




往期文章回顾:
Dify DeepResearch 2.0 评测:告别玩具时代?Dify深度研究Agent究竟进化到哪一步了!
飞书“知识问答” 深度实测:一键调用10W+份企业文档,还实时更新,一出手就是降维打击啊!
36k Star + 2.1k Star!两个热门的MCP开源合集项目介绍,并探索从根上搞懂MCP
5.3k!Dify GitHub热门工作流合集并介绍DIFY+MCP示例
Dify 开源DeepResearch工作流实现本地和Web混合搜索并探索工作流图的正确解析方法(一)
Dify内置DeepResearch工作流溯源——来看看Dify官方博客对它的介绍
Dify内置DeepResearch深度体验,抽丝剥茧带大家瞧瞧它的真实水准
Dify 实现DeepResearch工作流拆解并再看升级版Dify能否搭建出Manus?
深度解析:Dify能否复刻Deep Research与Manus?三大工具深度对比
异步操作的重要性是毋庸置疑的,在LangGraph等框架中大量出现。DIFY玩久了,这些概念有点生疏了,今天来复习一下。
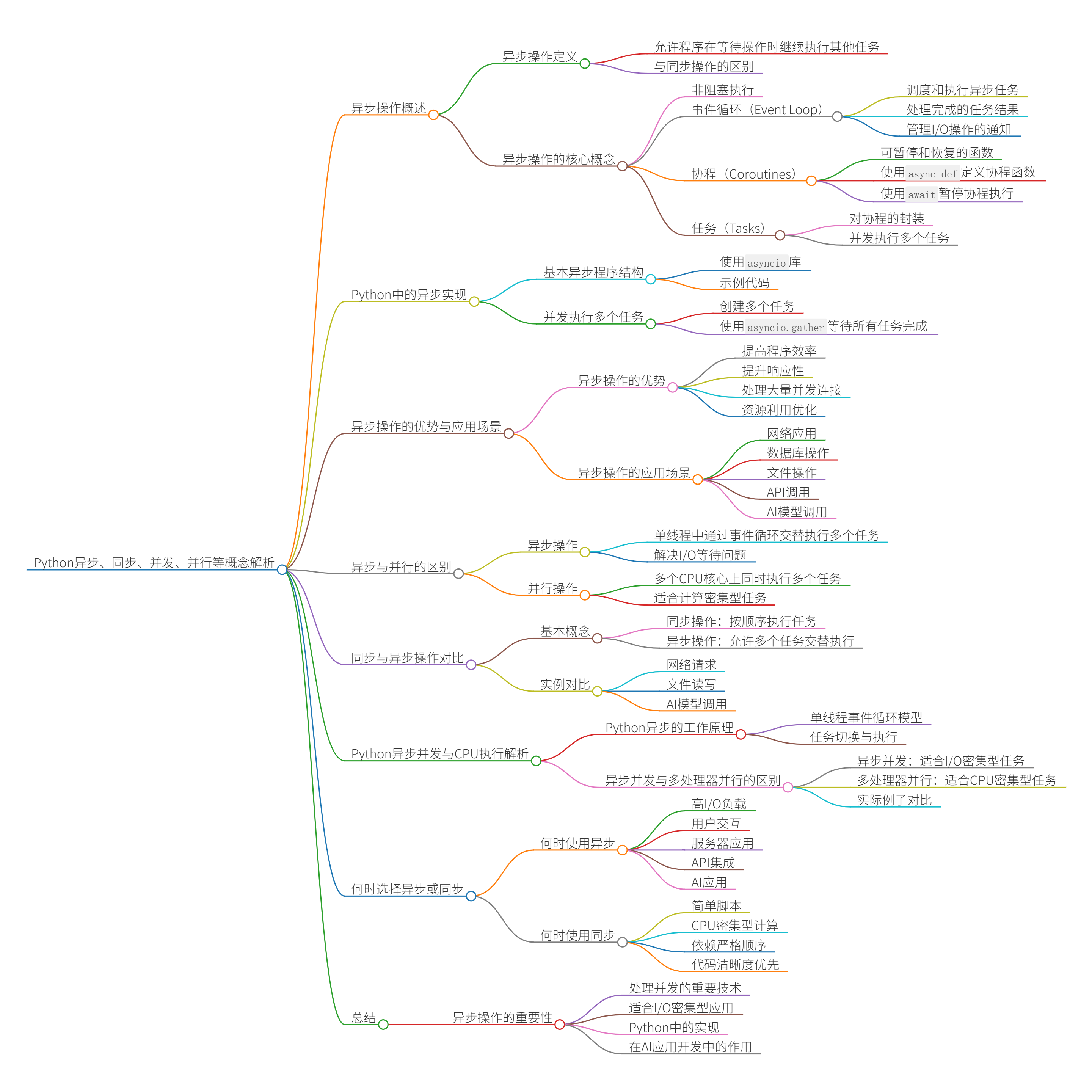
什么是异步操作?
