



AutoOcc
[未开源]AutoOcc: Automatic Open-Ended Semantic Occupancy Annotation via Vision-Language Guided Gaussian Splatting
Abstract
- 本文提出了一种自动化的开放语义占据注释方法,该方法通过视觉-语言模型对特征图进行引导,以生成语义占据注释。
- 设计了语义感知的高斯作为中心几何描述符,并且提出了一种累计高斯-体素的拼接算法,从而实现了有效且高效的占位注释。
Introduction
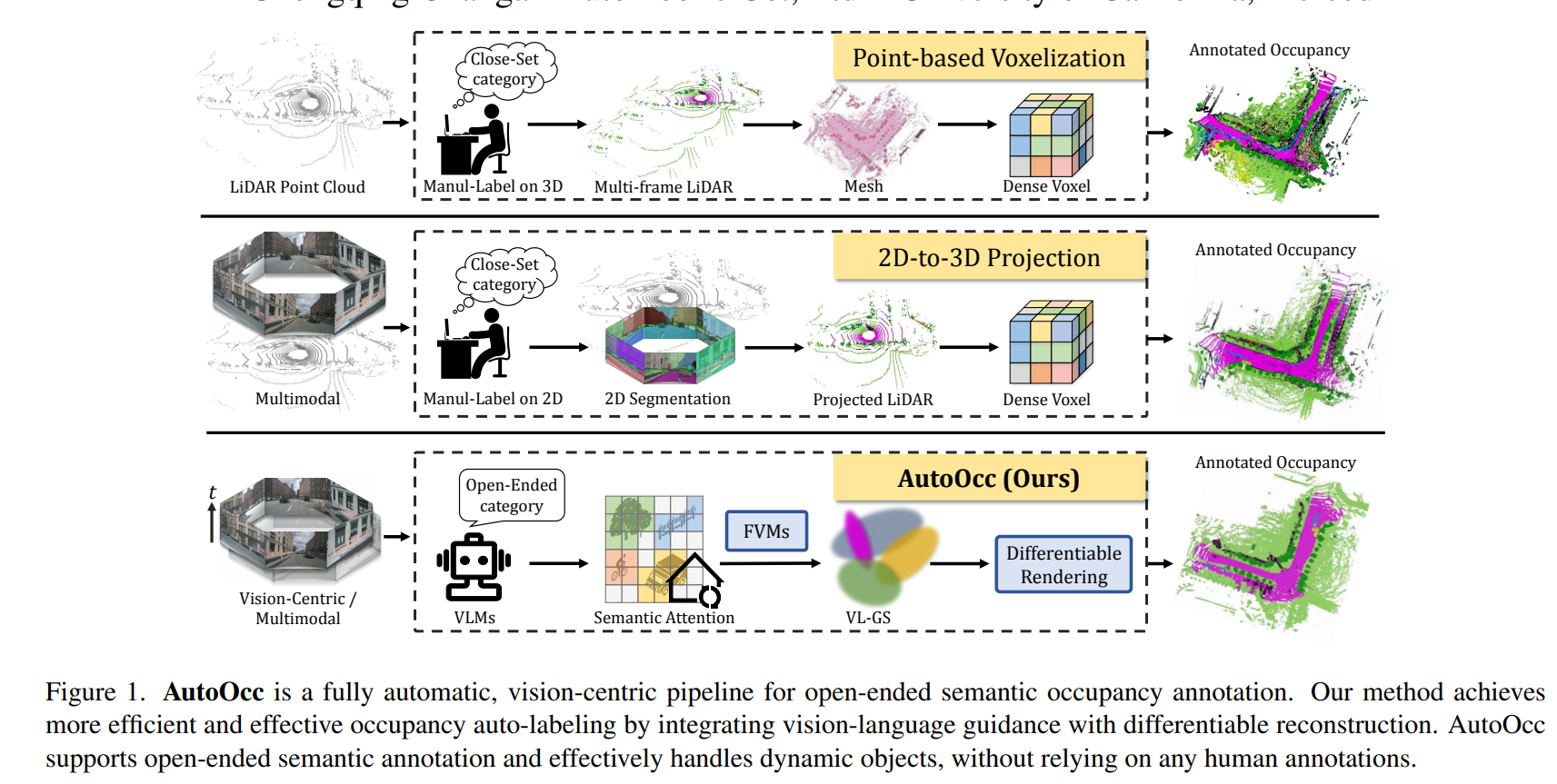
目前的自动或半自动Occ标注主要遵循以下三种路径:(1)自动辅助人工标注,耗费大量人力和财力。(2) 以人工标注先验为指导的点云体素化,严重依赖人工先验和多阶段后处理,耗时耗力。(3) 基于二维到三维投影的方法,简单地将二维分割结果合并为三维点云或网格,难以确保精确的三维一致性。
这些标注方法严重依赖于激光雷达点云,却忽略了多视角图像中的语义和几何线索。由于激光雷达点云本身稀疏且不完整,因此不足以进行全面的场景建模。这些方法还采用基于体素的场景表示法,需要过多的参数和冗余的计算成本。最近的自监督Occ模型通过利用来自图像输入的二维特征和来自视觉基础模型(VFM)的语义信息,如SAM和OpenSeed,消除了对大量标记训练数据的需求。然而,这些方法难以确保完整、一致的场景,而且在不同场景中的泛化能力有限。
