




提纲:
1、为什么需要非连续内存分配?
2、非连续物理内存管理方法:主要是分段和分页两种
3、页表的设计与组成
采用类型内存管理方式,不论是first fit、best fit还是worse fit,潜在都会带来一些列问题,
连续内存分配的缺点:
1 分配给一个程序的物理内存是连续的,
2 内存利用率较低
3 有外碎片、内碎片的问题
改进,使用非连续物理内存分配,
非连续物理内存分的优点:
- 一个程序的物理地址空间是非连续的
- 更好的内存利用和管理
- 允许共享代码与数据(共享库等...)
- 支持动态加载和动态链接
非连续内存管理的缺点:
最大的缺点就是管理开销本身,可以通过软件或者硬件的方式来完成,虚拟地址到物理内存地址的转换,这个转换过程,可以用软件来实现也可以用硬件来实现。
总的来说,用硬件实现,带来的开销是相当大的,所以需要考虑能否和计算机硬件结合,特别是CPU里面的一些关于内存管理的硬件组成部分结合在一起,来完成这个硬件支持的非连续内存的管理分配。
两种硬件方法:
1 分段
2 分页
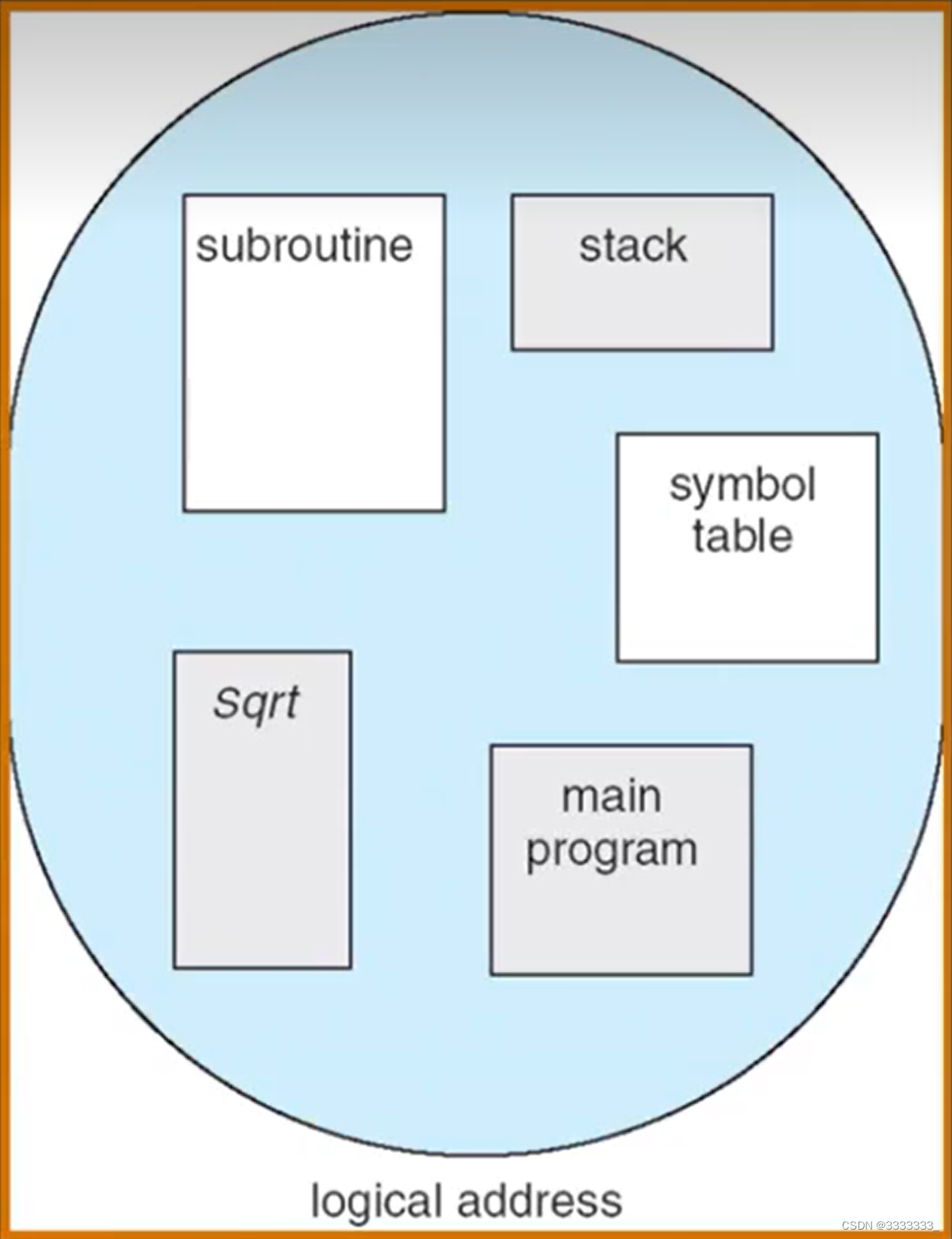
