










点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-30-新发布【1T 万亿】参数量大模型!Kimi‑K2开源大模型解读与实践,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年07月28日更新到:
Java-83 深入浅出 MySQL 连接、线程、查询缓存与优化器详解
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
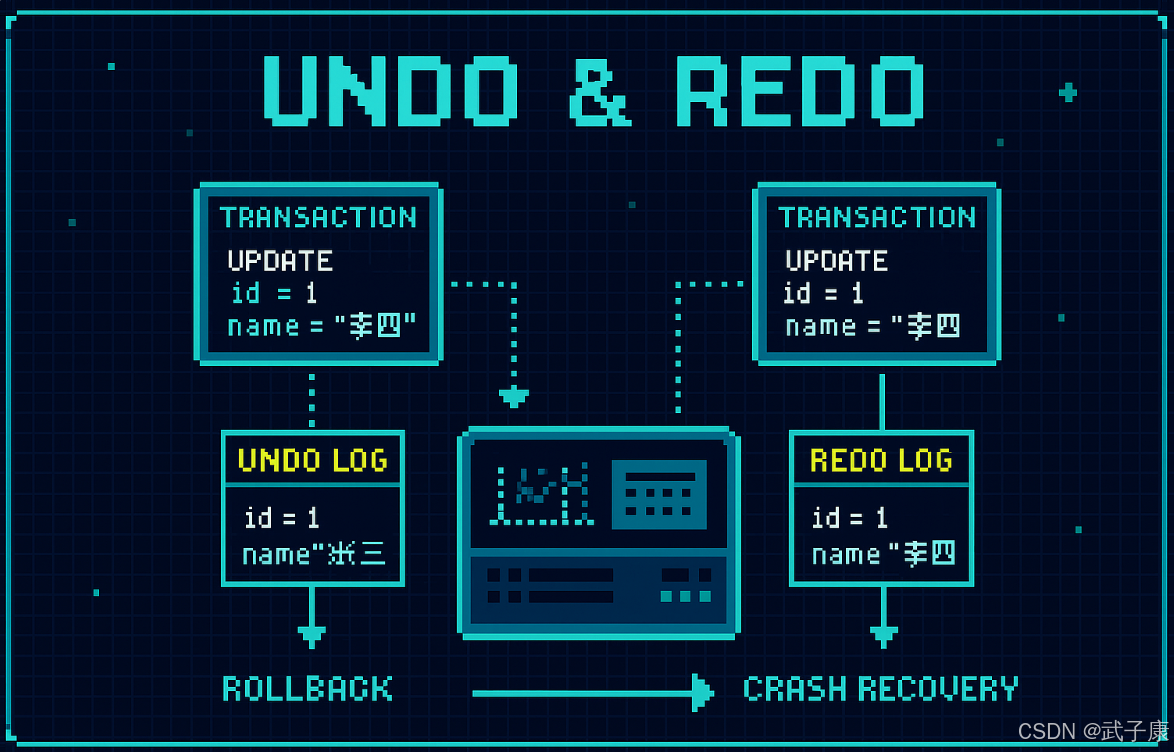
Undo Log
基本介绍
Undo 概念
● Undo(撤销操作):指在数据库系统中撤销已执行操作的功能,使数据恢复到之前的某个状态。例如在MySQL中执行了错误的UPDATE语句后,可以通过回滚事务来撤销这次修改。
Undo Log 工作原理
● Undo Log(回滚日志):是数据库事务管理的关键组件,其工作流程包括:
- 事务开始前,系统会将要修改的数据页的原始值记录到Undo日志中
- 如果事务需要回滚,系统会根据Undo日志中的记录将数据恢复到事务开始前的状态
- 在数据库崩溃恢复时,未提交事务的修改也会通过Undo日志进行回滚
Undo Log 生命周期
● Undo Log的生命周期管理:
- 生成时机:在事务开始执行任何DML操作前生成
- 提交处理:事务提交时不会立即删除,而是放入删除列表
- 回收机制:通过后台的purge线程异步清理,这个设计是为了支持MVCC(多版本并发控制)
- 保留时间:根据系统配置,Undo日志可能会保留一定时间以支持长时间运行的事务
Undo Log 类型
● Undo Log作为逻辑日志的特点:
- 对于INSERT操作:记录对应的DELETE操作
