









 本文介绍了使用卷积神经网络进行图像分类的方法,包括常见数据集(如CIFAR-10、MNIST等)、卷积神经网络的基本原理及其在ImageNet大赛上的发展历史。此外还讨论了激活函数和dropout等技术。
本文介绍了使用卷积神经网络进行图像分类的方法,包括常见数据集(如CIFAR-10、MNIST等)、卷积神经网络的基本原理及其在ImageNet大赛上的发展历史。此外还讨论了激活函数和dropout等技术。
目录
一,Image classification popeline
一,Image classification popeline
一般来说想要使用纯编程的方式来让机器识别一张图片中的东西是非常困难的,常用的方法就是使用一些算子来获取图像中的很多的特征,然后使用分类算法如SVM等进行分类,这样的话需要识别率不高。目前比较流行的方法是用数据驱动的方法来识别图片中的物体。比如使用卷积神经网络的方式来识别,通过向网络输入若干同类型的图片来让模型最终能识别出该类图片。
一般的步骤有:a,收集数据; b,用神经网络来训练;c,测试
二,数据集
常用的公共开放数据集有:
a,CIFAR-10:
10 classes, 50,000 training images, 10,000 test images, 32x32x3 images
https://www.cs.toronto.edu/~kriz/cifar.html
b,CIFAR-100:
100 classes, 50,000 training images, 10,000 test images, 32x32x3 images
https://www.cs.toronto.edu/~kriz/cifar.html
有20个大类,每个大类下面有5个小类。
c,MNIST:
10 classes, 60,000 training images, 10,000 test images, 28x28 images
http://yann.lecun.com/exdb/mnist/
d,SVHN:
10 classes, 73,257 training images, 26,032 test images, 32x32x3 images
http://ufldl.stanford.edu/housenumbers/
老吴实验室搞出来的数据集,主要是含有门牌号的照片。一张图片上可能有多个图片。
e,Caltech 101:
101 classes, ~5,050 images in total, 300x200x3 images
http://www.vision.caltech.edu/Image_Datasets/Caltech101/
f,Imagenet:
1000 classes, ~1.4M images in total, normalized to 256x256x3 images
http://www.image-net.org/
ImageNet比赛,很有名。
前五种数据集的规模不大,一般作为学术研究使用。只有最后一个数据集Imagenet是工业界常用的。
三,卷积神经网络
卷积的主要步骤的卷积(convolutional)和降采样(pooling)
卷积的目的其实是求图像中与自己相似的地方,在数学层面上卷积是对矩阵做内积。卷积------->内积------->相似度
a,一张彩色图像的3通道的,比如:128*128*3,在与一张同样是是3通道的卷积核发生卷积之后,就成为一个单通道的矩阵了;而当我们设置多个卷积核的时候就会得到多个矩阵,可以将这些矩阵组合在一起当做多通道的结果输出。那么有多少卷积核就有多少个通道。
b,在做完卷积核之后,通常要对得到的矩阵做非线性变换,也就是使用一个激活函数得到非线性的结果作为输出结果。
c,pooling层不是必须的,不一定要一层卷积之后跟一层降采样
四,ImageNet比赛上夺冠的CNN模型
12年AlexNet:

14年VGGNet

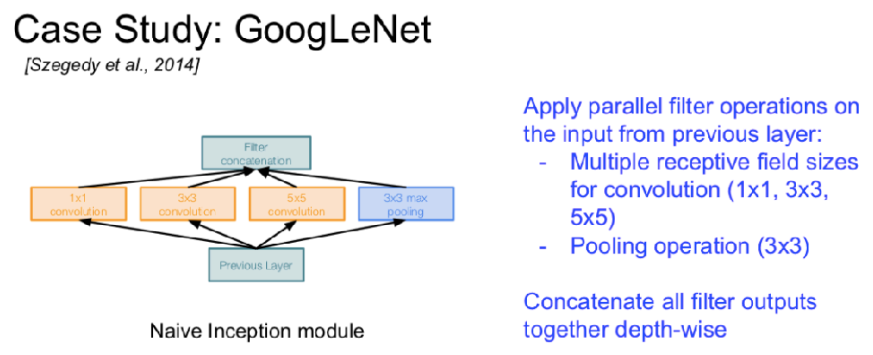
15GoogLeNet

与其他CNN的不同之处:
16ResNet:
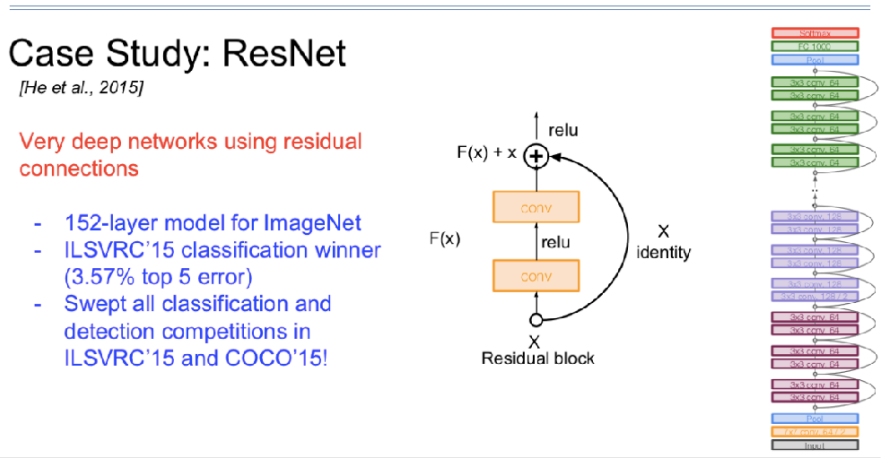
有一个很神奇的Resident block技术
五,一些补充
1,激活函数:
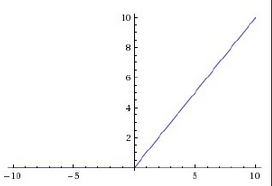
目前比较常用的激活函数是Relu,它的公式是:f(x)=max(x),它的图如下所示:
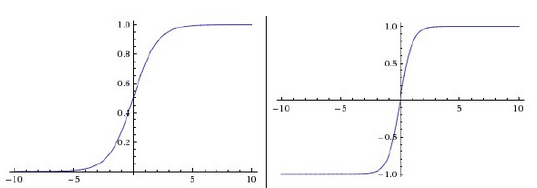
其他常用的激活函数有:sigmoid和tanh:


它们的显示图,如下所示:
2,用来防止网络过拟合的dropout
Dropout Learning是训练深度学习网络训练参数的一种方法,它可以避免过拟合并且可以有效结合指数个数(2n,n表示神经元的个数)的网络结构。Dropout就是在训练网络时随机的舍弃掉隐层和可视层的一些神经元,其输入及输出连接也相应的去掉。最简单的情况便是独立的以概率P来选择一个神经元,P=0.5会使训练达到最优。但对于输入层P=1时最优。网络各层都使用权值共享。每次训练时都会随机的选择一些神经元来组成一个“变瘦”的网络,下次训练时会重新选择神经元组成新的网络,但权重会使用上次训练好的值,一直这样继续下去,直到满足误差或达到一定的迭代次数。(有n个神经元,每个神经元都有可能被选择到,所以共有Cn0+ Cn1 +Cn2+…+ Cnn=2n个,可以结合下图理解)而在测试阶段不舍弃神经元,只是将训练网络的神经元权重乘以P,使其达到与训练时输出相同的效果。示意图如下:
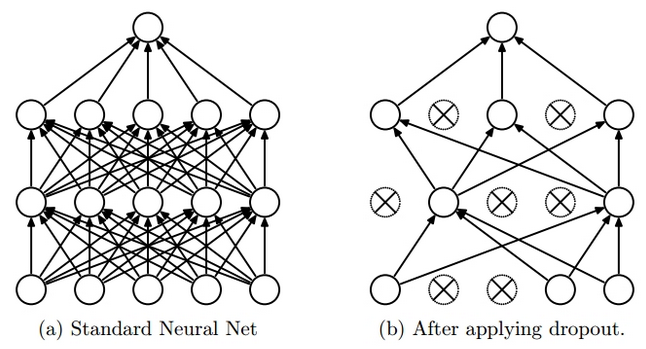
图1的左图表示网络的正常架构,右图表示使用Dropout Learning后的网络结构,有链接的神经元表示被选中的神经元,打差号的为未被选中的神经元。这样无论前向传播还是后向传播,都只使用被选择到的神经元。
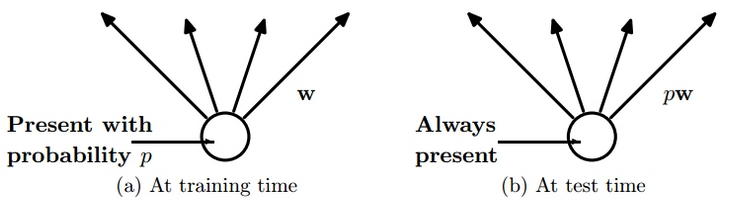
图2左图表示训练时,该神经元以概率P被选到,值在其上传播时使用的权值为W。右图表示测试时,这时不舍弃任何神经元,而是将所有神经元的的权重乘以其被选择的概率P,这样可以使在测试时神经元的输出与在训练时神经元的输出相同。
六,参考文章
Dropout Learning - 防止深度神经网络过拟合_小蜗牛的百米冲刺的博客-优快云博客_dropout learning
http://blog.youkuaiyun.com/u013146742/article/details/51986575


















 2761
2761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