分段:
1 在分段情况下,内存地址空间怎么寻址的
2 怎么去实现这种分段寻址机制。
在分段机制下,应用程序什么样子?如上图
计算机程序也是由各种各样的段来组成的,比如说代码执行方面可以看到有一个主程序,还有子程序,还有共享库,这些呢形成代码不同的分段。另外数据也是一样,有栈段和堆段,还有其它一些共享数据段。
其实不同段之间是有不同属性的,如果能用一种方法有效的给他区别出来,隔离出来的话,其实有助于更好的去管理程序。
分段:更好的分离和共享
其实分段机制就是想根据我们应用程序执行的特点来对他们进行一个分离和管理。
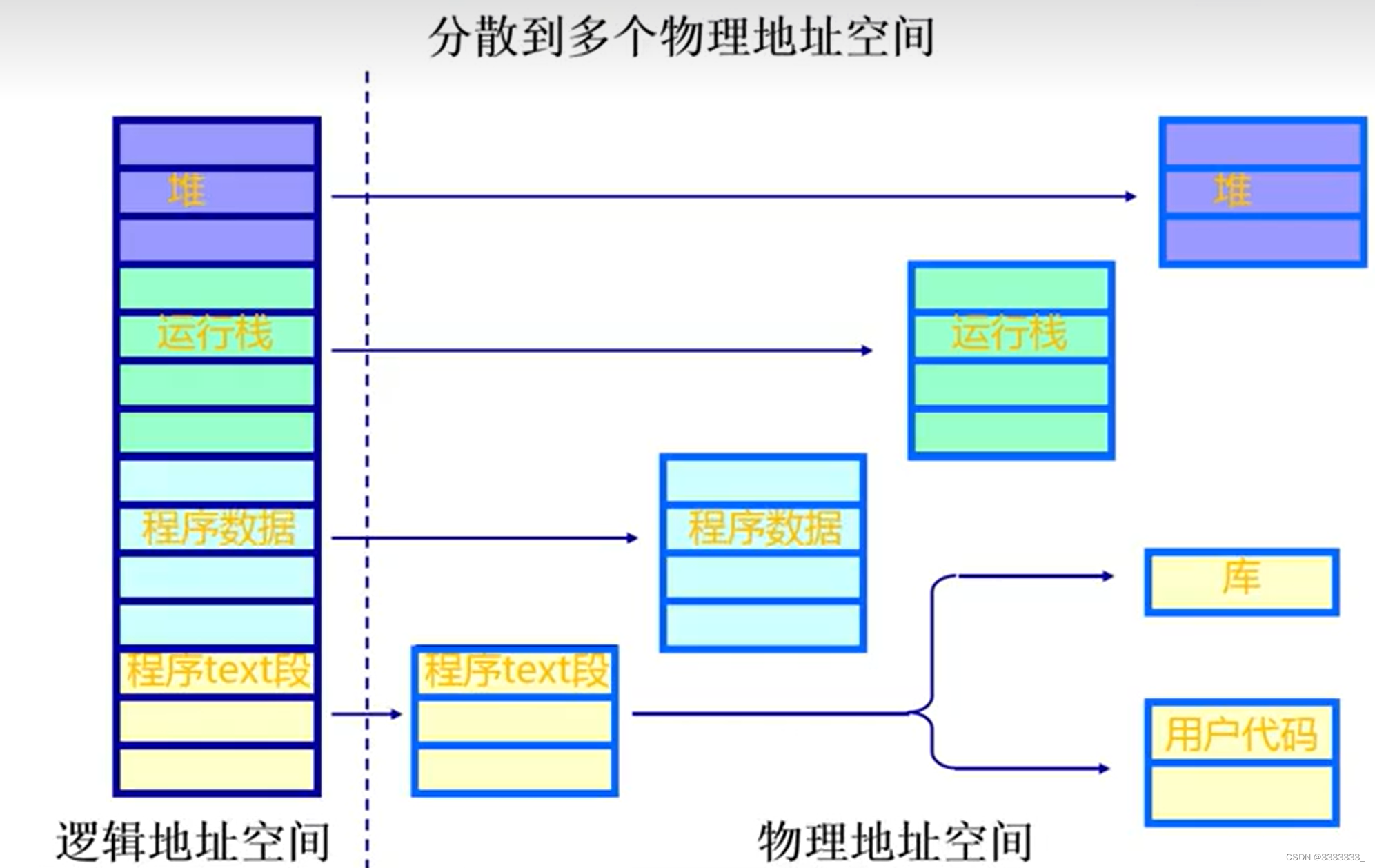
上图可以看出,从应用程序的编写或者运行来说,它的虚拟的逻辑地址空间是连续地址空间,虽然说它是连续空间,通过分段之后,可以把它隔离开来。
上图左边,把堆栈放在一个特定的地址,用一个特定的管理权限把它管理起来,把它运行的数据、栈、库还有程序的代码段以及一些特殊的其它代码段,都给他相应的分离出来。
好处:让用户代码段和主程序段共享,相互之间访问,可以让有些数据之间相互隔离,有些数据是可以读写的,另外一些是只读的,而且他们位于不同的区域。这样可以更有效的对他进行管理和分配。