- 对于DELETE操作:记录完整的行数据(包括所有列值)
- 对于UPDATE操作:记录修改前的旧值
- 示例:UPDATE users SET name=‘张三’ WHERE id=1,对应的Undo Log会记录id=1的记录原来的name值
Undo Log 存储结构
● Undo Log的物理存储架构:
- 采用段式管理:InnoDB使用回滚段(Rollback Segment)组织Undo日志
- 默认配置:每个数据库实例包含128个回滚段(MySQL 8.0+)
- 段结构:每个回滚段包含1024个Undo槽(Undo Slot)
- 事务分配:每个事务会根据需要分配一个或多个Undo Slot
- 存储文件:Undo日志默认存储在系统表空间的回滚段中,也可以配置为独立的Undo表空间
Undo Log 与事务的关系
● 事务隔离级别的实现依赖:
- 读已提交(RC)和可重复读(RR)隔离级别都依赖Undo Log实现多版本控制
- 长事务会导致Undo Log堆积,可能引发性能问题
- 大事务可能导致回滚段扩展,需要合理设计事务范围
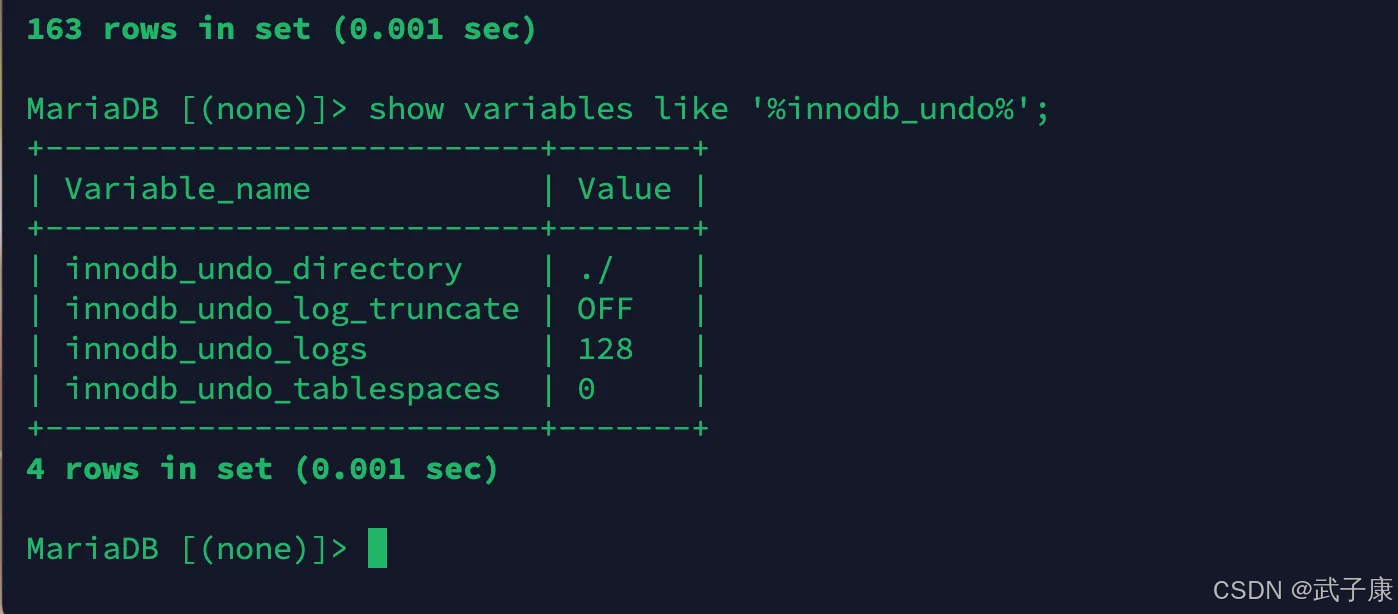
测试样例
show variables like '%innodb_undo%'
执行结果如下所示:
Undo Log 作用
事务原子性
Undo Log(回滚日志)是 MySQL 实现事务原子性(Atomicity)的核心机制之一。在事务处理过程中,如果发生以下情况:
- 执行过程中出现系统错误
- 用户显式执行 ROLLBACK 语句
- 死锁检测机制触发事务回滚
MySQL 就可以利用 Undo Log 中记录的数据变更前镜像(before image)将数据恢复到事务开始前的状态。具体实现过程包括:
- 事务开始时,系统会分配一个唯一的事务ID
