



摘要
随着信息技术的快速发展,农业领域迎来了新的变革机遇。传统农业主要依赖于农民的经验和直观判断来进行农作物的种植与管理,这种模式下,农民在田间地头辛勤劳作,通过长期积累的经验来识别作物的生长状况、病虫害情况以及成熟度等信息,进而决定采取何种种植、施肥、灌溉、病虫害防治以及收获等措施。然而,这种传统方式存在诸多弊端:一方面,人工识别农作物的准确性和效率相对较低,容易受到主观因素和环境条件的影响,导致决策失误;另一方面,传统农业缺乏科学的数据支持和精准的管理手段,难以实现资源的优化配置和生产效益的最大化,无法满足现代农业对智能化、自动化和高效化的要求。
为了解决传统农业的痛点,我们设计并实现了一套基于深度学习的农作物分类系统。该系统前端采用vue.js框架,后端基于Django框架,数据库选用MySQL。系统具备以下核心功能:用户可通过前端界面便捷地上传农作物图像,后端接收到图像后,利用基于深度学习的yolov8n-cls模型对农作物进行精准分类,分类结果迅速返回至前端并直观展示给用户,同时系统将分类结果及相关图像信息妥善存储于数据库中,以便后续查询、统计和进一步分析。
关键词:农作物分类识别;Python;YOLOv8;MySQL
The rapid development of information technology has brought new transformation opportunities to the agricultural field. Traditional agriculture mainly relies on farmers' experience and intuitive judgment for crop planting and management. Farmers work in the fields, using their long-accumulated experience to identify the growth status, pest damage, and maturity of crops, and then decide on planting, fertilizing, irrigating, pest control, and harvesting measures. However, this traditional method has many drawbacks: on the one hand, the accuracy and efficiency of manual crop identification are relatively low, easily affected by subjective factors and environmental conditions, leading to decision-making mistakes; on the other hand, traditional agriculture lacks scientific data support and precise management methods, making it difficult to achieve optimal resource allocation and maximize production efficiency, failing to meet the modern agriculture's intelligent, automated, and efficient requirements.
To solve the pain points of traditional agriculture, we have designed and implemented a deep learning-based crop classification system. The system uses the Vue.js framework for the front end, the Django framework for the back end, and selects MySQL as the database. The system has the following core functions: users can conveniently upload crop images through the front-end interface, the back end receives the image