此外,这些方法都局限于闭集或需要预定义的类别。然而,现实世界的场景往往涉及开放式占用–任何预定义类别之外的物体,因此将所有未定义的语义标记为 "其他 "是不明智的。例如,自动驾驶车辆可能会遇到倒塌的电线杆或路面上的塑料板,这些都需要不同的占用注释来制定安全驾驶策略。
为了解决这些局限性,我们提出了 AutoOcc,这是一个用于开放式语义Occ标注全自动化框架,既不需要人工标注,也不需要预定义类别。为了实现开放式语义占位标注,我们采用了由视觉语言模型(VLM)生成的语义注意图来描述场景,从而构建了一个不断发展的语义查询列表。生成的注意力地图可同时用于,以促使在 SAM 中进行分割,并指导实例级的搜索。通过 UniDepth 进行深度估计,从而消除了人工注释的需要。
我们进一步引入了自估算流模块,以识别和管理时空渲染中的动态对象。我们进一步提出了具有开放式语义意识的高斯泼溅作为中间表征形式,从而提供更全面的建模、更高的时空一致性,以及更精细的几何图形和更少的基元。与经过致密化处理的点云和体素相比,VL-GS 具有更高的表示效率、更高的精度和更低的内存消耗。语义Occ标注然后通过累积高斯到体素拼接自动生成端到端注释。
Method
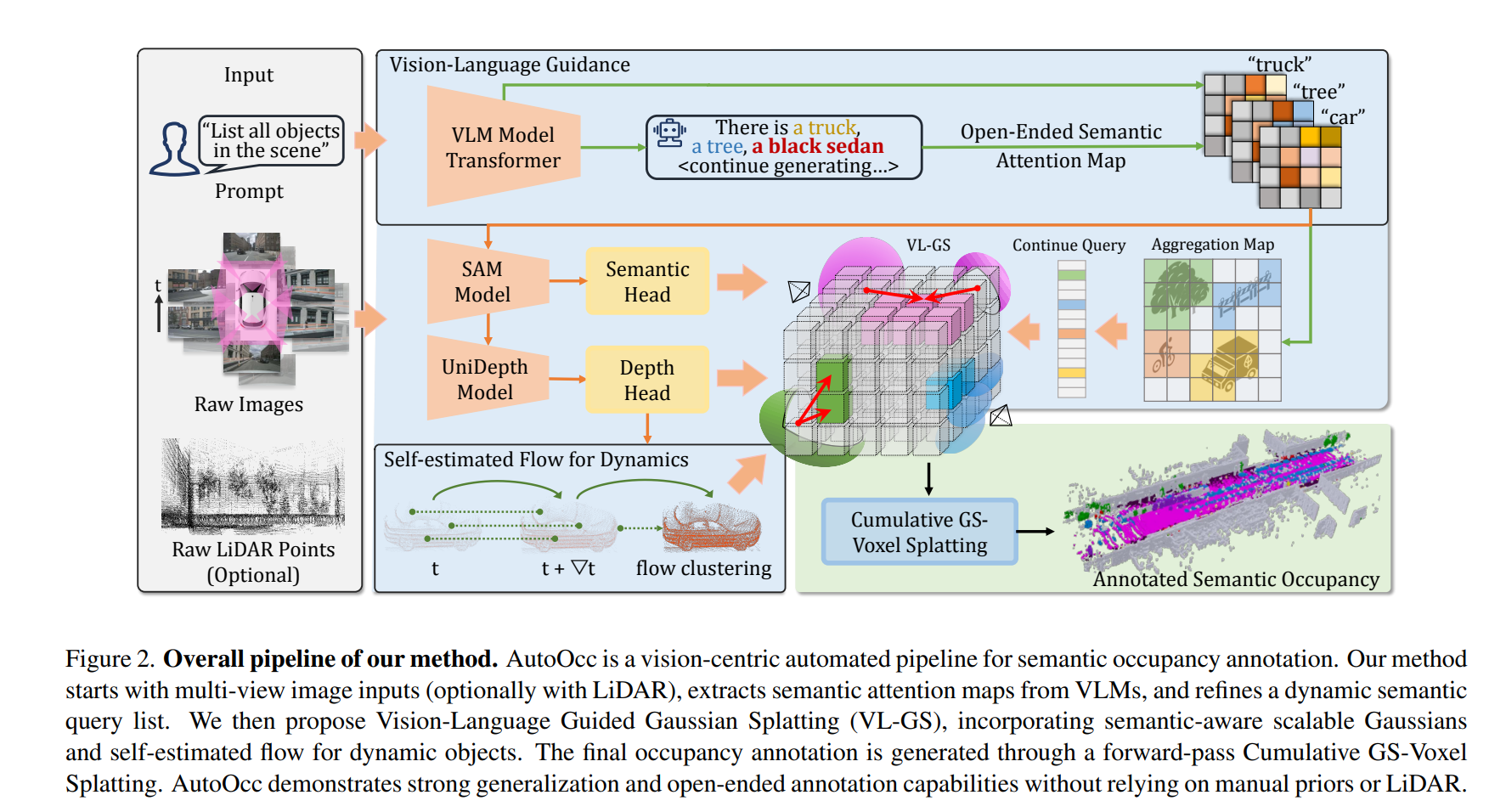
Vision-Language Guidance
视觉-语言大模型或视觉基础大模型大多还应用于2D场景中,而在处理多模态数据交互或多视角一致性方面往往效果不佳,此外这些模型还缺乏对于整个三维空间的完整性的理解。为此我们提出了一个以语义注意力地图引导的框架,并且通过场景重建来解决模糊问题,从而保持三维语义和几何的一致性。
-
Semantic Attention Map