- 每次执行DML操作(INSERT/UPDATE/DELETE)前,都会先将修改前的数据记录到Undo Log
- 回滚时,按照LIFO(后进先出)顺序应用Undo记录
例如:假设事务T1要更新某行数据(id=1)的name字段从"张三"改为"李四",Undo Log会先记录"id=1,name=张三"的旧值。如果事务回滚,就根据这个记录恢复原值。
并发控制
Undo Log 在 MySQL InnoDB 存储引擎中扮演着实现多版本并发控制(MVCC)的关键角色。其工作机制如下:
-
版本链管理:
- 每条记录都包含DB_TRX_ID(最近修改的事务ID)和DB_ROLL_PTR(指向Undo Log的指针)
- 通过这个指针可以找到所有历史版本,形成版本链
-
快照读实现:
- 当其他并发事务需要读取数据时,如果该数据正在被修改
- 系统会从Undo Log中获取事务开始时的数据快照(ReadView)
- 确保读操作不会阻塞写操作,实现非锁定读
-
隔离级别支持:
- 在READ COMMITTED级别:每次读取都会生成新的ReadView
- 在REPEATABLE READ级别:使用事务开始时的ReadView
- SERIALIZABLE级别会退化为锁定读
应用场景示例:
事务A(事务ID=100)开始后,事务B(事务ID=101)更新了某行数据。当事务A读取该行时,InnoDB会通过Undo Log找到事务ID<100的最近版本返回给事务A,从而保证事务A看到的是它开始时的一致性快照。
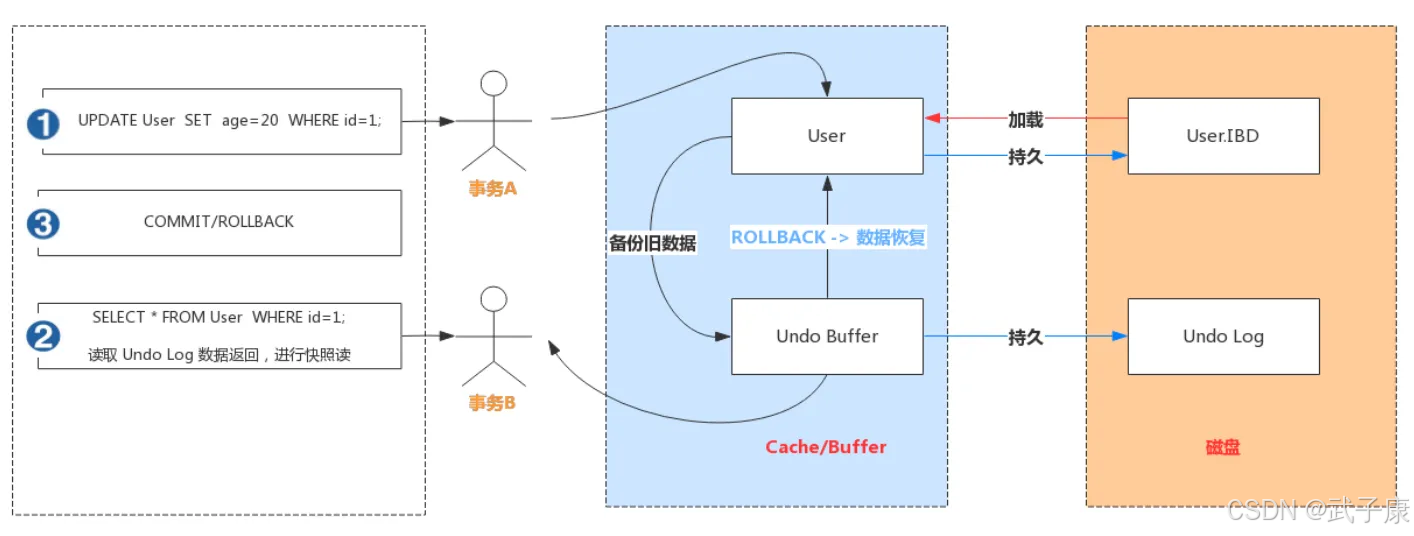
事务A手动开启事务,执行更新操作, 首先会把更新命中的数据备份到 Undo Buffer 中。
事务B手动开启事务,执行查询操作,会读取 Undo 日志数据返回,进行快照读。
Redo Log
基本介绍
Redo(重做)机制