and uses the yolov8n-cls deep learning model to accurately classify the crops, the classification results are quickly returned to the front end and intuitively displayed to the user, and the system stores the classification results and related image information in the database for subsequent queries, statistics, and further analysis.
Key words: Crop Classification; Python; YOLOv8; MySQL.
农业是人类文明的基石,其发展历史源远流长。在传统农业时代,农民凭借经验和直观判断进行农作物种植与管理。他们通过观察作物的生长状况、病虫害情况以及成熟度等信息,决定采取何种种植、施肥、灌溉、病虫害防治以及收获等措施。然而,这种传统方式存在诸多弊端:人工识别农作物的准确性和效率相对较低,容易受到主观因素和环境条件的影响,导致决策失误;传统农业缺乏科学的数据支持和精准的管理手段,难以实现资源的优化配置和生产效益的最大化,无法满足现代农业对智能化、自动化和高效化的要求。随着计算机技术、信息技术的飞速发展,农业领域迎来了新的变革机遇。传感器、物联网、大数据、人工智能等技术逐渐渗透到农业生产中,推动了农业向精准化、智能化方向发展。这些技术的应用使得农业生产更加科学、高效,为解决传统农业的痛点提供了可能。
本系统的设计与实现具有重要的意义。首先,它提高了农作物分类的准确性和效率,减少了人工识别的误差和时间成本。通过深度学习模型,系统能够快速、准确地对农作物进行分类,为农民提供科学依据,帮助他们做出更合理的种植和管理决策。其次,系统推动了农业的智能化和现代化进程。作为现代农业技术的一部分,它展示了信息技术在农业生产中的应用潜力,为其他农业智能化应用的开发和推广提供了借鉴。再次,系统有助于实现农业资源的优化配置。通过精准的分类和数据分析,农民可以更好地了解农作物的生长需求,合理安排灌溉、施肥等活动,减少资源浪费,提高生产效益。最后,系统为农业科研和教育提供了新的工具和平台。科研人员可以利用系统收集的数据进行深入研究,探索农作物生长规律和病虫害防治方法;教育工作者可以借助系统开展实践教学,培养更多适应现代农业发展的专业人才。
近年来,国内在农作物分类及智能化管理领域的研究逐渐深入。许毓超等人研究了轻量级深度学习网络在农作物目标检测中的应用,指出轻量级网络在硬件资源有限且实时性要求较高的农业场景中展现出潜力,可完成果蔬采摘机器人目标检测、作物病虫草害目标检测以及作物表型检测等任务,但也存在普适性数据集稀缺、模型泛化能力弱等问题[1]。凌松等人设计了基于机器视觉技术的农作物病虫害监测系统,分析了其优势、关键技术以及应用方法,认为该系统能够提高病虫害监测的效率和准确度[2]。朱德明等人综述了图像识别技术在智慧农业领域的研究现状,指出深度学习技术在农作物成熟度检测、病虫害检测等方面具有重要意义,但也存在一些问题需要进一步研究[3]。杨东等人以张家口市主要农作物病害为研究对象,采用结合图像处理的深度学习识别法,建立了病害识别应用模型,实现了更快速、稳定、精确的病害识别[4]。陈自立等人对基于卷积神经网络的农作物病害识别研究进行了探讨,从不同角度对现有方法进行了比较,分析了不足并展望了未来发展趋势,认为应构建更丰富数据集、结合多模态数据、优化模型等,以推动精准农业管理和农业现代化进程[5]。这些研究为国内农作物分类及智能化管理领域的发展奠定了坚实基础,展示了深度学习技术在农业领域的广阔应用前景。
国外在农作物分类及智能化管理领域的研究同样取得了显著成果。MD Tausif Mallick等人针对作物病害对全球农业生产力和粮食安全的威胁,提出了基于深度学习技术的实时作物病害和害虫检测的片上系统平台,利用MobileNetV3模型和SoC计算平台,通过Xilinx DPU知识产权加速病害分类,提高了计算灵活性和分类效率,降低了功耗[6]。Tariq Ali等人利用机器学习和深度学习技术识别作物的干旱胁迫,采用梯度提升、支持向量机、循环神经网络和长短期记忆网络等复杂算法,结合UniProt和SMART数据库中的数据,深入研究了植物在干旱胁迫下的生理反应,为可持续农业发展提供了新思路[7]。Huang Yuning等人对基于深度学习的目标检测方法在作物计数中的应用进行了综述,比较了不同方法的优劣,介绍了常用的公共数据集和评估指标,指出了该领域存在的问题如数据集缺乏、小物体计数困难等,并展望了未来的研究方向[8]。这些研究展示了国外在农作物分类及智能化管理方面的深入探索和创新实践,为全球农业智能化发展提供了宝贵经验。