我们利用语义注意地图,在语义层面整合并引导从视觉语言模型中获取所需的先验知识。对环视多视角图像的对应的transformer decoder的输出进行计算和聚合。然后,我们将与这些语义类别相对应的注意力地图栅格化为二维特征地图,每个类别由一个聚合注意力地图 M 表示。 -
Attention-guided Visual Prior
利用语义注意力地图包含了与类别相关的视觉线索指导生成在语义上对齐的mask和深度信息。
将类别语义对应的prompt输入到现有的分割模型中,在对应RoI内选取最大置信度的结果作为语义类别的精细化mask。此外,利用语义注意力地图引导深度估计模型,将前景与背景目标进行解耦,同时i排除天空区域的无限距离干扰。然后,我们利用语义注意力线索,从多视角图像中特定RoI的关联性,利用像素产生一组伪三维点云从而汇总出深度信息。
VL-GS
尽管充分利用了大模型的先验知识,但3D Occ标注仍存在以下问题:1) 多视角的语义冲突使得简单的二维到三维投影容易出现错位和模糊;2) 深度估计错误导致三维空间的几何失真;3) 动态物体破坏了语义和几何的空间和时间一致性。
为了解决这些问题,我们提出了一个视觉语言引导的高斯泼溅(VL-GS)模块,可以有效的重建整个场景,通过将注意力先验和可微分渲染相结合,实现语义和几何三维一致性。
VL-GS 的核心是语义感知可扩展 GS,由来自视觉语言模型的语义注意图引导。在重建过程中,VL-GS 会在实例层面消除二维语义的模糊性,并优化物体的几何细节。我们还引入了一个
流预测模块,利用时间感知动态高斯来捕捉和重建动态物体。然后,三维语义占位可通过累积的数据完成自动标注。
-
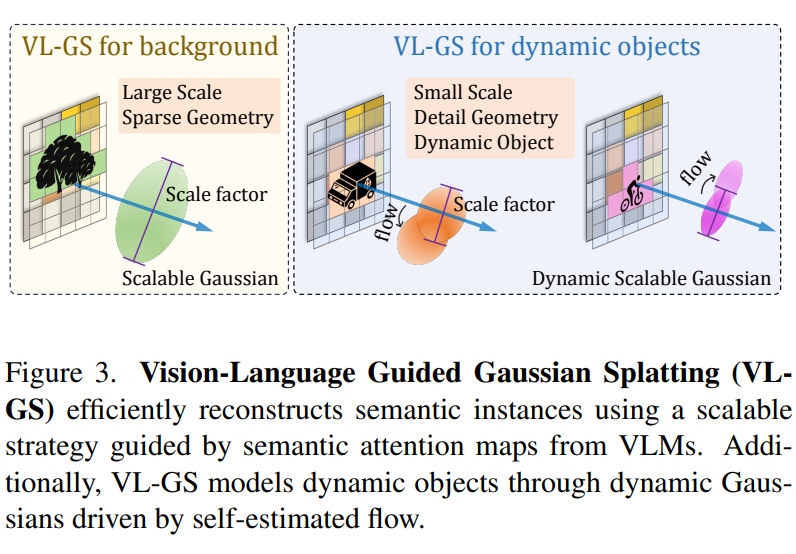