Redo是数据库系统中用于恢复操作的重要机制,其主要目的是在数据库发生意外故障(如系统崩溃、断电等)时,能够通过重做日志来重现之前的操作,确保数据的完整性和一致性。当数据库异常终止后重启时,系统会自动执行Redo操作,将已提交事务但尚未写入磁盘的数据修改重新执行一遍。
Redo Log(重做日志)
Redo Log是记录事务中所有数据修改操作的日志文件,它保存了最新的数据修改记录。每个修改操作都会生成对应的Redo记录,这些记录包含足够的信息来重建数据修改。Redo Log的特点包括:
- 物理日志:记录的是数据页的物理变化
- 顺序写入:采用追加写入的方式,提高I/O性能
- 循环使用:采用环形缓冲区的设计
Redo Log的生成和释放过程
-
生成阶段:
- 当事务开始执行数据修改操作时,系统会实时生成对应的Redo记录
- 这些记录首先被写入内存中的Log Buffer(日志缓冲区)
- 例如:当执行UPDATE语句修改某行数据时,会生成对应的Redo记录
-
持久化阶段:
- 事务提交时,系统会将Log Buffer中的相关Redo记录批量写入磁盘的Redo Log文件
- 这个过程通常由后台线程定期执行,不一定会立即写入磁盘
- 写入策略可以通过参数innodb_flush_log_at_trx_commit配置
-
释放阶段:
- 当事务修改的"脏页"(被修改但未写入磁盘的数据页)被刷新到磁盘后
- 对应的Redo记录就不再需要用于恢复
- 这些Redo Log占用的空间会被标记为可重用,后续可以被新的Redo记录覆盖
应用场景示例:
在一个电商系统中,用户提交订单时会产生多个数据修改操作(库存扣减、订单创建等)。这些操作生成的Redo Log会确保即使系统在写入过程中崩溃,重启后仍能正确完成这些操作。
工作原理
Redo Log(重做日志)是 MySQL InnoDB 存储引擎实现事务持久性(Durability)的关键组件。其核心工作原理如下:
-
日志先行机制(Write-Ahead Logging):
- 在数据页修改前,先将对应的修改操作记录到 Redo Log
- 确保即使系统崩溃,已提交事务的修改也不会丢失
-
循环写入机制:
- Redo Log 采用固定大小的循环写入方式
- 由两个或多个预分配的文件组成(如 ib_logfile0, ib_logfile1)
- 写满后自动循环覆盖最旧的记录
-
崩溃恢复流程:
- MySQL 启动时会检查 Redo Log
- 对处于"prepare"状态但未完成的事务进行判断:
- 如果事务对应的 Binlog 已完整写入,则提交(redo)
- 如果 Binlog 不完整,则回滚(undo)
-
性能优化设计:
- 采用顺序 I/O 写入(相比数据文件的随机 I/O 更快)
- 通过 group commit 机制合并多个事务的 I/O 操作
- 默认配置下每秒执行一次 fsync 操作(innodb_flush_log_at_trx_commit=1)
应用示例说明:
当执行一个更新事务时:
- 事务开始
- 修改 Buffer Pool 中的数据页(产生脏页)
- 将修改操作记录到 Redo Log Buffer
- 根据刷盘策略将 Redo Log 写入磁盘
- 事务提交
- 后台线程择机将脏页刷入数据文件(IBD文件)
这种设计确保了即使数据库突然崩溃,重启后也能通过 Redo Log 恢复已提交但未写入数据文件的事务修改。
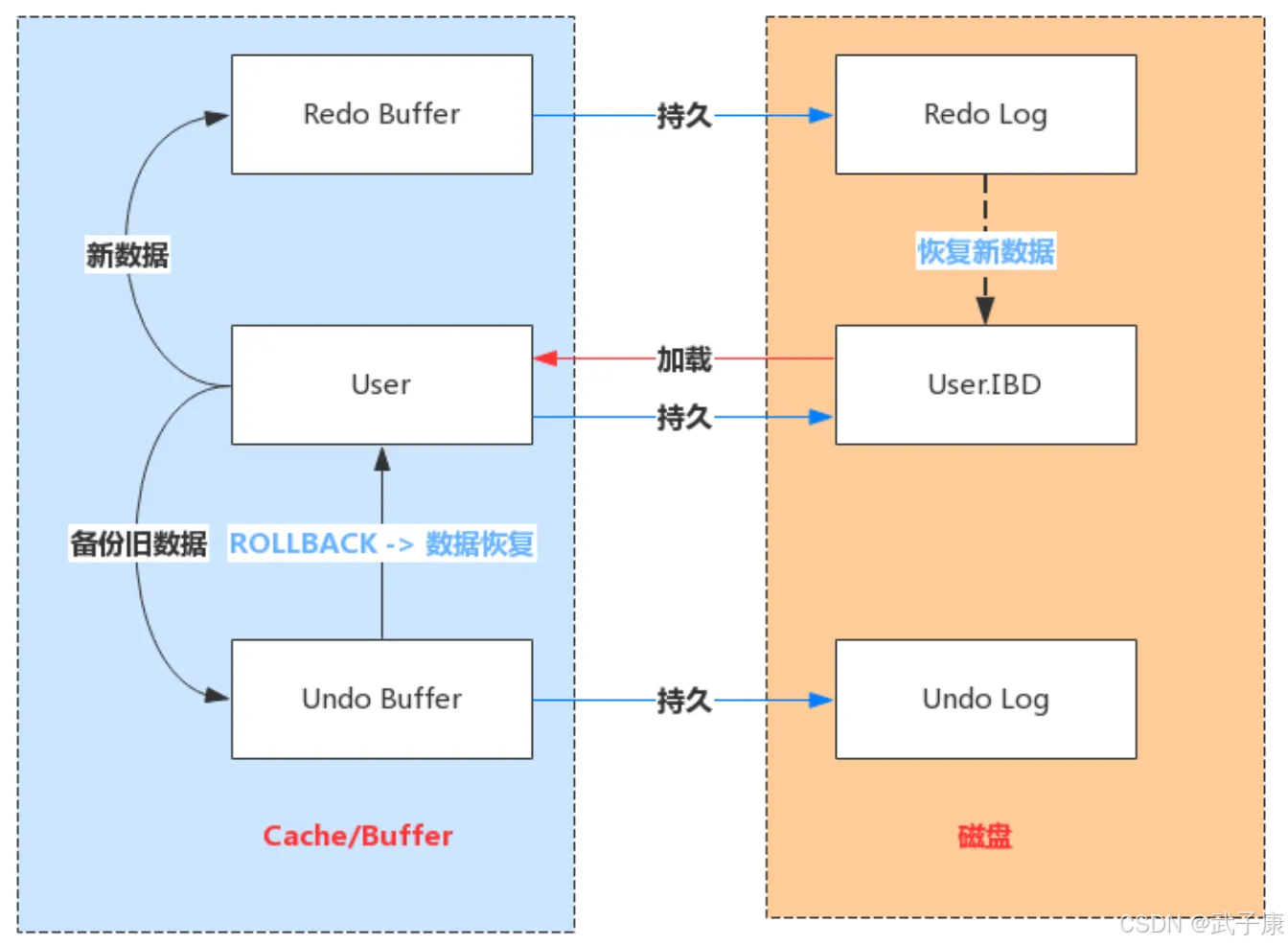
写入机制
Redo Log 文件内容是以顺序循环的方式写入文件,写满时回溯到第一个文件,进行覆盖写。
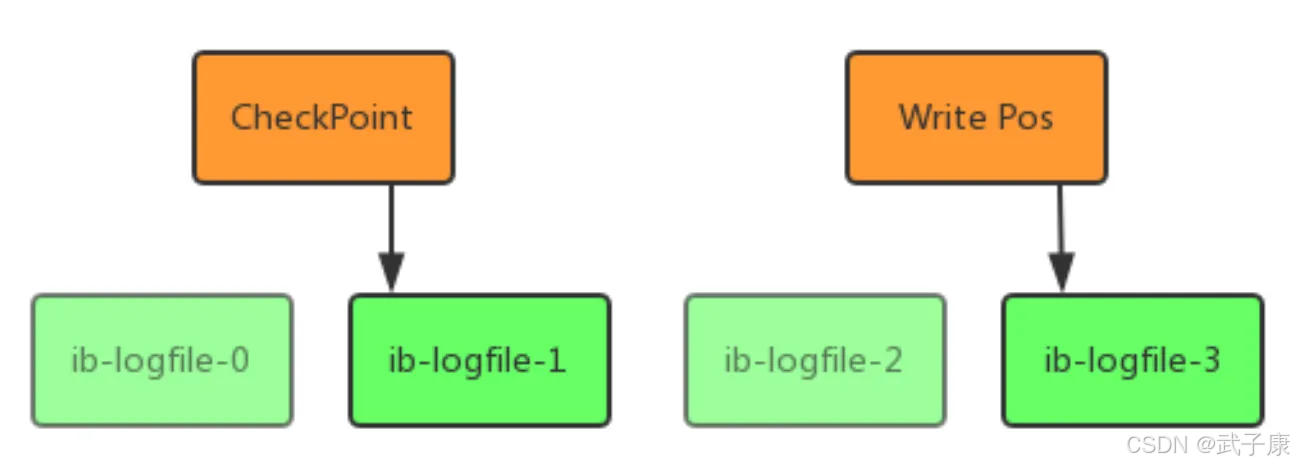