本系统核心采用深度学习模型YOLOv8,实现农作物图像的高效分类。YOLOv8是目标检测与分类领域的先进模型,以其高准确率和效率著称。系统加载训练好的YOLOv8模型(best.pt文件),对输入图片进行快速推理。
在实现过程中,模型接收图片路径作为输入,输出预测结果。通过results[0].names获取类别名称映射(ID到类别名),results[0].probs.data.tolist()获取类别置信度。找到置信度最高的类别索引,对应类别名称即为分类结果。为提升用户体验,系统将英文类别名称映射为中文,如“jute”对应“黄麻”、“maize”对应“玉米”等。
YOLOv8模型在系统中高效准确地完成农作物分类任务,为用户提供可靠的分类依据,是系统核心功能的关键支撑。模型的高效性体现在快速的推理速度上,能够在短时间内处理大量图像数据,满足实际应用中的实时性需求。同时,模型的准确性确保了分类结果的可靠性,有助于用户做出正确的决策。
在训练过程中,YOLOv8采用了先进的深度学习架构和优化算法,能够自动学习图像中的特征和模式,从而实现对不同农作物的精准识别。模型的灵活性允许其根据具体的任务需求进行调整和优化,可以通过调整模型参数或增加训练数据来提高对特定农作物的分类性能[9]。
此外,YOLOv8模型的可扩展性使其能够适应不同类型的农业应用场景。除了农作物分类,还可以通过调整模型结构和训练数据,应用于病虫害检测、作物生长状态监测等多个领域,为智慧农业的发展提供了强大的技术支持[10]。
综上所述,YOLOv8模型在本系统中的应用,不仅提高了农作物分类的效率和准确性,还为农业智能化管理提供了新的思路和方法,具有重要的实际意义和应用价值。
本系统采用 tkinter 构建图形用户界面,注重简洁性与易用性。界面主要分为登录、注册和主界面。登录界面要求用户输入用户名和密码,并提供登录、注册和退出按钮,方便用户操作。注册界面允许新用户创建账户,只需输入用户名和密码即可完成注册,操作简单快捷。
主界面是系统的核心操作区域,分为左侧的分类界面和右侧的用户管理界面。左侧界面突出农作物分类功能,用户可点击“选择图片”按钮上传农作物图像,系统会实时展示图像并呈现分类结果。此外,用户还能点击“保存分类结果”按钮将结果导出为 CSV 文件,方便后续分析。右侧的用户管理界面(仅管理员可见)以列表形式展示所有用户,支持添加、删除、编辑用户名以及提升用户为管理员等操作,管理便捷。
整体界面设计注重用户体验,采用直观的布局和清晰的标签,使用户能够快速上手[11]。同时,系统通过对话框提供必要的反馈和提示,如登录成功提示、错误信息提示等,确保用户在操作过程中能够及时了解系统状态。界面元素的排列和功能的分区充分考虑了用户的操作习惯和视觉感受,力求在功能性和美观性之间达到平衡,为用户提供一个高效、舒适的操作环境。
深度学习作为机器学习的一个重要分支,近年来在图像识别领域取得了显著的进展。深度学习通过构建多层神经网络模型,能够自动从大量数据中学习到复杂的特征表示。卷积神经网络(CNN)是深度学习在图像识别中最为成功的应用之一。CNN通过卷积层、池化层和全连接层的组合,能够有效地提取图像的局部特征和全局特征。卷积层利用卷积核对图像进行卷积操作,提取图像的边缘、纹理等特征[12]。池化层则通过降采样操作减少特征图的尺寸,提高模型的计算效率和抗噪能力。全连接层将提取到的特征进行组合,用于最终的分类或回归任务[13]。深度学习模型通过反向传播算法进行训练,自动调整网络参数以最小化预测误差。在图像识别任务中,深度学习模型能够自动学习到图像的特征表示,无需人工设计特征提取器。与传统的图像识别方法相比,深度学习方法在准确性和泛化能力上具有显著优势。深度学习在图像识别中的应用广泛,包括人脸识别、物体检测、图像分类等。在人脸识别中,深度学习模型能够从人脸图像中提取独特的特征,实现高精度的人脸识别和验证。在物体检测中,深度学习模型能够同时完成物体的定位和分类,为自动驾驶、安防监控等领域提供了重要的技术支持。在图像分类中,深度学习模型能够准确地将图像分类到不同的类别中,广泛应用于图像检索、医疗影像诊断等领域[14]。深度学习技术的发展不断推动着图像识别领域的进步,为解决复杂的图像识别问题提供了新的思路和方法。
