




问题描述
启动DataKit 服务后,在服务空载情况下,出现CPU使用率报高,维持在 80+% 左右。
问题分析
通过问题分析脚本对当前DataKit进行异常分析:
#!/bin/bash
# ####################################
# Java进程CPU高占用紧急诊断脚本
# 针对PID 3434的高CPU使用率问题
# ####################################
set -euo pipefail
# 配置参数
PID="3434"
USER="wang"
PROCESS_NAME="java"
EMERGENCY_THRESHOLD=80
LOG_DIR="./java_diagnosis_logs"
REPORT_DIR="./emergency_reports"
# 创建日志目录
mkdir -p "${LOG_DIR}"
mkdir -p "${REPORT_DIR}"
# 颜色定义
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
BLUE='\033[0;34m'
NC='\033[0m'
# 日志函数
log_info() { echo -e "${BLUE}[INFO]${NC} $1"; }
log_warn() { echo -e "${YELLOW}[WARN]${NC} $1"; }
log_error() { echo -e "${RED}[ERROR]${NC} $1"; }
log_emergency() { echo -e "${RED}🚨[EMERGENCY]${NC} $1"; }
# 检查进程状态
check_process_status() {
log_info "检查进程 ${PID} 状态..."
if ! ps -p "$PID" > /dev/null 2>&1; then
log_error "进程 ${PID} 不存在或已退出"
return 1
fi
local process_info
process_info=$(ps -p "$PID" -o pid,user,pcpu,pmem,vsz,rss,etime,command --no-headers)
if [ -n "$process_info" ]; then
echo "当前进程状态:"
echo "PID USER CPU% MEM% VSZ RSS ELAPSED COMMAND"
echo "$process_info"
echo ""
local current_cpu
current_cpu=$(echo "$process_info" | awk '{print $3}')
if (( $(echo "$current_cpu > $EMERGENCY_THRESHOLD" | bc -l 2>/dev/null) )); then
log_emergency "检测到CPU使用率异常: ${current_cpu}%"
return 2
else
log_info "当前CPU使用率: ${current_cpu}%"
return 0
fi
fi
}
# 紧急诊断 - 分析高CPU原因
emergency_diagnosis() {
local timestamp
timestamp=$(date '+%Y%m%d_%H%M%S')
local report_file="${REPORT_DIR}/emergency_report_${PID}_${timestamp}.txt"
log_emergency "开始紧急诊断进程 ${PID}..."
cat > "$report_file" <<EOF
🚨 Java进程紧急诊断报告
==================================================
诊断时间: $(date '+%Y-%m-%d %H:%M:%S')
进程PID: ${PID}
用户: ${USER}
问题: CPU使用率87.7% (严重过高)
==================================================
EOF
# 1. 检查系统负载
echo "1. 系统整体负载检查..." >> "$report_file"
echo "--------------------------------------------------" >> "$report_file"
uptime >> "$report_file"
echo "" >> "$report_file"
# 2. 检查进程详细信息
echo "2. 进程详细信息..." >> "$report_file"
echo "--------------------------------------------------" >> "$report_file"
ps -p "$PID" -o pid,user,pcpu,pmem,vsz,rss,etime,state,pri,ni --no-headers >> "$report_file"
echo "" >> "$report_file"
# 3. 检查Java线程CPU使用
analyze_java_threads >> "$report_file"
# 4. 检查GC情况
analyze_gc_status >> "$report_file"
# 5. 生成紧急处理建议
generate_emergency_actions >> "$report_file"
log_info "紧急诊断报告已生成: $report_file"
echo ""
cat "$report_file"
}
# 分析Java线程CPU使用
analyze_java_threads() {
log_info "分析Java线程CPU使用情况..."
local thread_log="${LOG_DIR}/threads_${PID}_$(date '+%Y%m%d_%H%M%S').log"
echo "3. Java线程CPU使用分析" >> "$report_file"
echo "--------------------------------------------------" >> "$report_file"
# 方法1: 使用top查看线程
if top -H -b -n 1 -p "$PID" > "$thread_log" 2>/dev/null; then
echo "线程CPU使用排行 (top -H -p $PID):" >> "$report_file"
grep -E "^[[:space:]]*[0-9]" "$thread_log" | head -10 >> "$report_file"
echo "" >> "$report_file"
fi
# 方法2: 使用ps查看线程
echo "线程详细信息 (ps -L):" >> "$report_file"
ps -L -p "$PID" -o tid,pcpu,pmem,state,time,comm --no-headers | sort -k2 -nr | head -10 >> "$report_file"
echo "" >> "$report_file"
# 方法3: 尝试使用jstack(如果可用)
if command -v jstack >/dev/null 2>&1; then
local jstack_file="${LOG_DIR}/jstack_${PID}_$(date '+%Y%m%d_%H%M%S').log"
log_info "执行jstack分析..."