● write pos 是当前记录的位置,一边写一遍后移,写到最后一个文件末尾后就回到0号文件开头
● checkpoint 是当前要擦除的位置,也是往后推移并循环的,擦除记录前要把记录更新到数据文件
write pos 和 checkpoint 之间还空着的部分,可以用来记录新的操作。如果 write pos 追上 checkpoint,表示写满,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下。
配置参数
每个 InnoDB 存储引擎至少有1个重做日志文件组(Group),每个文件组至少有2个重做日志文件,默认为 ib_logfile0 和 ib_logfile1。
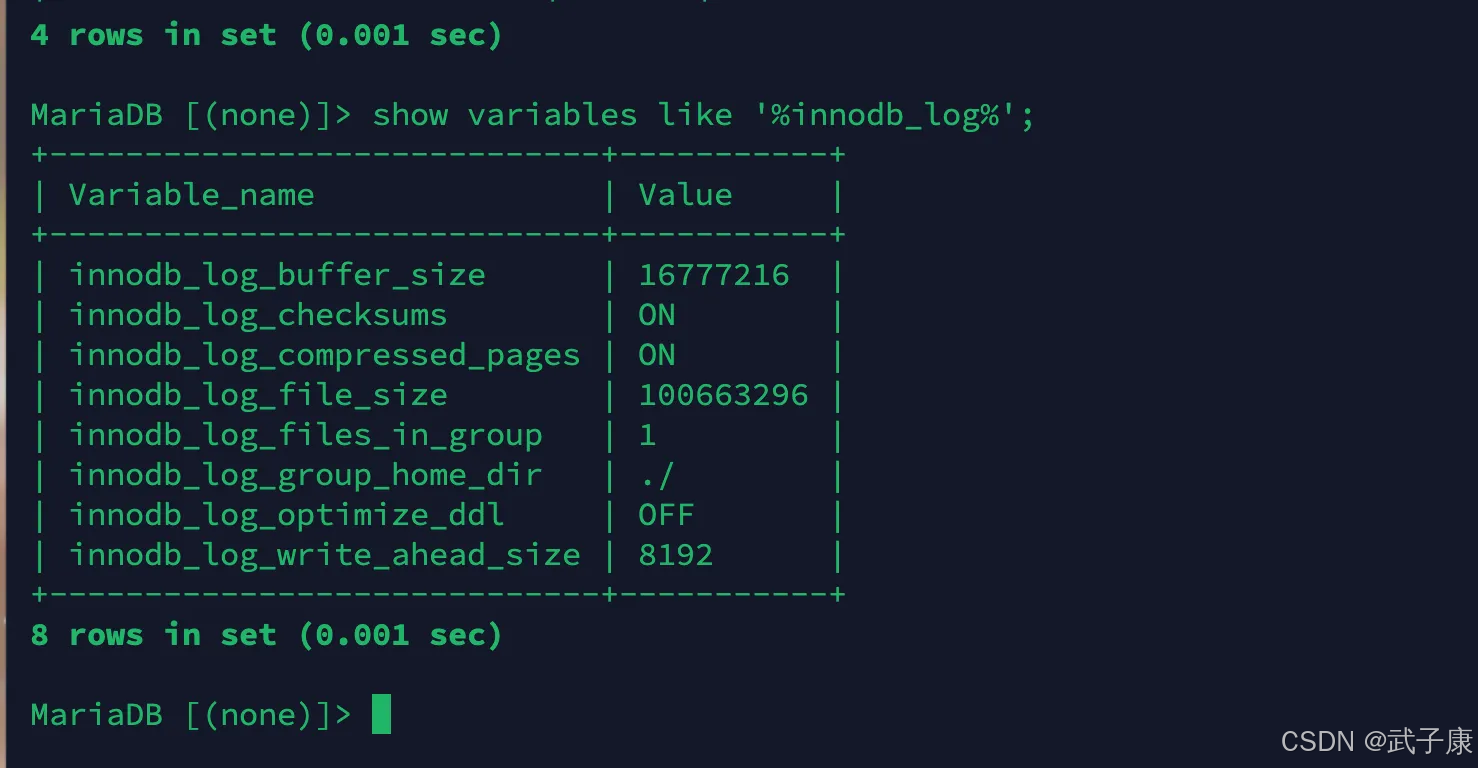
可以通过下面一组参数控制 Redo Log存储:
show variables like '%innodb_log%';
执行结果如下所示:
MySQL 的 Redo Buffer 持久化到 Redo Log 的策略是通过 innodb_flush_log_at_trx_commit 参数来控制的,这个参数对数据库的性能和数据安全性有着重要影响。以下是三种设置的具体说明和应用场景分析:
- 设置为0(异步持久化):
- 工作机制:将 Redo Buffer 内容每秒一次批量写入到操作系统的 Page Cache(OS Cache),然后由操作系统决定何时将数据刷新到磁盘(Flush Cache To Disk)
- 具体流程:由 InnoDB 的后台 Master 线程按照固定1秒的间隔执行 fsync 操作
- 风险点:如果 MySQL 进程崩溃或服务器宕机,最多会丢失最近1秒内的事务数据
- 典型场景:适用于对数据安全性要求不高,但需要极致性能的场景,如日志分析、监控数据采集等
- 设置为1(同步持久化,默认值):