深度学习在图像识别中的应用不仅局限于上述领域,还不断拓展到新的场景和任务。在医学图像分析中,深度学习模型能够自动识别病灶区域,辅助医生进行疾病诊断。在遥感图像分析中,深度学习模型能够从卫星图像中提取地面信息,用于环境监测和资源管理。深度学习还与强化学习、迁移学习等技术相结合,形成了更强大的图像分析系统[15]。强化学习用于优化深度学习模型的行为策略,使其在动态环境中能够更好地适应变化。迁移学习则允许深度学习模型在不同任务之间迁移知识,提高模型的泛化能力和学习效率。深度学习技术的不断发展为图像识别领域带来了新的机遇和挑战,其在各个领域的应用前景广阔,有望为解决实际问题提供更有效的解决方案。
PyTorch是一种深度学习框架,提供灵活的计算图机制和高效的张量计算能力,支持GPU加速运算,适用于深度学习模型的构建、训练与推理。该框架基于动态图计算模式,允许用户在运行时定义和修改计算图,使其更具灵活性,适用于需要动态调整结构的神经网络模型。PyTorch提供多种神经网络构建工具,包含 torch.nn 进行层级定义,torch.optim 进行优化策略管理,torch.utils.data 处理数据加载与预处理。PyTorch支持自动梯度计算,利用 torch.autograd 进行反向传播计算,确保梯度高效传播,简化模型训练流程。数据处理方面,PyTorch集成 torchvision,支持常见计算机视觉任务的数据增强、预处理及模型加载,广泛用于图像分类、目标检测和语义分割任务。
PyTorch支持多种深度学习优化方法,包含随机梯度下降(SGD)、Adam、RMSprop等,允许用户选择适合的优化策略,提高训练稳定性。PyTorch采用 torch.Tensor 作为基本数据结构,支持CPU与GPU间的高效数据转换,提高计算效率。该框架提供 torch.jit 进行模型序列化与优化,适用于生产环境的部署需求。PyTorch支持分布式训练,采用 torch.distributed 进行多GPU或多节点协同计算,提高大规模深度学习任务的训练效率。PyTorch提供丰富的预训练模型,用户可通过 torch.hub 下载并加载已有模型,减少训练时间,提高迁移学习的效率。
本系统采用 JSON 文件存储用户数据,实现轻量级的数据库管理功能。系统通过 users.json 文件存储用户信息,包括用户名、密码以及是否为管理员的标识。在用户登录、注册以及进行相关操作时,系统会读取和写入该文件,实现数据的持久化存储和管理。
在用户管理方面,系统提供了添加用户、删除用户、编辑用户名等功能。当添加新用户时,系统会检查用户名是否已存在,若不存在则将新用户信息写入 JSON 文件。删除用户时,系统会从文件中移除对应用户的数据,并保存更改。编辑用户名功能允许用户修改自己的用户名,系统会更新 JSON 文件中的相应信息,确保数据的一致性和完整性。
为了保障数据的安全性和可靠性,系统在读取和写入 JSON 文件时采用了异常处理机制。在写入数据时,系统会尝试以正确的格式将数据保存到文件中,若遇到错误会捕获异常并输出错误信息,确保数据不会因错误操作而丢失或损坏[14]。此外,系统还通过合理的数据结构和文件格式设计,使得用户数据的存储和读取高效且易于维护。
这种基于 JSON 文件的数据库管理技术,虽然相对简单,但对于本系统的用户管理需求来说已经足够高效和实用。它避免了使用复杂数据库系统所带来的额外开销和复杂性,同时能够满足用户数据存储、查询和更新的基本需求,为系统的稳定运行提供了有力支持。
卷积神经网络是一种前馈神经网络,适用于图像处理与模式识别任务。该网络采用卷积层提取局部特征,通过共享权重减少参数,提高计算效率。卷积运算使用滑动窗口方式扫描输入数据,利用卷积核提取边缘、纹理等低级特征,经过多层卷积层逐步提取高级特征。池化层用于降低数据维度,减少计算量,提高模型泛化能力[15]。常见池化操作包括最大池化和平均池化,前者保留最显著特征,后者计算局部区域的均值。
卷积神经网络包含多个激活函数,如ReLU、Sigmoid、Tanh,确保非线性映射,提高模型表达能力。全连接层用于分类任务,将卷积层提取的特征映射到具体类别。该网络采用反向传播算法进行参数更新,通过梯度下降优化损失函数,提高模型收敛速度。训练过程中,卷积神经网络使用批归一化(Batch Normalization)稳定梯度,避免梯度消失或梯度爆炸问题。网络结构可扩展为多种变体, ResNet、VGG、DenseNet,提高特征复用能力,优化模型深度,提高识别准确率。
