







 本文探讨了利用深度学习在大规模数据集如One-Billion-Word和Yelp上进行文本生成,重点关注BLEU、NIST和MaETEOR等质量指标,以及自我重复率、双词和四词独特性来衡量多样性。文章介绍了并行修正技术在词汇约束下生成的优化方法,如BART。实验部分详细展示了如何通过迭代过程处理keyword并确保生成的重复性检查。
本文探讨了利用深度学习在大规模数据集如One-Billion-Word和Yelp上进行文本生成,重点关注BLEU、NIST和MaETEOR等质量指标,以及自我重复率、双词和四词独特性来衡量多样性。文章介绍了并行修正技术在词汇约束下生成的优化方法,如BART。实验部分详细展示了如何通过迭代过程处理keyword并确保生成的重复性检查。
方法
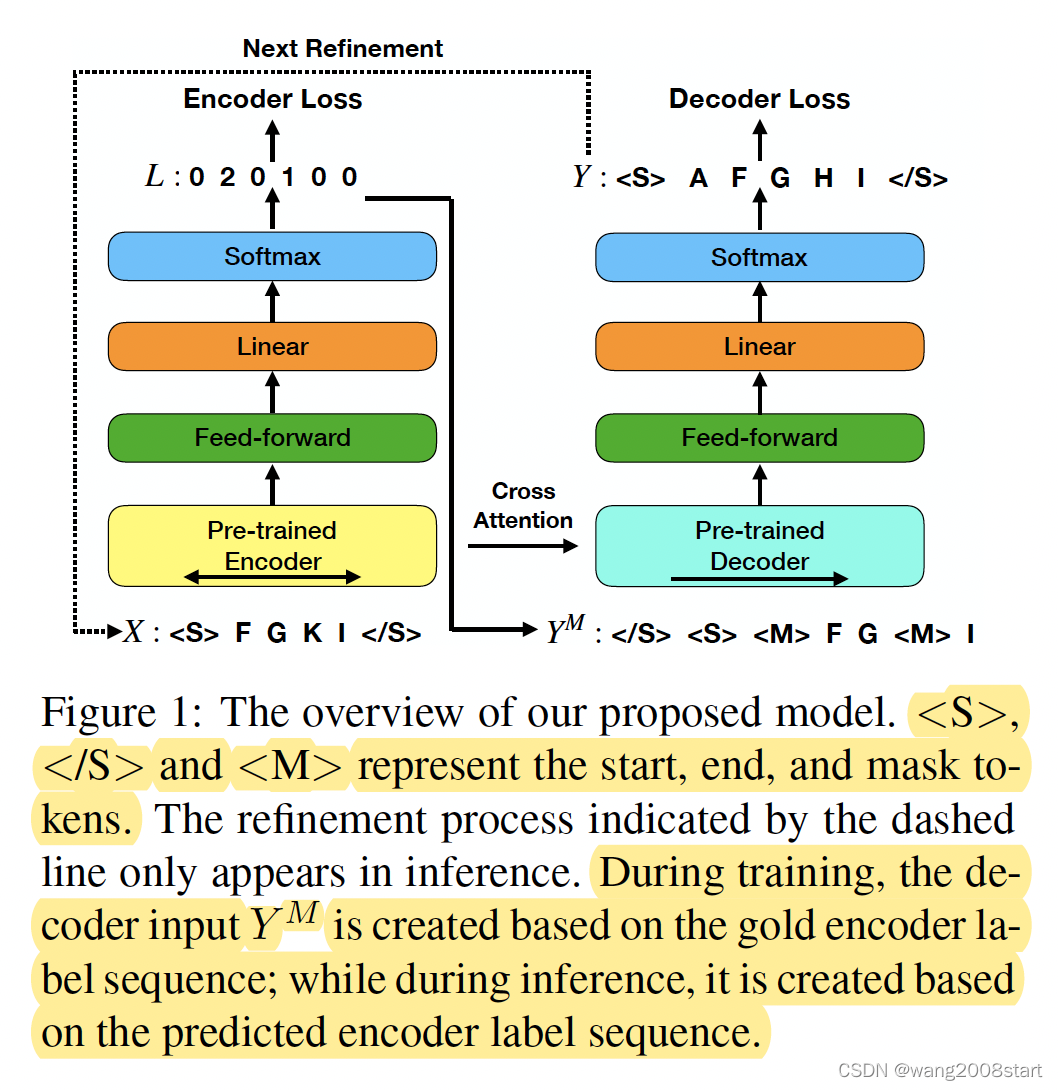
生成中包含指定的 keyword(可指定多个keyword)。一般处理此类问题时,把工作放在decoder阶段,这里将主要工作放在 encoder 阶段,encoder 过 softmax 后 进行分类,每个 token 是要进行拷贝/替换/插入(0/1/2) 的 action操作的某种。在decoder时进行相关操作。 生成包含指定keyword的任务,这里需要迭代多次才能完成,首次输入只有指定的keyword,对每个keyword的左右生成相应词,将输出作为第二阶段的输入,如此迭代。结束条件?
实验数据集
One-Billion-Word is a public dataset for language modeling produced from the WMT 2011 News Crawl data.
The Yelp dataset consists of business reviews on Yelp.
实验指标
生成质量:BLEU、NIST、MaETEOR
生成多样性: self-bleu score、distinct bigram(D-2) 、distinct 4-gram(D-4)
重复判断:first 20 tokens,单字出现超过2次,三字出现超过1次,则为重复
Ref
Parallel Refinements for Lexically Constrained Text Generation with BART.


















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