上图左边是连续的逻辑地址,右边是不连续的物理地址。中间就需要映射机制,来把他相互之间建立好对应的关联。
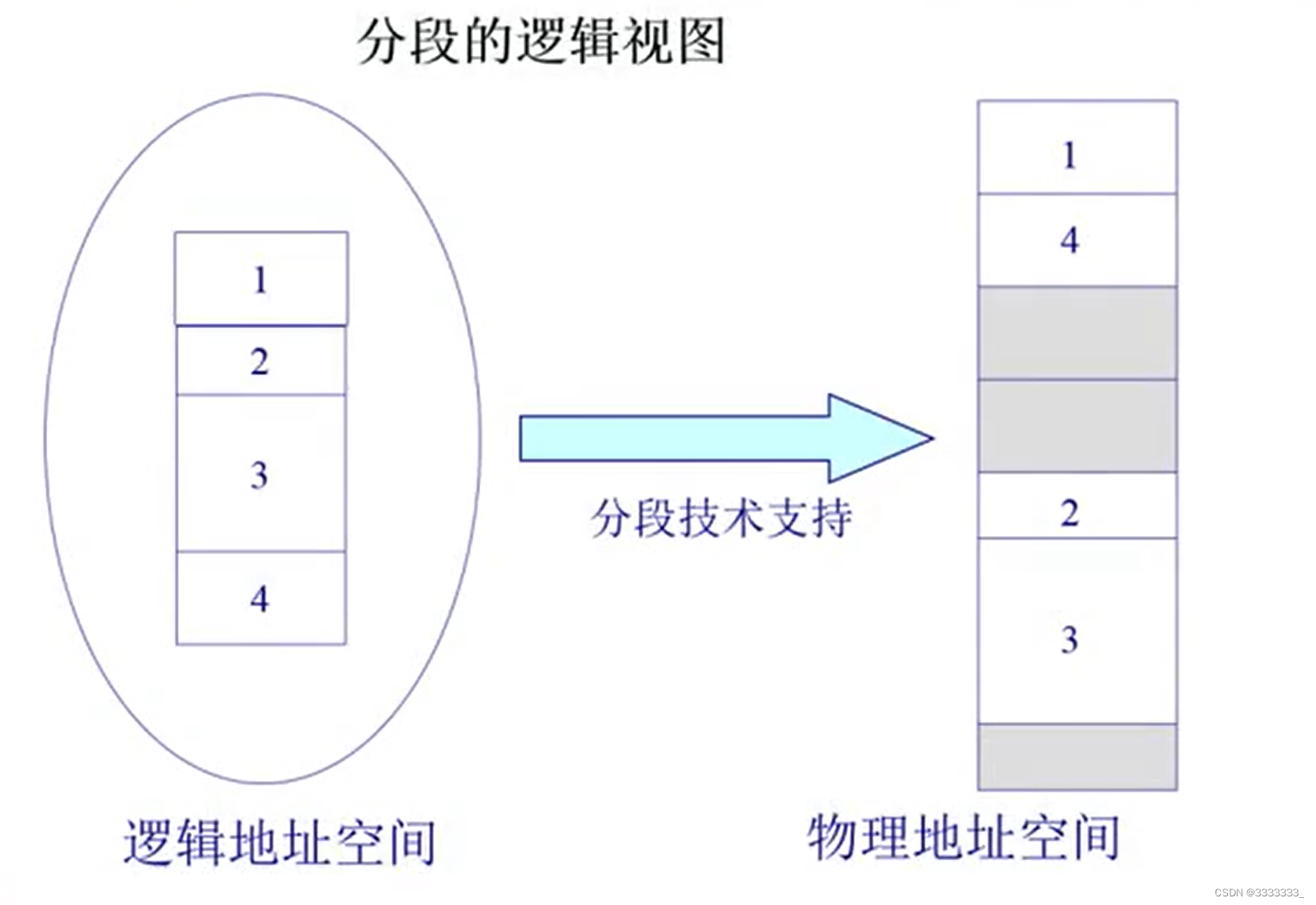
如上图,可以把左边运行的程序的逻辑地址空间看成一个连续的一维的线性数组,一个大的连续字节流。通过段机制的映射,应该可以说把不同的内存块,比如说代码、数据、堆、栈分别映射到不同的物理内存的段中去,
上图左边1 2 3 4是连续的,但是映射到物理内存之后呢,第一它们大小不一样,第二它们位置也不一样,这个中间的映射关系就是通过段管理机制来实现的。
当然这种机制也可以用软件来实现,对于每一次内存访问,都需有通过软件来映射,开销是很大的。所以需要通过硬件来支持。
怎么通过硬件来支持分段寻址?
地址怎么表示?
程序看到的很简单,都是一维的逻辑地址。一维逻辑地址怎么和分段的物理地址对应呢?
一维的逻辑地址是由不同的段组成的,而这个段可以不连续。那能不能把这个一维的逻辑地址分成两块,一块是段的寻址,另一块是段内偏移的寻址,分成这两部分。
