




 本文深入比较了全连接头(fc-head)和卷积头(conv-head)在目标检测任务中的表现,发现两者在分类和定位任务上具有互补优势。fc-head擅长对象分类,而conv-head则擅长边界框回归。因此,作者提出了双头方法,结合fc-head用于分类,conv-head用于回归,实现了性能提升。在实验中,双头方法在ResNet-50和ResNet-101基础上分别提升了+3.5和+2.8的AP值。
本文深入比较了全连接头(fc-head)和卷积头(conv-head)在目标检测任务中的表现,发现两者在分类和定位任务上具有互补优势。fc-head擅长对象分类,而conv-head则擅长边界框回归。因此,作者提出了双头方法,结合fc-head用于分类,conv-head用于回归,实现了性能提升。在实验中,双头方法在ResNet-50和ResNet-101基础上分别提升了+3.5和+2.8的AP值。
原文链接Rethinking Classification and Localization for Object Detection
CVPR2020
目录
1. Introduction
大多数两阶段目标检测器共享一个分类和边界盒回归的head。然而对fc-head,conv-head这两个头部结构之间缺乏理解。在本文中,作者对全连接头(fc头)和卷积头(凸头)进行了彻底的比较。对象的分类和本地化。我们发现这两种不同的头部结构是互补的。fc-head能更好地区分一个完整的对象和一个对象的一部分更适用于分类任务.conv-head提供了更准确的bounding box regression更适用于回归任务。鉴于上述发现,作者提出了双头方法,其中包括一个完全连接的头 (fc-head)用于分类和卷积头(conv-head)用于边界框回归。
2. Related Work
首先看下几种head结构
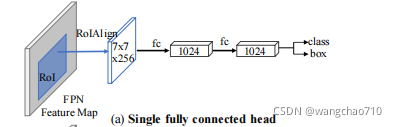
在得到feature map后接上一个全连接分支,在最后接上两个分支,一个输出预测的BoundingBox位置信息,一个输出对应位置的类别信息。
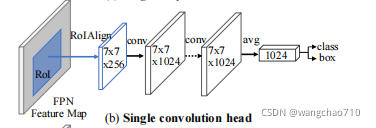
在得到feature map后接上几个卷积操作,再接上一个全连接,最后接上一个分支输出预测的BoundingBox位置信息,一个分支输出对应位置的类别信息。
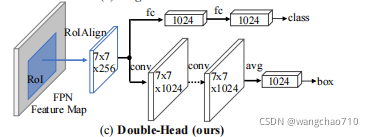
该结构是将上面两种结合在一起,全连接的用于分类任务,卷积的拥有回归任务。在本文中作者称为Double-Head。
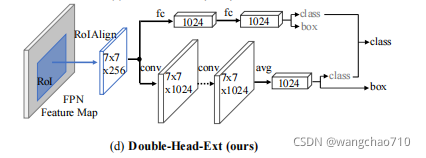
作者发现fc-head和conv-head其实在分类上是互补的。因此,作者在训练中引入了不集中的任务监督,并提出了一种互补的融合方法,结构如上图所示。
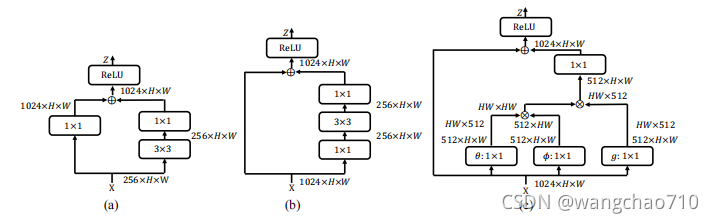