jstack "$PID" > "$jstack_file" 2>/dev/null && echo "jstack输出已保存: $jstack_file" >> "$report_file"
fi
}
# 分析GC状态
analyze_gc_status() {
log_info "分析GC状态..."
echo "4. GC状态分析" >> "$report_file"
echo "--------------------------------------------------" >> "$report_file"
# 检查jstat是否可用
if command -v jstat >/dev/null 2>&1; then
local gc_log="${LOG_DIR}/gc_${PID}_$(date '+%Y%m%d_%H%M%S').log"
echo "当前GC统计:" >> "$report_file"
jstat -gcutil "$PID" 1000 1 >> "$report_file" 2>/dev/null || echo "无法获取GC信息" >> "$report_file"
echo "" >> "$report_file"
# 监控GC变化
echo "GC变化监控 (5次采样):" >> "$report_file"
jstat -gcutil "$PID" 1000 5 >> "$report_file" 2>/dev/null || echo "无法监控GC变化" >> "$report_file"
echo "" >> "$report_file"
else
echo "jstat不可用,跳过GC分析" >> "$report_file"
fi
}
# 生成紧急处理建议
generate_emergency_actions() {
echo "5. 🚨 紧急处理建议" >> "$report_file"
echo "==================================================" >> "$report_file"
cat >> "$report_file" <<EOF
🚨 立即行动建议 (按优先级排序):
1. 🎯 最高优先级 - 立即诊断
----------------------------------
✅ 立即执行线程转储分析:
jstack -l ${PID} > jstack_emergency.log
✅ 检查热点线程:
top -H -p ${PID}
ps -L -p ${PID} -o tid,pcpu,pmem,state,time,comm | sort -k2 -nr | head -5
✅ 实时监控GC:
jstat -gcutil ${PID} 1000 10
2. 🔧 短期缓解措施
----------------------------------
⚠️ 考虑重启应用 (如果业务允许)
⚠️ 调整JVM参数 (增加堆内存或调整GC策略)
⚠️ 检查应用日志中的错误或异常模式
⚠️ 检查数据库连接池状态
3. 📊 根本原因分析
----------------------------------
🔍 分析线程转储,查找:
- 死循环线程
- 锁竞争问题
- 大量GC线程
- 阻塞的I/O操作
🔍 检查应用配置:
- JVM参数是否合理
- 数据库连接池配置
- 缓存配置
- 外部服务调用超时设置
4. 🛡️ 预防措施
----------------------------------
📈 建立监控告警 (CPU > 80% 时告警)
📈 定期健康检查
📈 性能压力测试
📈 代码审查 (避免死循环、资源泄漏)
EOF
}
# 实时监控高CPU线程
monitor_hot_threads() {
log_info "开始实时监控高CPU线程..."
local monitor_log="${LOG_DIR}/hot_threads_monitor_${PID}.log"
echo "时间,线程TID,CPU%,内存%,状态,命令" > "$monitor_log"
for i in {1..10}; do
local timestamp
timestamp=$(date '+%Y-%m-%d %H:%M:%S')
echo "=== 监控周期 $i ===" >> "$monitor_log"
# 获取高CPU线程
ps -L -p "$PID" -o tid,pcpu,pmem,state,time,comm --no-headers | sort -k2 -nr | head -5 | while read -r line; do
echo "${timestamp},${line}" >> "$monitor_log"
done
echo "监控周期 $i - 高CPU线程:"
ps -L -p "$PID" -o tid,pcpu,pmem,state,time,comm --no-headers | sort -k2 -nr | head -3
sleep 2
done
log_info "线程监控完成: $monitor_log"
}
# 生成修复建议脚本
generate_fix_scripts() {
log_info "生成修复建议脚本..."