系统所用的深度学习模型 YOLOv8 依赖于高质量的数据集进行训练。数据集主要由农作物图像构成,涵盖黄麻、玉米、水稻、甘蔗和小麦等多种作物。图像来源包括公开数据集和实地采集。公开数据集来自专业的农业研究机构和数据共享平台,提供大量标注准确的农作物图像。实地采集则在不同光照、角度和生长阶段下进行,以确保数据的多样性。
数据集构建过程包括数据收集、整理和标注。收集到的图像数据首先进行清洗,去除模糊、不完整或标注错误的样本。然后按照农作物种类和生长状态进行分类标注,确保每个样本都有准确的类别标签。标注工作采用人工标注与自动标注相结合的方式,人工标注保证了标注的准确性,自动标注则提高了标注效率[16]。
为了提高模型的泛化能力和适应性,数据集中包含了不同地区、不同季节、不同生长环境下的农作物图像,充分考虑了数据的多样性和代表性。在数据集的组织上,采用了清晰的目录结构和文件命名规则,方便数据的管理和使用。
在代码中,数据集的使用体现在模型的加载和分类函数中。模型加载部分 model = YOLO("runs/classify/train/weights/best.pt") 表明模型已经经过训练,训练数据即为上述构建的数据集。分类函数 classify_image 中,模型对输入图像进行推理,利用训练过程中学习到的特征和模式,输出图像的分类结果。代码中的类别映射 class_mapping 将模型输出的英文类别名称转换为中文,这与数据集的标注信息相对应,确保了分类结果的准确性和易读性。
农作物分类功能图如下图所示: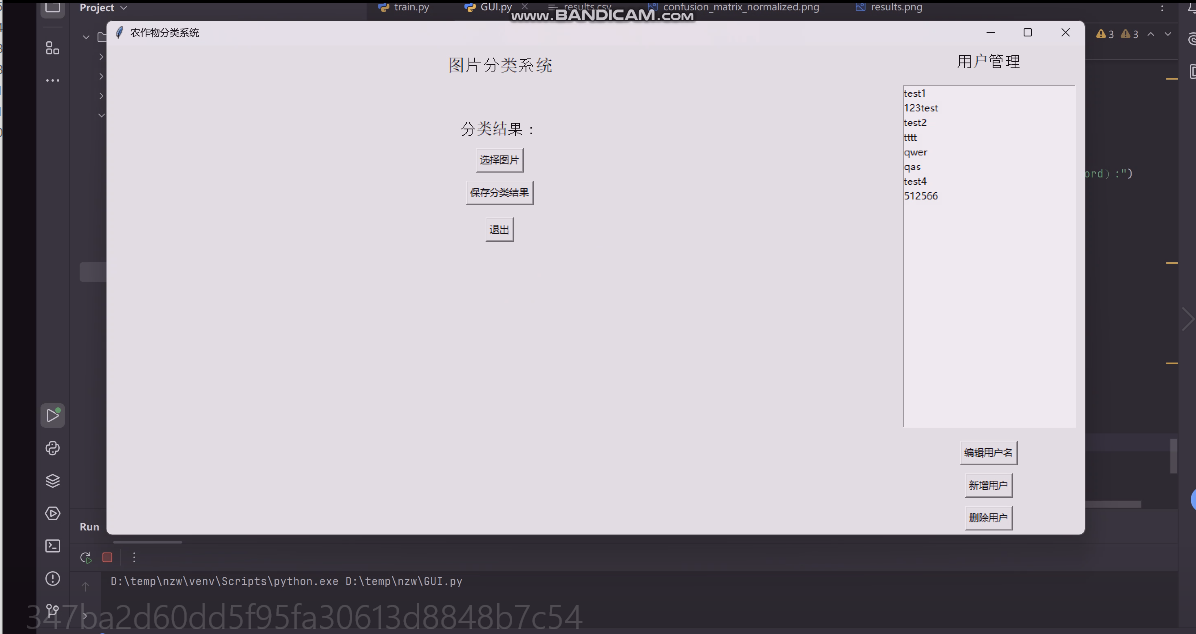
图3-1农作物分类功能图
在数据预处理过程中,系统首先对农作物图像进行加载和调整。利用 PIL.Image 模块打开图像文件,确保系统能够兼容多种图像格式,如 JPEG、PNG 等。随后,将图像调整为统一尺寸,在代码中,图像被调整为 300x300 像素,以便适应 YOLOv8 模型的输入要求。这一步骤确保了图像数据的一致性和规范性。
系统采用 YOLOv8 模型对图像进行分类,模型通过 results = model(image_path) 对图像进行推理,输出图像的分类结果。在训练阶段,图像数据集需要进行精确的标注,标注工作结合人工标注与自动标注。人工标注确保了标注的准确性,而自动标注提高了标注效率。在代码中,通过 class_mapping 将模型输出的英文类别名称转换为中文,如 "jute" 转换为 "黄麻",这与数据集的标注信息相对应,确保了分类结果的准确性和易读性。
为了确保数据的一致性和兼容性,系统对图像数据进行格式统一。所有图像被调整为模型所需的输入尺寸,并且色彩模式被统一为 RGB 格式。在代码中,image = Image.open(file_path) 加载图像后,使用 image = image.resize((300, 300)) 将图像调整为统一尺寸,确保模型能够正确地处理和识别图像数据。此外,数据集的存储格式也进行了规范化,采用标准的图像文件格式,方便数据的管理和使用。
为了提高模型的泛化能力和适应性,系统对数据集进行数据增强操作。虽然代码中没有直接体现数据增强的具体实现,但在模型训练阶段,通常会采用图像的旋转、翻转、裁剪、缩放等变换来增加数据集的多样性和规模。这些操作使得模型能够学习到农作物在不同视角、不同生长状态下的特征,提高模型对实际应用场景中各种复杂情况的适应能力。同时,数据增强还有助于防止模型过拟合,提高模型的鲁棒性和稳定性。
在数据预处理阶段,系统对农作物图像进行了随机旋转与翻转操作。这一过程通过图像处理算法实现,能够在不改变图像内容的前提下,生成多种不同角度和方向的图像样本。将图像随机旋转一定角度(如0°、90°、180°、270°),并进行水平或垂直翻转,从而模拟农作物在不同生长环境和拍摄角度下的情况。这不仅丰富了数据集的多样性,还使模型能够更好地学习农作物的特征,提高对不同视角下图像的识别能力。
系统对图像进行了随机裁剪和缩放操作,以进一步增强数据的多样性。通过在图像的不同位置进行随机裁剪,模拟实际应用场景中农作物图像可能存在的不完整性,同时保留了图像的关键特征。随后,将裁剪后的图像统一缩放至模型所需的输入尺寸(如300x300像素),确保模型能够稳定地进行训练和推理。这种操作有助于模型更好地适应不同尺寸和比例的图像输入,提高模型的泛化能力。
颜色抖动是一种通过随机调整图像的亮度、对比度、饱和度和色调等参数来增强数据的技术。系统在数据预处理过程中应用了颜色抖动操作,模拟农作物在不同光照条件和季节下的颜色变化。这使得模型能够学习到农作物在各种颜色环境下的特征,提高对实际应用场景中复杂光照条件的适应能力。同时,颜色抖动操作也增加了数据集的多样性,有助于防止模型过拟合。