- 工作机制:每个事务提交时都会执行完整的持久化流程,包括:Redo Buffer → OS Cache → 磁盘
- 具体实现:每次事务提交都会触发 fsync 系统调用,确保数据落盘
- 优势:提供了最高的数据安全性,保证即使服务器宕机也不会丢失已提交事务
- 性能影响:由于频繁的磁盘 I/O 操作,会导致显著的性能下降(TPS 可能下降50%以上)
- 适用场景:金融交易、支付系统等对数据一致性要求极高的业务
- 设置为2(折中方案):
- 工作机制:事务提交时将 Redo Buffer 写入 OS Cache,但不会立即触发磁盘刷新,由后台 Master 线程每隔1秒执行一次 fsync
- 风险分析:
- MySQL 进程崩溃:不会丢失数据,因为数据已在 OS Cache
- 服务器断电:最多丢失1秒内的事务数据
- 性能表现:相比设置为1,性能提升明显(TPS 可能提升30-50%)
- 推荐场景:对于大多数业务系统来说是最佳平衡点,在保证数据基本安全性的同时获得较好的性能
实际应用建议:
- 对于关键业务系统,建议在测试环境中对设置为1和2的性能差异进行基准测试
- 在云数据库环境中,由于底层存储通常有冗余和电池备份缓存,可以更安全地使用设置为2
- 如果使用 RAID 控制器带电池备份或 UPS 保护的服务器,设置为2的风险会进一步降低
- 在容器化部署时,需要特别注意设置为2时的数据丢失风险评估
补充说明:
- 这个参数的设置还会影响组提交(Group Commit)的效果
- 在高并发场景下,设置为1可能会导致事务提交排队等待 fsync
- 设置为2时,可以通过监控 “innodb_os_log_written” 状态变量来观察redo log的写入量



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