local fix_script="${REPORT_DIR}/suggested_fixes_${PID}.sh"
cat > "$fix_script" <<'EOF'
#!/bin/bash
# Java进程CPU高占用修复建议脚本
# 生成的修复措施
set -euo pipefail
PID="$1"
echo "🔧 Java进程CPU高占用修复建议"
# 1. 立即诊断命令
echo ""
echo "1. 立即诊断命令:"
echo " # 线程转储分析"
echo " jstack -l $PID > jstack_analysis.log"
echo ""
echo " # 实时监控高CPU线程"
echo " top -H -p $PID"
echo " ps -L -p $PID -o tid,pcpu,pmem,state,time,comm | sort -k2 -nr | head -5"
echo ""
echo " # GC状态监控"
echo " jstat -gcutil $PID 1000 5"
# 2. JVM参数优化建议
echo ""
echo "2. JVM参数优化建议:"
echo " # 当前JVM参数检查"
echo " jcmd $PID VM.flags"
echo ""
echo " # 建议添加的JVM参数:"
echo " -XX:+UseG1GC -XX:MaxGCPauseMillis=200"
echo " -XX:InitiatingHeapOccupancyPercent=35"
echo " -Xlog:gc*=info:file=gc.log:time,uptime,level,tags"
echo ""
# 3. 应用层面检查
echo ""
echo "3. 应用层面检查:"
echo " # 检查数据库连接池"
echo " # 查看应用日志中的异常"
echo " # 检查外部服务调用超时"
echo " # 验证缓存配置"
# 4. 系统层面检查
echo ""
echo "4. 系统层面检查:"
echo " # 检查系统负载"
echo " uptime"
echo " # 检查内存使用"
echo " free -h"
echo " # 检查IO状态"
echo " iostat -x 1 5"
EOF
chmod +x "$fix_script"
log_info "修复建议脚本已生成: $fix_script"
}
# 主菜单
show_menu() {
echo ""
echo "======================================="
echo " 🚨 Java进程CPU紧急诊断工具"
echo "======================================="
echo "当前进程: PID=$PID, USER=$USER, CPU=87.7%"
echo "======================================="
echo "1. 🔍 立即诊断高CPU原因"
echo "2. 📊 实时监控高CPU线程"
echo "3. 📈 检查GC状态"
echo "4. 🛠️ 生成修复建议脚本"
echo "5. 📋 查看系统整体状态"
echo "6. 🚨 紧急线程转储分析"
echo "0. 🔚 退出"
echo "======================================="
echo -n "请选择操作 [0-6]: "
}
# 查看系统整体状态
check_system_status() {
log_info "检查系统整体状态..."
echo "=== 系统整体状态 ==="
echo "1. 系统负载:"
uptime
echo ""
echo "2. 内存使用:"
free -h
echo ""
echo "3. 最耗CPU的进程:"
ps aux --sort=-%cpu | head -10
echo ""
echo "4. 最耗内存的进程:"
ps aux --sort=-%mem | head -10
}
# 紧急线程转储分析
emergency_thread_dump() {
log_emergency "执行紧急线程转储分析..."
local dump_file="${LOG_DIR}/emergency_thread_dump_${PID}_$(date '+%Y%m%d_%H%M%S').log"
if command -v jstack >/dev/null 2>&1; then
echo "执行jstack线程转储..."
jstack -l "$PID" > "$dump_file"
if [ $? -eq 0 ]; then
log_info "线程转储完成: $dump_file"
# 简单分析线程状态
echo "线程状态统计:"
grep -o 'java.lang.Thread.State: [A-Z_]*' "$dump_file" | sort | uniq -c | sort -nr
echo ""
echo "建议使用专业工具分析: $dump_file"
else
log_error "线程转储失败"
fi
else
log_error "jstack命令不可用"
fi
}
# 主函数
main() {
log_emergency "检测到Java进程CPU使用率过高: 87.7%"
# 检查进程状态
if ! check_process_status; then
if [ $? -eq 2 ]; then
log_emergency "确认CPU使用率超过阈值,需要紧急处理!"
else
exit 1
fi
fi
while true; do
show_menu
read -r choice
case $choice in
1)
emergency_diagnosis
;;
2)
monitor_hot_threads
;;
3)
analyze_gc_status
;;
4)
generate_fix_scripts
;;
5)
check_system_status
;;
6)
emergency_thread_dump
;;
0)
log_info "退出诊断工具"
exit 0
;;
*)
log_error "无效选择"
;;
esac
done
}
# 运行主函数
main
通过堆栈分析,发现当前引入的disruptor 相关业务引起的CPU使用率过高。
分析disruptor配置
当前disruptor配置代码
Disruptor<MetricEvent> disruptor = new Disruptor<>(
MetricEvent::new, // 1. 事件工厂
bufferSize * 1024, // 2. 环形缓冲区大小
Executors.defaultThreadFactory(), // 3. 线程工厂
ProducerType.SINGLE, // 4. 生产者类型
new SleepingWaitStrategy(100, 1000) // 5. 等待策略
);
各参数对CPU空转时占用率的影响分析
1. 缓冲区大小:bufferSize * 1024
-
影响:缓冲区大小直接影响内存占用,但对空转时CPU占用基本无影响
-
建议:
-
过大:浪费内存
-
过小:容易触发背压
-
合理值:根据业务吞吐量估算,通常设置为2的幂次方
-
2. 生产者类型:ProducerType.SINGLE
-
单生产者 vs 多生产者对CPU的影响:
-
单生产者:空转时CPU占用较低,因为不需要CAS操作竞争序列号
-
多生产者:需要CAS操作,空转时仍有一定CPU开销
-
-
建议:
// 根据实际情况选择 ProducerType.SINGLE // 只有一个生产者线程时使用(CPU占用低) ProducerType.MULTI // 多个生产者线程时使用(CPU占用较高)
3. 等待策略:SleepingWaitStrategy(100, 1000)
这是影响空转CPU占用率的关键参数!