异步操作是一种编程模式,允许程序在等待某些操作完成(如I/O操作)时继续执行其他任务,而不被阻塞。这与传统的同步操作不同,同步操作会使程序在一个操作完成前停止执行任何其他代码。
异步操作的核心概念
1. 非阻塞执行
在异步编程中,当程序遇到可能需要等待的操作时(如网络请求、文件读写),它不会停下来等待结果,而是继续执行其他可以立即处理的任务。
2. 事件循环(Event Loop)
事件循环是异步编程的核心机制,它负责:
- 调度和执行异步任务
- 处理完成的任务结果
- 管理I/O操作的通知
3. 协程(Coroutines)
协程(可以协同的程序?)是可以在执行过程中暂停和恢复的函数。在Python中,使用async def定义协程函数,使用await暂停协程执行直到等待的操作完成。
# Apply to workflow.py
async def fetch_data():
# 发起网络请求
response = await some_api_call()
# 当网络请求完成后,继续执行
return response4. 任务(Tasks)
任务是对协程的封装,代表一个正执行的操作。可以创建多个任务并并发(异步并发,非并行)执行它们。
# Apply to workflow.py
task1 = asyncio.create_task(fetch_data())
task2 = asyncio.create_task(process_data())
await asyncio.gather(task1, task2) # 并发执行两个任务Python中的异步实现
Python通过asyncio库提供异步编程支持:
基本异步程序结构
# Apply to workflow.py
import asyncio
async def main():
print("开始")
await asyncio.sleep(1) # 非阻塞等待1秒
print("1秒后")
asyncio.run(main()) # 运行异步程序并发执行多个任务
async def main():
# 创建三个并发任务
task1 = asyncio.create_task(some_coroutine())
task2 = asyncio.create_task(another_coroutine())
task3 = asyncio.create_task(third_coroutine())
# 等待所有任务完成
results = await asyncio.gather(task1, task2, task3)
return results注意:这里的并发并不是在多个CPU核心上同时执行,而是在单个CPU线程内通过事件循环交替执行多个任务。
异步操作的优势
- 提高程序效率:在等待I/O操作时可以执行其他任务,提高CPU利用率
- 提升响应性:特别是在网络应用和UI程序中,可以保持界面响应
- 处理大量并发连接:适合需要同时处理多个连接的服务器应用
- 资源利用优化:单线程中实现并发,避免了线程切换的开销
异步操作的应用场景
- 网络应用:处理多个HTTP请求、WebSocket连接
- 数据库操作:并发执行多个查询
- 文件操作:同时读写多个文件
- API调用:并行调用多个外部服务
- AI模型调用:同时处理多个模型推理请求
在AI应用中的异步操作
在AI和大语言模型应用中,异步操作尤为重要:
- 模型调用:LLM API调用通常有较长延迟,异步可以同时处理多个请求
- 工具使用:AI代理使用多个工具时可以并行执行
- 流式响应处理:处理模型的流式输出
- 多代理系统:让多个AI代理并行工作
异步与并行的区别
- 异步:在单线程中通过事件循环交替执行多个任务
- 并行:在多个CPU核心上同时执行多个任务(注意并行和并发的区别)
异步主要解决的是I/O等待问题,而非计算密集型问题。对于计算密集型任务,多进程并行可能更合适。
同步与异步操作对比详解
基本概念
同步操作:按顺序执行任务,一个任务完成后才开始下一个任务,期间程序会被阻塞。
异步操作:允许多个任务交替执行,当一个任务在等待(如I/O操作)时,可以执行其他任务,提高整体效率。
通过实例对比
场景一:网络请求
假设我们需要从三个不同的API获取数据:
同步方式
import requests
import time
def get_data_sync():
start_time = time.time()
# 依次发送三个请求
response1 = requests.get('https://api.example.com/data1') # 等待1秒
print(f"获取数据1完成,用时:{time.time() - start_time:.2f}秒")
response2 = requests.get('https://api.example.com/data2') # 等待1秒
print(f"获取数据2完成,用时:{time.time() - start_time:.2f}秒")
response3 = requests.get('https://api.example.com/data3') # 等待1秒
print(f"获取数据3完成,用时:{time.time() - start_time:.2f}秒")
return [response1.json(), response2.json(), response3.json()]
# 执行同步请求
results = get_data_sync()输出:
获取数据1完成,用时:1.05秒
获取数据2完成,用时:2.10秒
获取数据3完成,用时:3.15秒异步方式
import asyncio
import aiohttp
import time
async def get_data_async():
start_time = time.time()
async with aiohttp.ClientSession() as session:
# 创建三个并发请求任务
task1 = asyncio.create_task(
session.get('https://api.example.com/data1'))
task2 = asyncio.create_task(
session.get('https://api.example.com/data2'))
task3 = asyncio.create_task(
session.get('https://api.example.com/data3'))
# 等待所有请求完成
response1 = await task1
print(f"获取数据1完成,用时:{time.time() - start_time:.2f}秒")
response2 = await task2
print(f"获取数据2完成,用时:{time.time() - start_time:.2f}秒")