Semantic-aware Scalable Gaussian
不同语义对象在场景中占据着不同的权重比例,本文设计一种语义感知的可扩展高斯,它能自适应地扩展和重建不同语义的对象。与稠密的体素或点云不同,我们的方法允许用稀疏的高斯来表示RoI,并通过可扩展性和语义关注图提供帮助。
依据于语义注意图,为每个高斯分配一个语义属性和对应的缩放因子,采用α\alphaα-混合:
Γi=∑i=1Nsoftmax(γi)αi∏j=1i−1(1=αj)Γ_i = \sum \limits_{i=1}^N\text{softmax}(\gamma_i)\alpha_i\prod _{j=1}^{i-1}(1=\alpha_j)Γi=i=1∑Nsoftmax(γi)αij=1∏i−1(1=αj)
缩放因子需要与每个高斯所占据的空间成线性关联,但由于各向异性形状和空间重叠的变化,不能简单地从高斯中心位置计算,因此,,我们通过考虑从高斯椭圆体的最近切面到体素的距离来估算每个高斯占据的范围:
d=oz−η−1∑0,2−1(ox−kx)+η−1∑1,2−1(oy−ky)∑2,2−1d = o_z - \frac{η^{-1}\sum^{-1}_{0,2}(o_x-k_x) + η^{-1}\sum^{-1}_{1,2}(o_y-k_y)}{\sum^{-1}_{2,2} }d=oz−∑2,2−1η−1∑0,2−1(ox−kx)+η−1∑1,2−1(oy−ky)
其中,d是体素到高斯椭球体的占据深度,η是从体素中心到高斯中心的射线方向,Σ 是协方差矩阵,高斯值G(x)可以表示为:
G(x)=e−12(k−o)T∑−1(k−o)G(x) = e^{-\frac{1}{2}(k-o)^T\sum^{-1}(k-o)} G(x)=e−21(k−o)T∑−1(k−o)
然后,根据高斯值梯度和高斯所占范围,对缩放因子进行自适应调整。如图所示,语义感知的可缩放高斯可以用较大尺度的稀疏高斯来表示较大的背景区域(如建筑物),同时用较小尺度的较密集高斯来捕捉较精细的几何图形(如骑自行车的人)。
-
Self-estimated Flow for Dynamic Objects
动态对象可能会因时间变化而产生拖尾效应,从而降低Occ标注的准确性。独立处理动态对象有助于提高语义的时空一致性。因此,我们引入了一个三维流自估计模块,用于捕捉和聚合动态对象。我们还将动态属性分配给动态高斯,以更好地模拟物体的运动。
对每个高斯核p依据序列时间段内的平移建模为流向量f,并利用最小化时序下匹配点间倒角距离来估计流向量。由于相同的动态对象通常由具有相同语义的空间相邻高斯来表示,因此我们在具有相同语义的最近高斯邻域中搜索配对点之间的对应关系:
CD(p,p′)=∑p∈U1minp′∈U2∣∣p−p′∣∣22+∑p∈U2minp′∈U1∣∣p′−p∣∣22CD(p, p^{'})=\sum \limits_{p \in U_1} \min \limits_{p^{'} \in U_2}||p - p^{'} ||^2_2 + \sum \limits_{p \in U_2} \min \limits_{p^{'} \in U_1}||p^{'} - p||^2_2 CD(p,p′)=p∈U1∑p′∈U2min∣∣p−p′∣∣22+p∈U2∑p′∈U1min∣∣p′−p∣∣22