SleepingWaitStrategy 的工作原理:
new SleepingWaitStrategy(
100, // retries: 在休眠前尝试获取数据的次数
1000 // sleepTimeNs: 休眠的纳秒时间(这里是1000ns = 1微秒)
)
空转时CPU占用高的原因:
-
重试次数过高:
retries = 100-
每次空转循环会尝试100次后才休眠
-
100次无意义的循环会消耗CPU时间
-
-
休眠时间过短:
sleepTimeNs = 1000ns(1微秒)-
1微秒的休眠时间极短
-
线程会频繁唤醒和休眠,上下文切换开销大
-
实际可能因为休眠时间太短,线程调度器还来不及让线程真正休眠
-
4. 线程工厂:Executors.defaultThreadFactory()
-
对CPU占用影响不大,但线程优先级会影响调度
-
可以考虑设置线程名以便调试
比较不同等待策略的空转CPU占用:
// 1. SleepingWaitStrategy - 平衡型(默认推荐)
// 空转CPU占用:中
// 延迟:中等
new SleepingWaitStrategy(10, 1000000) // 1ms休眠
// 2. BlockingWaitStrategy - 最低CPU占用
// 空转CPU占用:极低(使用锁和条件变量阻塞)
// 延迟:较高(唤醒需要上下文切换)
new BlockingWaitStrategy()
// 3. YieldingWaitStrategy - 低延迟但高CPU
// 空转CPU占用:高(忙等待)
// 延迟:极低
new YieldingWaitStrategy()
// 4. BusySpinWaitStrategy - 最高性能和最高CPU
// 空转CPU占用:100%(完全忙等待)
// 延迟:最低
new BusySpinWaitStrategy()
// 5. TimeoutBlockingWaitStrategy - 带超时的阻塞
// 空转CPU占用:低
// 延迟:中等
new TimeoutBlockingWaitStrategy(1000, TimeUnit.MILLISECONDS)
// 6. LiteBlockingWaitStrategy - 轻量级阻塞
// 空转CPU占用:低
// 延迟:中等
new LiteBlockingWaitStrategy()
最终修改方案
修改disruptor等待策略
new TimeoutBlockingWaitStrategy(1000, TimeUnit.MILLISECONDS)
方案验证
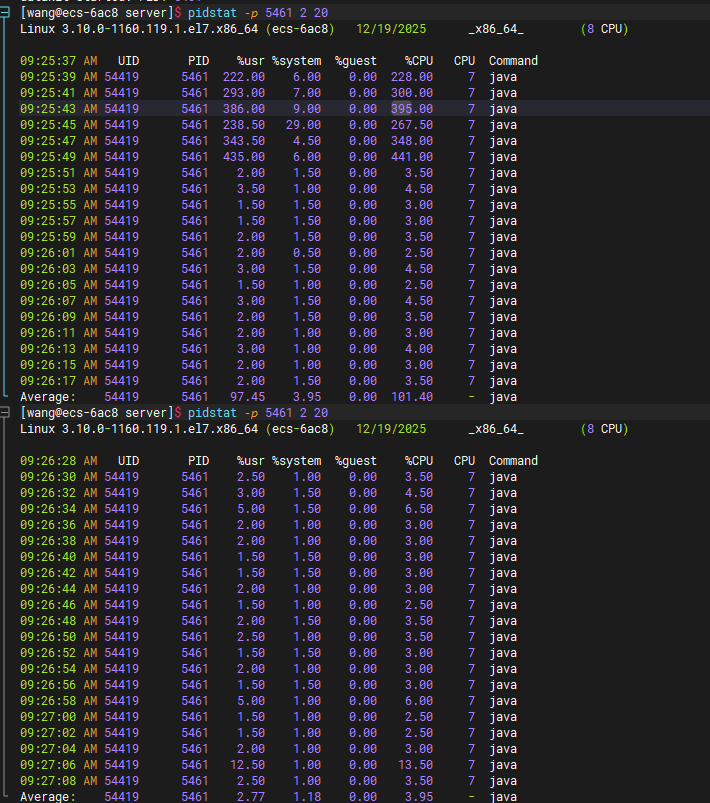
通过 pidstat -p 5461 2 20 命令查看当前datakit 进程cpu使用率
前期cpu出现6次 200~400 之间峰值,为进程启动阶段。启动完成后cpu使用率回落到2.5-5之间。
经确认当前修改方案通过


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