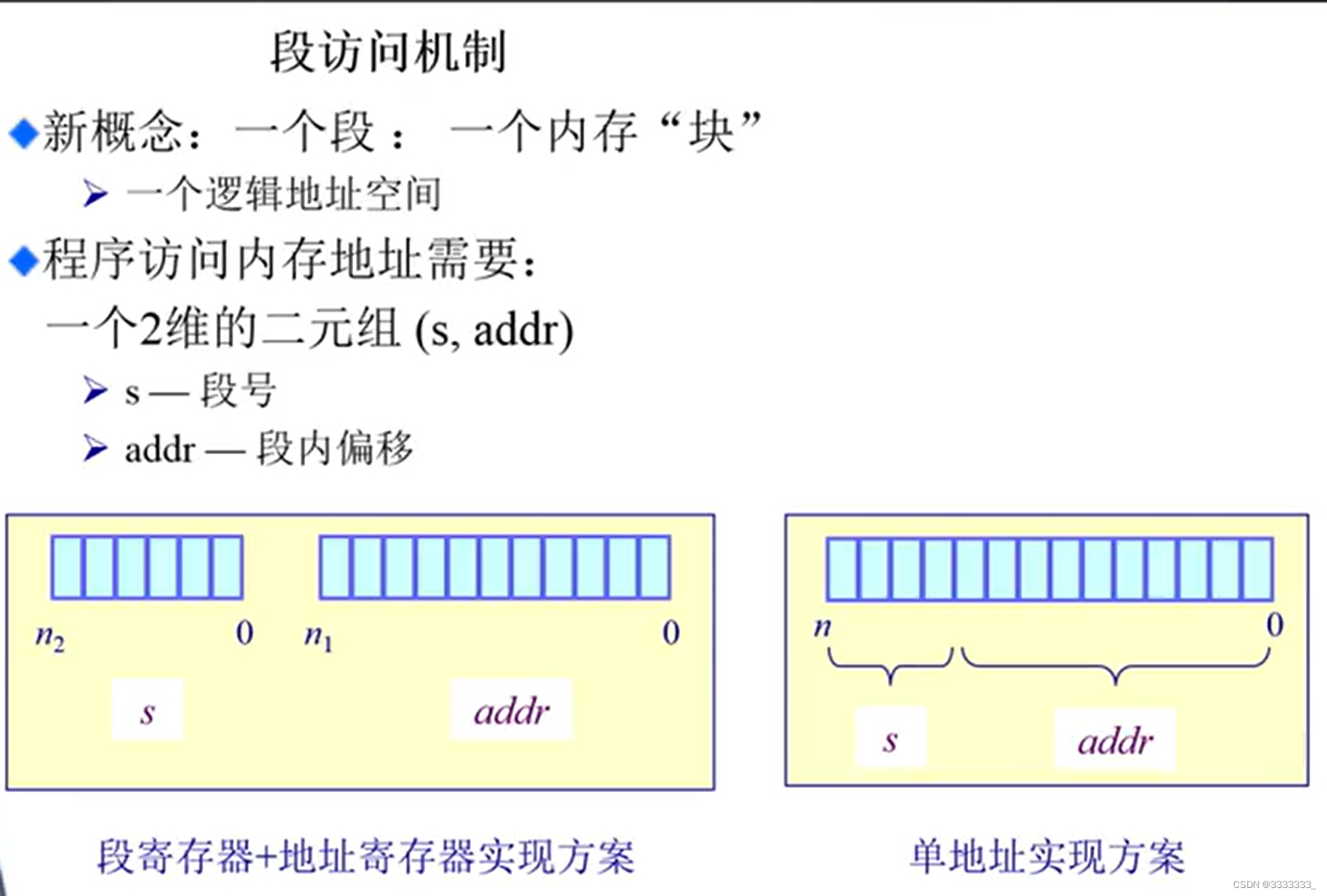
有一个段号,段内有个地址叫address,这两部分组成在一起就形成了以段机制为管理方式的寻址方式,
这种寻址方式又区分出两种情况,
1 如果说我们段的段号和offset地址是分开的,形成段寄存器+地址寄存器的寻址方式。比如我们X86
2 另一种就是把段和段内偏移合在一起形成一个完整的地址,有一个专门的段寄存器概念,来把这个段的编号单独管理起来,这种方式是单地址管理方式。
上述两种方式都可以存在。
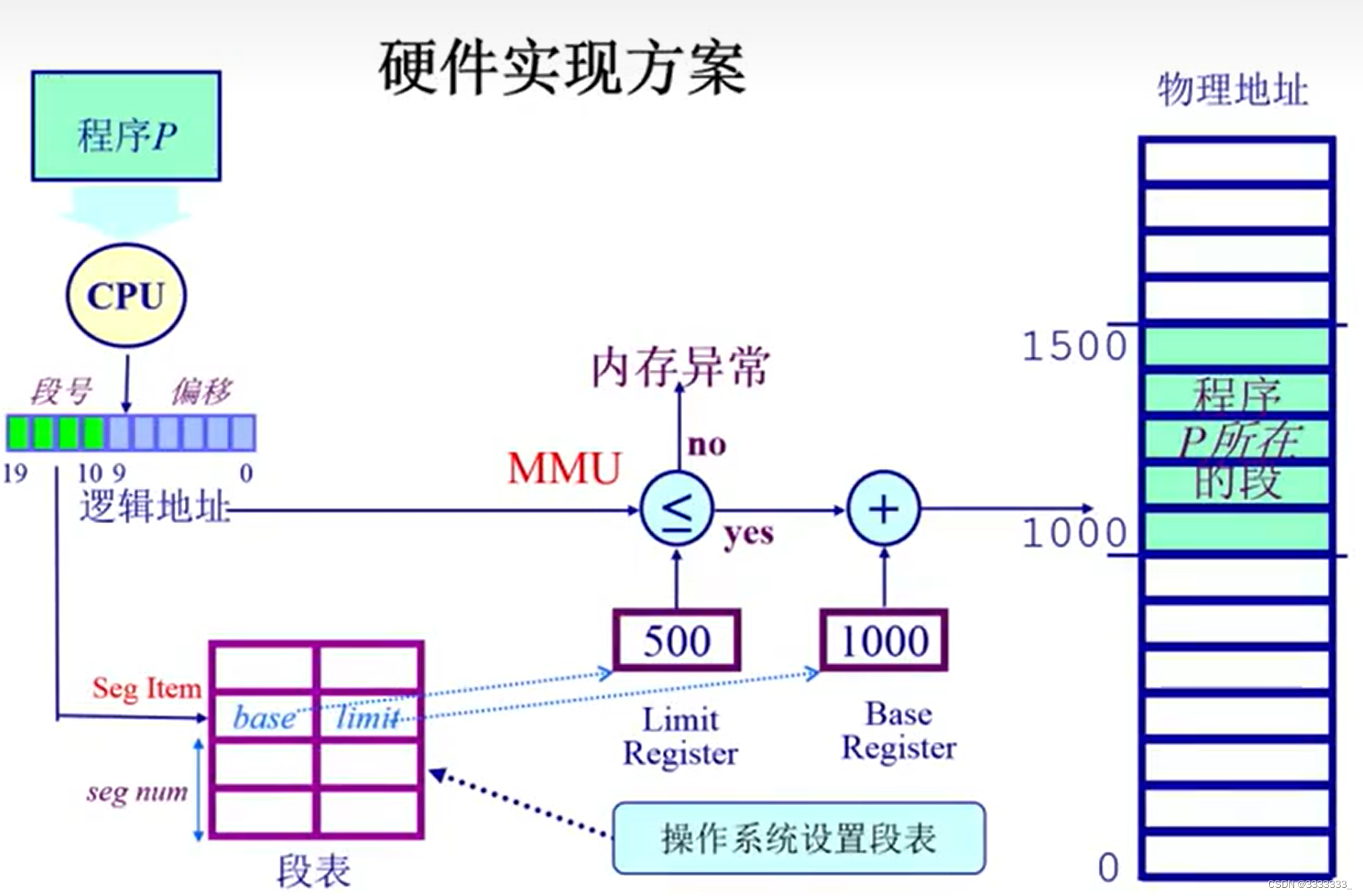
PS:上图右边基地址标错了,应该把1000改成500 或者是base和limit的箭头互换
如果有硬件支持后,怎么把段管理机制建立起来?也就是从我们的一维线性逻辑地址空间能够通过这个端管理机制映射到不同的物理地址空间去,而这个物理地址空间是由不同的端组成的,这是想通过上图做出的说明
上图从左边开始看,左上角是一个可运行的应用程序,那么通过CPU来执行每条指令,那么CPU就要去寻址,比如说找到数据在什么地方,代码在什么地方。这个地址可以采用单一的段地址管理机制,把一个逻辑地址分成两块,它的上半部分可以理解是段号,下半部分是段内的偏移
