




 本文介绍了机器学习的四大类型:监督学习,如分类和回归,包括K近邻、线性回归等算法;非监督学习,涉及聚类和降维算法,如K均值、PCA;强化学习,通过智能体与环境互动学习最优策略;以及半监督学习,结合少量标签数据进行学习。此外,还提及批量和在线学习、基于实例与基于模型学习的不同学习策略。
本文介绍了机器学习的四大类型:监督学习,如分类和回归,包括K近邻、线性回归等算法;非监督学习,涉及聚类和降维算法,如K均值、PCA;强化学习,通过智能体与环境互动学习最优策略;以及半监督学习,结合少量标签数据进行学习。此外,还提及批量和在线学习、基于实例与基于模型学习的不同学习策略。
机器学习下面是一个大宝藏,包含了很多种学习方式,其中最典型的是四种:
一 监督学习
在监督学习中,用来训练算法的训练数据包含了答案,称为标签。一个典型的监督学习任务是分类。垃圾邮件过滤器就是一个很好的例子:用许多带有归类(垃圾邮件或普通邮件)的邮件样本进行训练,过滤器必须还能对新邮件进行分类。
另一个典型任务是预测目标数值,例如给出一些特征(里程数、车龄、品牌等等)称作预测
值,来预测一辆汽车的价格。这类任务称作回归。要训练这个系统,你需要给出大
量汽车样本,包括它们的预测值和标签(即,它们的价格)
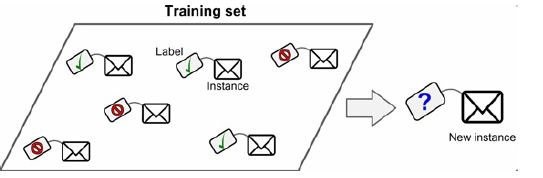
下面是一些重要的监督学习算法:
1 K近邻算法
2 线性回归
3 逻辑回归
4 支持向量机(SVM)
5 决策树和随机森林
6 神经网络
二 非监督学习
在非监督学习中,你可能猜到了,训练数据是没有加标签的。系统在没有老师的条件下进行学习。
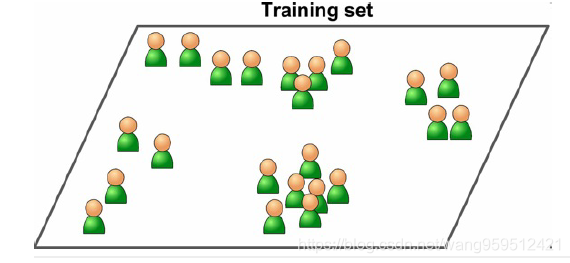
下面是一些最重要的非监督学习算法:
1 聚类
2 K 均值
3 层次聚类分析(Hierarchical Cluster Analysis,HCA)
4 期望最大值
5 可视化和降维
6 主成分分析(Principal Component Analysis,PCA)
7 核主成分分析
8 局部线性嵌入(Loca
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1964
1964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