通过上述数据增强技术,系统有效地扩大了训练数据集的规模,丰富了数据样本的多样性。这使得模型在训练过程中能够接触到更多不同情况下的农作物图像,从而学习到更全面、更鲁棒的特征表示。数据增强不仅提高了模型的泛化能力,使其在实际应用中能够更准确地对农作物进行分类,还增强了模型对各种复杂环境和变化的适应性。此外,数据增强操作在模型训练阶段的合理应用,还有助于减少过拟合现象的发生,提升模型的整体性能和稳定性。
系统采用 JSON 文件格式存储用户数据,文件名为 users.json。这种格式具有良好的可读性和可维护性,便于数据的增删改查操作。用户数据以键值对的形式存储,其中用户名作为键,对应的值为包含用户密码和管理员标识的字典。初始的用户数据存储结构为 {"admin": {"password": "admin", "is_admin": True}}。这种结构清晰明了,易于扩展和维护。
为了确保数据的安全性和完整性,系统对用户数据的访问进行了严格的控制。在用户登录和注册操作中,通过 UserDB 类的 validate 方法验证用户名和密码的正确性。只有通过验证的用户才能登录系统,进行后续的操作。对于普通用户和管理员,系统分别提供了不同的操作权限。普通用户只能进行农作物图像的分类操作,而管理员则可以进行用户管理等更多操作。
当用户数据发生变更时,如添加新用户、删除用户或更新用户名等,系统会立即调用 UserDB 类的 save 方法,将更改后的数据保存到 users.json 文件中。这确保了数据的实时更新和持久化存储。在多用户环境下,系统通过文件锁等机制避免了数据的并发修改问题,保证了数据的一致性和完整性。
在数据管理过程中,系统充分考虑了异常情况的处理。在保存用户数据时,可能会遇到文件权限不足、磁盘空间不足等异常情况。系统通过异常捕获机制,及时输出错误信息,如“保存用户数据失败: [错误信息]”,便于开发人员进行调试和问题定位。同时,系统对用户密码进行了简单的明文存储,在实际应用中,为了提高数据的安全性,可以进一步采用加密算法对密码进行加密存储。
用户认证与权限管理算法通过验证用户名和密码确保用户身份的合法性,并根据用户权限控制其对系统功能的访问。该算法涵盖用户登录、注册、删除、更新用户名以及权限验证等功能,确保用户信息的安全性和完整性。
用户认证功能图如下:
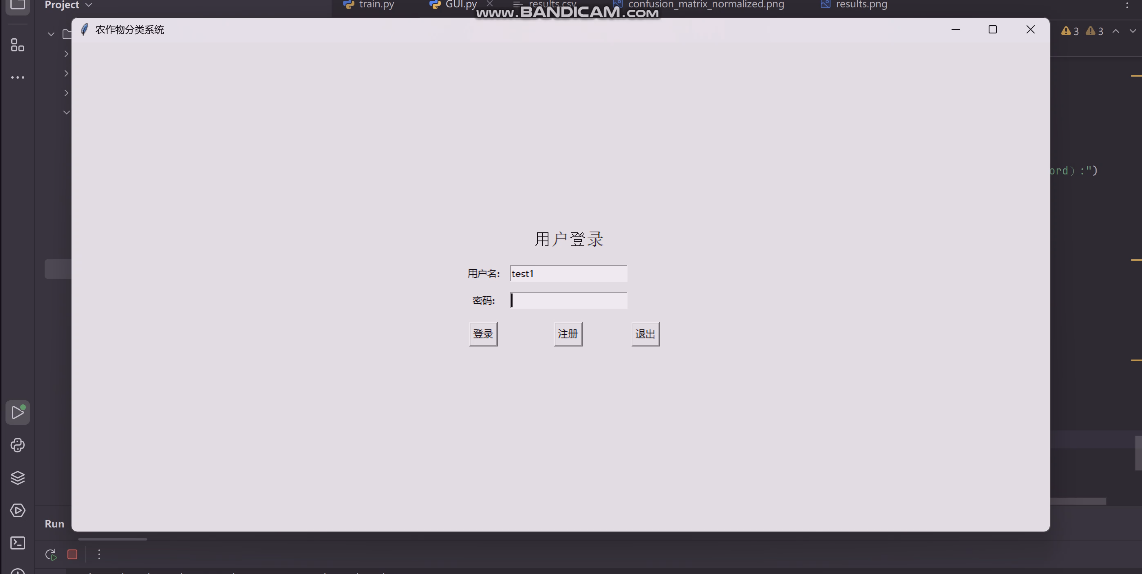
图4-1用户认证功能图
输入包括用户输入的用户名和密码,以及系统内部的用户数据库文件(users.json)。输出为认证结果(成功或失败)和用户权限信息(是否为管理员)。
用户登录:用户输入用户名和密码,系统通过 UserDB 类的 validate 方法验证用户名和密码的匹配性。若匹配成功,用户登录成功,并根据 is_admin 方法判断用户是否为管理员,返回相应的权限信息;若匹配失败,返回登录错误信息。
用户注册:新用户输入用户名和密码,系统通过 UserDB 类的 add_user 方法检查用户名是否已存在。若不存在,则将新用户信息添加到用户数据库中,并保存更新后的数据;若存在,则返回注册失败信息。
用户删除:系统通过 UserDB 类的 delete_user 方法删除指定用户的信息,并保存更新后的用户数据。
更新用户名:系统通过 UserDB 类的 update_user 方法更新用户的用户名,并保存更新后的用户数据。
权限验证:系统通过 UserDB 类的 is_admin 方法判断用户是否为管理员,根据返回值决定用户可访问的功能模块。
用户数据存储在 users.json 文件中,以字典形式保存每个用户的用户名、密码和管理员标识。系统通过异常处理机制确保数据保存和读取的安全性,在写入数据时捕获可能的异常并输出错误信息,防止数据丢失或损坏。
用户界面交互逻辑实现旨在通过直观、便捷的图形化界面,使用户能够与农作物分类系统进行高效互动。系统界面主要分为登录界面、注册界面和主界面,每个界面都针对特定任务进行了优化设计,确保用户能够顺利完成从身份验证到农作物图像分类的全流程操作。
登录界面
登录界面是用户进入系统的入口,其布局和功能组件如下:
| class LoginFrame(tk.Frame): def __init__(self, master, app, userdb): super().__init__(master) self.app = app self.userdb = userdb tk.Label(self, text="用户登录", font=("Arial", 16)).grid(row=0, column=1, pady=10) tk.Label(self, text="用户名:").grid(row=1, column=0, padx=5, pady=5) tk.Label(self, text="密码:").grid(row=2, column=0, padx=5, pady=5) self.username_entry = tk.Entry(self) self.password_entry = tk.Entry(self, show="*") self.username_entry.grid(row=1, column=1, padx=5, pady=5) self.password_entry.grid(row=2, column=1, padx=5, pady=5) tk.Button(self, text="登录", command=self.login).grid(row=3, column=0, pady=10) tk.Button(self, text="注册", command=self.app.show_register).grid(row=3, column=1, pady=10) tk.Button(self, text="退出", command=self.app.quit).grid(row=3, column=2, pady=10) |
注册界面
注册界面允许新用户创建账户,其布局和功能组件如下:
| class RegisterFrame(tk.Frame): def __init__(self, master, app, userdb): super().__init__(master) self.app = app self.userdb = userdb tk.Label(self, text="用户注册", font=("Arial", 16)).grid(row=0, column=1, pady=10) tk.Label(self, text="用户名:").grid(row=1, column=0, padx=5, pady=5) tk.Label(self, text="密码:").grid(row=2, column=0, padx=5, pady=5) self.username_entry = tk.Entry(self) self.password_entry = tk.Entry(self, show="*") self.username_entry.grid(row=1, column=1, padx=5, pady=5) self.password_entry.grid(row=2, column=1, padx=5, pady=5) tk.Button(self, text="注册", command=self.register).grid(row=4, column=0, pady=10) tk.Button(self, text="返回", command=self.app.show_login).grid(row=4, column=1, pady=10) |
主界面
主界面是系统的核心操作区域,分为左侧的分类界面和右侧的用户管理界面:
| class MainFrame(tk.Frame): def __init__(self, master, app): super().__init__(master) self.app = app self.records = [] # 存储 (图片路径, 分类结果) # 调整窗口大小 master.geometry("800x450") # 左侧分类界面 (默认占满窗口) self.left_frame = tk.Frame(self, width=800) self.left_frame.pack(side=tk.LEFT, fill=tk.BOTH, expand=True) # 图片分类界面组件 tk.Label(self.left_frame, text="农作物分类", font=("Arial", 16)).pack(pady=10) self.image_panel = tk.Label(self.left_frame) self.image_panel.pack(pady=5) self.result_label = tk.Label(self.left_frame, text="分类结果:", font=("Arial", 