其中 (p,p′)(p, p^{'})(p,p′)为不同时间下具有相同语义的高斯核的位置,并以此判断是否为动态对象。 -
Geometric constraints from LiDAR
利用叠帧的点云。计算出目标的锚定中心,并强制将高斯椭球体的分布与对应语义区域的几何先验对齐:
Lgeo=−∑c=1C∑i=1M1∣∣oc(i)−pc(i)∣∣22L_{geo} = -\sum \limits_{c=1}^{C} \sum \limits_{i=1}{M} \frac {1}{||o_c(i) - p_c(i)||^2_2}Lgeo=−c=1∑Ci=1∑M∣∣oc(i)−pc(i)∣∣221 -
Cumulative GS-Voxel Splatting
最后,我们将 VL-GS 以任意体素大小累积拼接到体素网格上,每个体素的语义标签通过对高斯所占范围和不透明度的加权来确定:
F(o)=∑i=1NdiG(xi)αisoftmax(γi)F(o) = \sum \limits_{i=1}^{N}d_iG(x_i)\alpha_i\text{softmax}(\gamma_i) F(o)=i=1∑NdiG(xi)αisoftmax(γi)
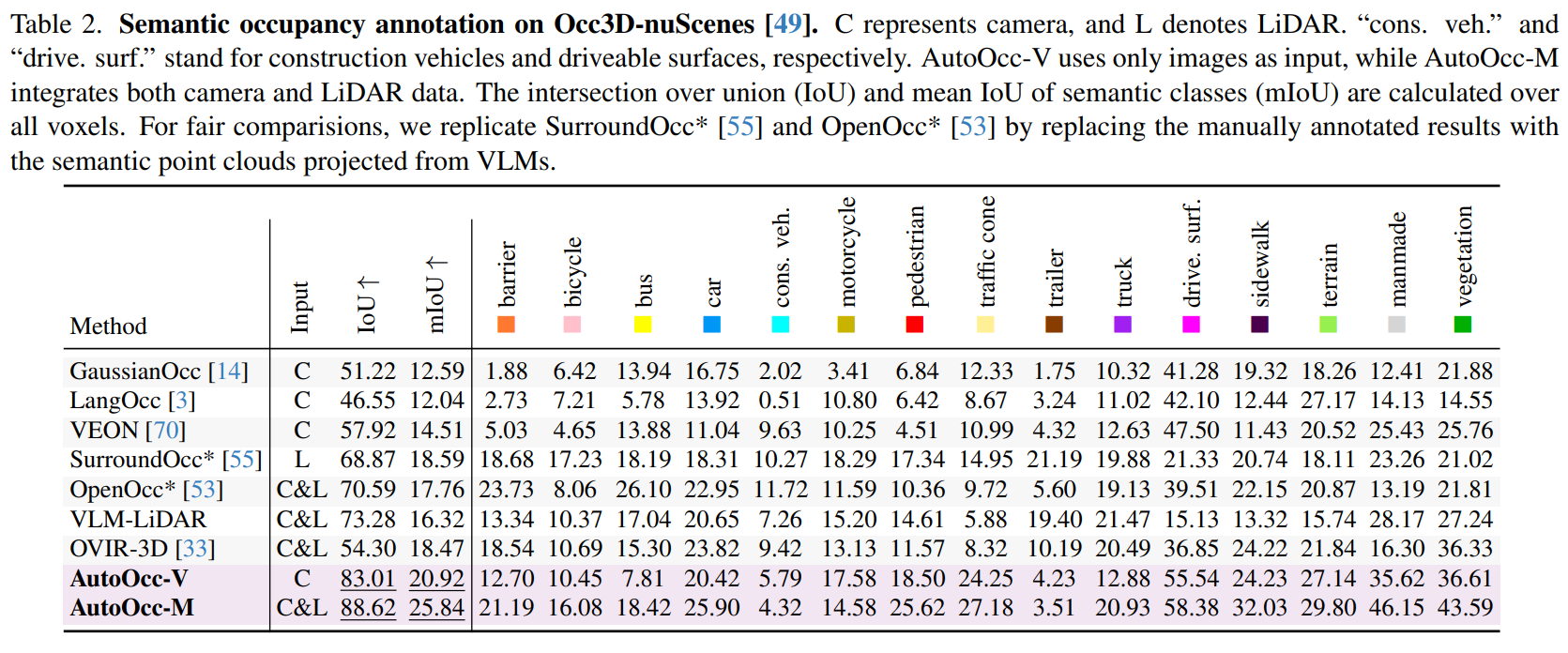
Experiment
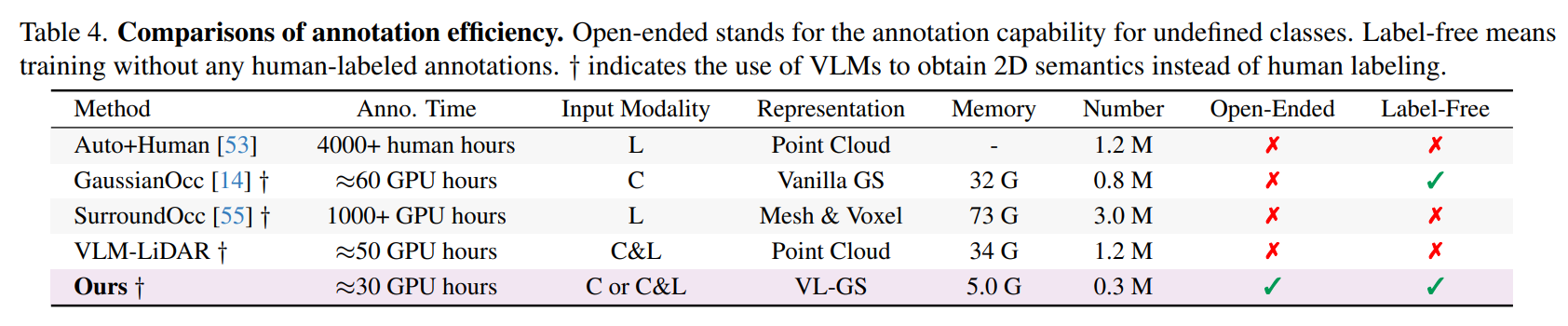

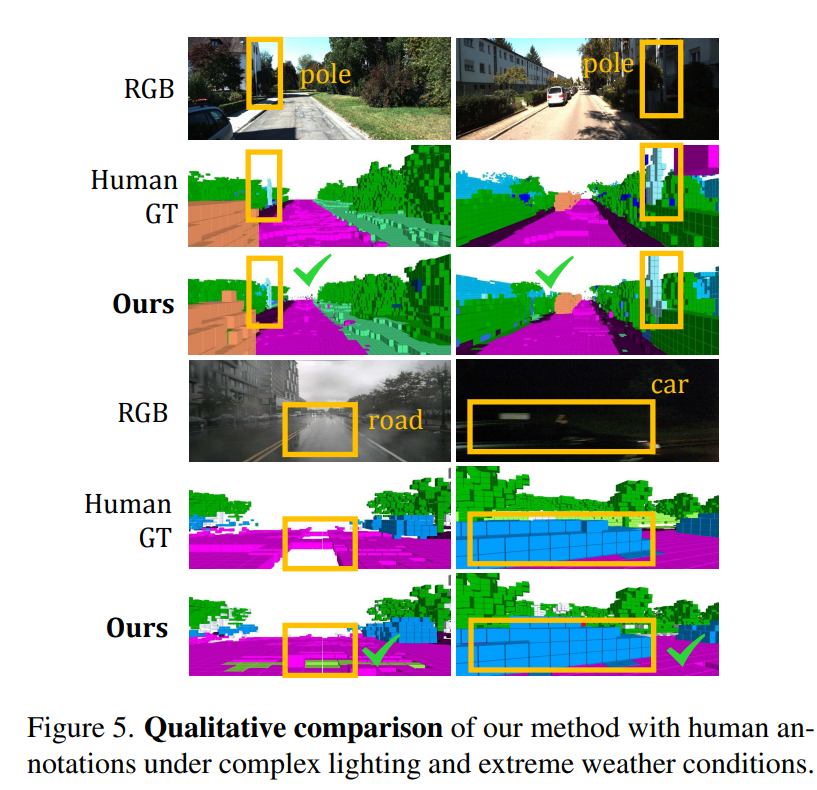

















 1233
1233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









