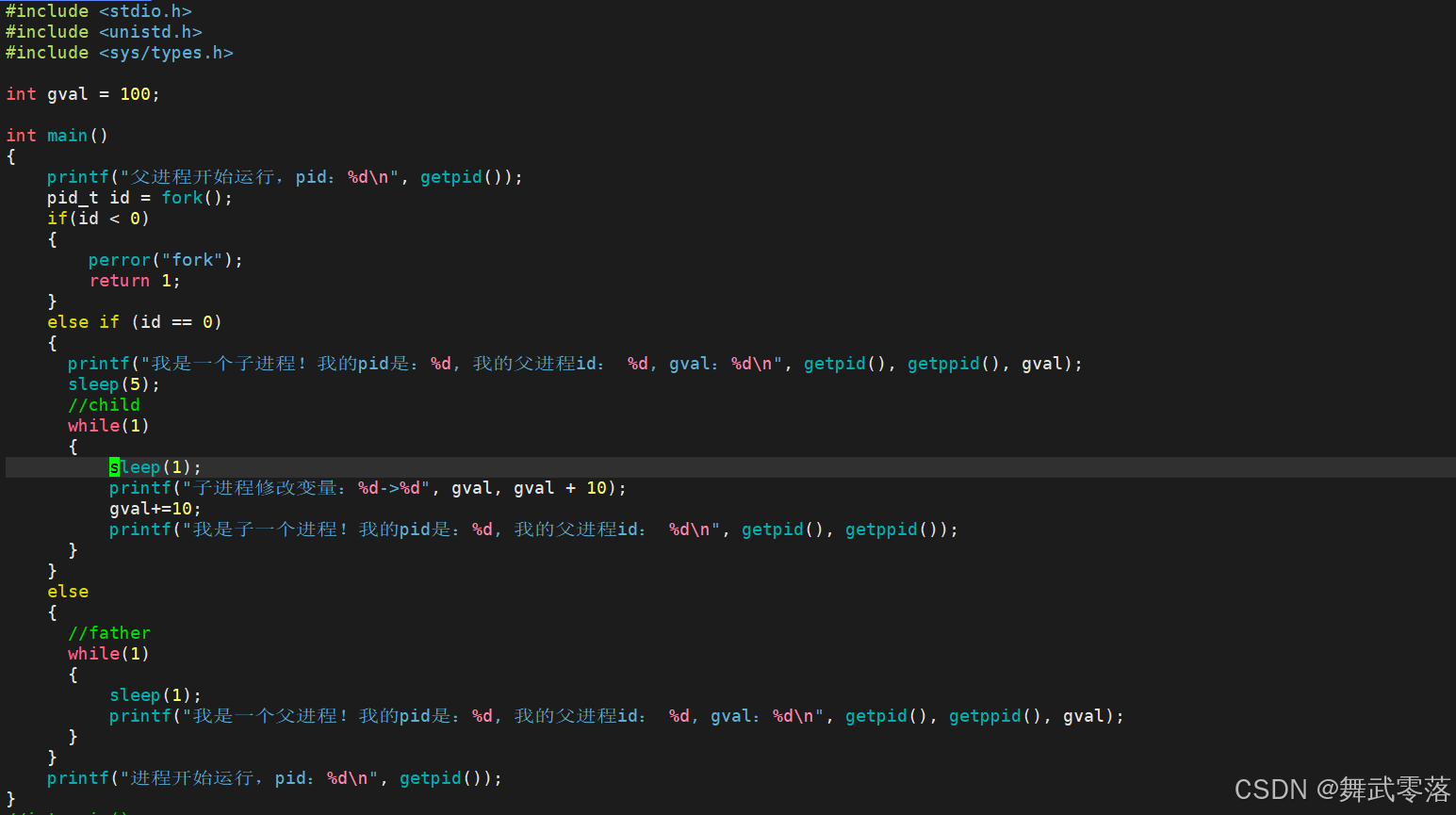
可以说 fork() 就像细胞分裂,原来的细胞(父进程)会分裂出一个新的细胞(子进程)。

















 1579
1579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