response3 = await task3
print(f"获取数据3完成,用时:{time.time() - start_time:.2f}秒")
# 解析JSON响应
data1 = await response1.json()
data2 = await response2.json()
data3 = await response3.json()
return [data1, data2, data3]
# 执行异步请求
results = asyncio.run(get_data_async())输出:
获取数据1完成,用时:1.02秒
获取数据2完成,用时:1.03秒
获取数据3完成,用时:1.05秒场景二:文件读写
同步方式
import time
def read_files_sync():
start_time = time.time()
with open('file1.txt', 'r') as f:
content1 = f.read() # 可能需要0.5秒
print(f"读取文件1完成,用时:{time.time() - start_time:.2f}秒")
with open('file2.txt', 'r') as f:
content2 = f.read() # 可能需要0.5秒
print(f"读取文件2完成,用时:{time.time() - start_time:.2f}秒")
with open('file3.txt', 'r') as f:
content3 = f.read() # 可能需要0.5秒
print(f"读取文件3完成,用时:{time.time() - start_time:.2f}秒")
return [content1, content2, content3]
# 执行同步读取
contents = read_files_sync()输出:
读取文件1完成,用时:0.50秒
读取文件2完成,用时:1.00秒
读取文件3完成,用时:1.50秒异步方式
import asyncio
import time
async def read_file(filename):
# 使用异步文件IO
async with asyncio.open_file(filename, 'r') as f:
return await f.read()
async def read_files_async():
start_time = time.time()
# 创建三个并发读取任务
task1 = asyncio.create_task(read_file('file1.txt'))
task2 = asyncio.create_task(read_file('file2.txt'))
task3 = asyncio.create_task(read_file('file3.txt'))
# 等待所有任务完成
content1 = await task1
print(f"读取文件1完成,用时:{time.time() - start_time:.2f}秒")
content2 = await task2
print(f"读取文件2完成,用时:{time.time() - start_time:.2f}秒")
content3 = await task3
print(f"读取文件3完成,用时:{time.time() - start_time:.2f}秒")
return [content1, content2, content3]
# 执行异步读取
contents = asyncio.run(read_files_async())输出:
读取文件1完成,用时:0.51秒
读取文件2完成,用时:0.52秒
读取文件3完成,用时:0.53秒场景三:AI模型调用
同步方式
from langchain_openai import ChatOpenAI
import time
def process_queries_sync():
start_time = time.time()
model = ChatOpenAI(model="gpt-3.5-turbo")
# 依次处理三个查询
response1 = model.invoke("解释什么是人工智能")
print(f"查询1完成,用时:{time.time() - start_time:.2f}秒")
response2 = model.invoke("解释什么是机器学习")
print(f"查询2完成,用时:{time.time() - start_time:.2f}秒")
response3 = model.invoke("解释什么是深度学习")
print(f"查询3完成,用时:{time.time() - start_time:.2f}秒")
return [response1, response2, response3]
# 执行同步查询
results = process_queries_sync()输出:
查询1完成,用时:2.50秒
查询2完成,用时:5.00秒
查询3完成,用时:7.50秒异步方式
import asyncio
from langchain_openai import ChatOpenAI
import time
async def process_queries_async():
start_time = time.time()
model = ChatOpenAI(model="gpt-3.5-turbo")
# 创建三个并发查询任务
task1 = asyncio.create_task(model.ainvoke("解释什么是人工智能"))
task2 = asyncio.create_task(model.ainvoke("解释什么是机器学习"))
task3 = asyncio.create_task(model.ainvoke("解释什么是深度学习"))
# 等待所有任务完成
response1 = await task1
print(f"查询1完成,用时:{time.time() - start_time:.2f}秒")
response2 = await task2
print(f"查询2完成,用时:{time.time() - start_time:.2f}秒")
response3 = await task3
print(f"查询3完成,用时:{time.time() - start_time:.2f}秒")
return [response1, response2, response3]
# 执行异步查询
results = asyncio.run(process_queries_async())输出:
查询1完成,用时:2.55秒
查询2完成,用时:2.60秒
查询3完成,用时:2.65秒何时使用异步?