首先看段号,通过段号希望能找到这个段所在物理内存的其实地址,这是需要去了解的,这个信息怎么去保存?需要有硬件机制,称之为段表,segment table,段表里面真好存着映射关系,什么映射关系呢,就是逻辑地址的段号和物理地址段号的对应关系,
第二呢,每个段的大小是不一样的,需要去了解这个段起始地址是多少,长度的限制是多少,这个信息也是放在段表里面的,意味着在段表里面有两个很重要的信息,1:段的起始地址,2段的长度的限制。
那么这个段表里面的index称之为段表的索引,每一项,这个段表项,索引项,就是由段号来决定的,这个段号就决定了在段表中哪一项的位置,就是所谓的index,实际上就是segment num,这两个是完全一样的。
通过这个segment num 把它作为segment table的index,就可以找到对应段的项,找到这个项之后,自然就知道这一项所代表的段它在物理内存中的起始地址以及长度限制在什么地方,查出这个信息之后呢,CPU会去做一个比对,什么比对呢,看一看它这个段的限制,是他本身这个表示的地址,是否满足这个限制(对应上图MMU附近的圆圈判断处),如果说满足这个限制,就意味着是合法地址。反之则非法访问,会根据前面的异常机制,这时候CPU会产生异常,交给操作系统去处理,它来决定程序是不是有问题了,有问题就Kill掉。
一般情况下这个地址都是合理区间内的,继续往下走,把这个起始地址加上它前面的逻辑地址的offset,形成一个物理地址,当形成物理地址之后呢,根据这个地址查找它在物理内存中的位置,把相应的数据给取出来,交给CPU做进一步处理,这是一个基于硬件的分段管理机制。
这里面CPU为了完成寻址做了很多工作,这里面段表是由操作系统建立,在正式寻址之前操作系统建立好段表,建立好段表之后,段机制就可以正常工作了,至于怎么建立段表,和硬件是由很紧密的联系。后续实验环节再做讲解。
由逻辑地址知道段号,有了段号就可以知道相应的物理地址段的起始地址,逻辑地址那里还能知道偏移地址,有偏移地址就可以知道在物理内存段的偏移量,最终找到那个物理地址。

















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