conv-head结构的第一个残差块如图(a),将提取的RoI的通道数256增加到1024通道,参数量1.06M。
conv-head结构后续残差块如图(b),正常的resnet block操作,参数量1.06M。
在每个b块之前添加一个块c,来为conv-head引入一种变化,以增强前景对象,参数量2M。作者顺序叠加{a−c−b−c−b}构成conv-head。
double-head Loss:
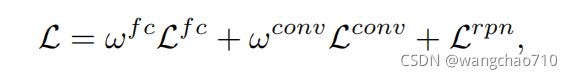
![]() ,
,![]() ,
,![]() 分别表示fc-head,conv-head,FPN的损失;
分别表示fc-head,conv-head,FPN的损失;![]() ,
,![]() 分别表示fc-head和conv-head部分损失的权重,实验分别取2.0和2.5。
分别表示fc-head和conv-head部分损失的权重,实验分别取2.0和2.5。
Double-Head-Ext Loss:
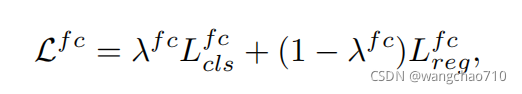
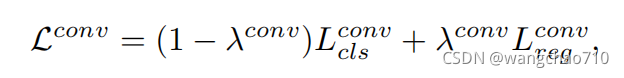
其中超参![]() ,
,![]() 分别取0.7和0.8最优
分别取0.7和0.8最优
Complementary Fusion of Classififiers:
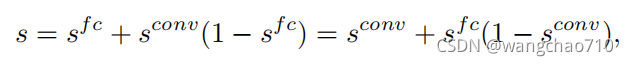
![]() 表示fc-head分类的得分,
表示fc-head分类的得分,![]() 表示conv-head分类的得分。
表示conv-head分类的得分。
3.Experimental Results
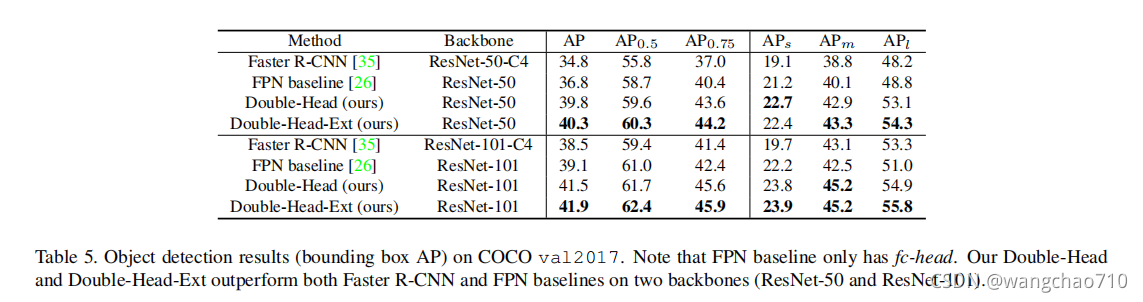
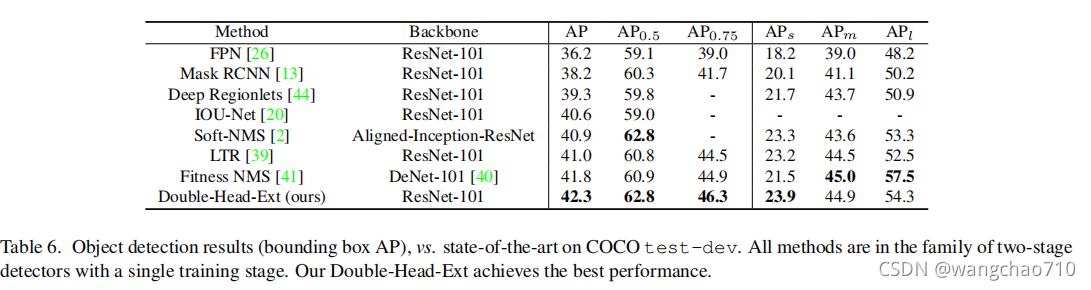
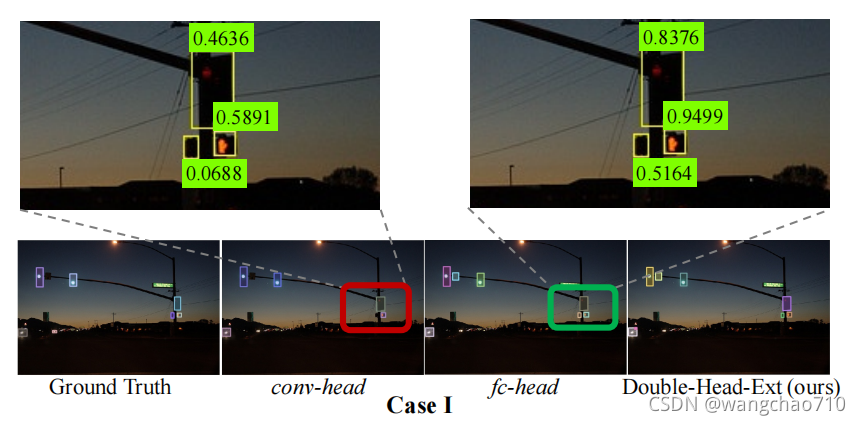


结果显示fc-head head 比 conv-head 更适合分类 。
4.Conclusions
在本文中,作者发现了一个有趣的事实,两种广泛使用的fc-head和conv-head在目标检测中对分类和定位任务具有相反的偏好。具体来说,fc-head 更适合分类任务,而 conv-head 更适合定位任务。此外,作者检查输出特征两个头部的映射,发现 fc-head 比 conv-head 具有更高的空间敏感性。因此,fc-head 具有更强的区分完整对象和部分对象的能力,但对整个对象的回归并不鲁棒。基于这些发现,作者提出了一种双头方法,它有一个专注于分类的fc-head和一个用于边界框回归的conv-head。作者的方法分别从具有 ResNet-50 和 ResNet-101 主干的 FPN 基线在 MS COCO 数据集上获得 +3.5 和 +2.8 AP。

















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