异步操作特别适合以下场景:
- 高I/O负载:大量网络请求、文件操作
- 用户交互:需要保持界面响应
- 服务器应用:处理大量并发连接
- API集成:调用多个外部服务
- AI应用:并行处理多个模型调用或工具使用
何时使用同步?
同步操作适合以下场景:
- 简单脚本:执行简单的顺序任务
- CPU密集型计算:纯计算任务不会从异步中获益
- 依赖严格顺序:任务之间有严格的顺序依赖
- 代码清晰度优先:需要保持代码简单易读
Python异步并发与CPU执行解析
Python异步的工作原理
单线程事件循环模型
Python的asyncio使用的是单线程事件循环模型:
- 所有任务都在同一个线程中运行
- 事件循环负责在不同任务之间切换执行
- 当一个任务遇到await语句时,它会暂时让出控制权
- 事件循环会转而执行其他准备好的任务
异步并发与多处理器并行的区别
异步并发(Asynchronous Concurrency)
- 在单个CPU线程上运行
- 适合I/O密集型任务(如网络请求、文件读写)
- 通过事件循环在等待I/O时切换任务
- 使用asyncio、async/await实现
多处理器并行(Multiprocessing Parallelism)
- 在多个CPU核心上同时运行
- 适合CPU密集型任务(如大量计算)
- 真正的同时执行
- 使用multiprocessing模块实现
实际例子对比
异步并发(单CPU线程)
import asyncio
import time
async def io_task(name, delay):
print(f"{name} 开始于 {time.strftime('%X')}")
await asyncio.sleep(delay) # 模拟I/O操作(如网络请求)
print(f"{name} 完成于 {time.strftime('%X')}")
return f"{name} 结果"
async def main():
# 这些任务在同一个CPU线程中并发执行
tasks = [
asyncio.create_task(io_task("任务A", 2)),
asyncio.create_task(io_task("任务B", 1)),
asyncio.create_task(io_task("任务C", 3))
]
results = await asyncio.gather(*tasks)
return results
# 运行异步程序
results = asyncio.run(main())
print(results)输出:
任务A 开始于 10:00:00
任务B 开始于 10:00:00
任务C 开始于 10:00:00
任务B 完成于 10:00:01
任务A 完成于 10:00:02
任务C 完成于 10:00:03
['任务A 结果', '任务B 结果', '任务C 结果']多处理器并行(多CPU核心)
import multiprocessing
import time
def cpu_task(name, seconds):
print(f"{name} 开始于 {time.strftime('%X')}")
# 执行CPU密集型计算
start = time.time()
while time.time() - start < seconds:
pass # 纯CPU计算
print(f"{name} 完成于 {time.strftime('%X')}")
return f"{name} 结果"
if __name__ == "__main__":
# 这些进程在不同CPU核心上并行执行
with multiprocessing.Pool(processes=3) as pool:
tasks = [
pool.apply_async(cpu_task, ("进程A", 2)),
pool.apply_async(cpu_task, ("进程B", 1)),
pool.apply_async(cpu_task, ("进程C", 3))
]
results = [task.get() for task in tasks]
print(results)输出:
进程A 开始于 10:00:00
进程B 开始于 10:00:00
进程C 开始于 10:00:00
进程B 完成于 10:00:01
进程A 完成于 10:00:02
进程C 完成于 10:00:03
['进程A 结果', '进程B 结果', '进程C 结果']何时选择异步并发
异步并发(如你代码中的示例)最适合:
- I/O密集型任务:网络请求、API调用、数据库查询、文件操作
- 大量并发连接:Web服务器处理多个客户端连接
- 需要保持响应性:GUI应用、Web应用
- 资源受限环境:线程开销太大的场景
何时选择多处理器并行
多处理器并行最适合:
- CPU密集型任务:数据处理、图像处理、数学计算
- 可以分割的独立任务:批处理作业、并行算法
- 需要绕过GIL限制:Python的全局解释器锁限制了线程的真正并行
- 充分利用多核心CPU:在多核系统上提高性能
总结
异步操作是现代编程中处理并发的重要技术,特别适合I/O密集型应用。在Python中,通过asyncio库和async/await语法可以轻松实现异步编程。在AI应用开发中,异步操作能够显著提高系统吞吐量和响应速度,是构建高效AI系统的关键技术之一。

















 1268
1268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