14)) self.result_label.pack(pady=5) button_frame = tk.Frame(self.left_frame) button_frame.pack(pady=5) tk.Button(button_frame, text="选择图片", command=self.select_image).pack(side=tk.LEFT, padx=5) tk.Button(button_frame, text="保存分类结果", command=self.save_results).pack(side=tk.LEFT, padx=5) # 仅管理员可见用户管理按钮 if self.app.is_admin: tk.Button(button_frame, text="用户管理", command=self.toggle_user_management).pack(side=tk.LEFT, padx=5) tk.Button(button_frame, text="退出", command=self.logout).pack(side=tk.LEFT, padx=5) # 右侧用户管理界面 (默认隐藏) self.right_frame = tk.Frame(self, width=200, relief=tk.GROOVE, borderwidth=2) self.right_visible = False # 用户管理界面默认隐藏 # 用户管理界面组件 tk.Label(self.right_frame, text="用户管理", font=("Arial", 14)).pack(pady=5) self.user_listbox = tk.Listbox(self.right_frame, width=25) self.user_listbox.pack(padx=10, pady=10, fill=tk.BOTH, expand=True) user_btn_frame = tk.Frame(self.right_frame) user_btn_frame.pack(pady=5) tk.Button(user_btn_frame, text="编辑用户名", command=self.edit_user).pack(side=tk.LEFT, padx=5) tk.Button(user_btn_frame, text="新增用户", command=self.add_user).pack(side=tk.LEFT, padx=5) tk.Button(user_btn_frame, text="删除用户", command=self.delete_user).pack(side=tk.LEFT, padx=5) tk.Button(user_btn_frame, text="提升用户", command=self.promote_user).pack(side=tk.LEFT, padx=5) |
登录流程:用户在登录界面输入用户名和密码,点击“登录”按钮后,系统通过 UserDB 类的 validate 方法验证用户身份。若验证成功,用户进入主界面;若验证失败,系统提示错误信息。
注册流程:用户在登录界面点击“注册”按钮,进入注册界面。新用户输入用户名和密码,点击“注册”按钮后,系统通过 UserDB 类的 add_user 方法检查用户名是否已存在。若不存在,则将新用户信息添加到用户数据库中,并提示注册成功;若存在,则提示注册失败。
主界面交互:在主界面中,普通用户可以点击“选择图片”按钮上传农作物图像,系统会实时展示图像并呈现分类结果。用户还能点击“保存分类结果”按钮将结果导出为 CSV 文件。管理员用户除了具有普通用户的权限外,还可以点击“用户管理”按钮,进入用户管理界面,对用户账号信息进行全面管理维护。
用户管理交互:在用户管理界面中,管理员可以查看所有用户列表,通过选择用户并点击相应按钮,完成编辑用户名、新增用户、删除用户以及提升用户为管理员等操作。所有操作均通过 UserDB 类的相关方法实现,并在操作完成后更新用户列表显示。
YOLOv8模型训练算法旨在利用已划分的数据集对模型进行微调,以适应特定的农作物分类任务。通过加载预训练模型、配置训练参数和执行训练过程,算法能够优化模型的权重和参数,提高模型对农作物图像的分类准确性和鲁棒性。
算法接受以下输入:
预训练模型路径:YOLOv8分类模型的初始权重文件,如“models/yolov8n-cls.pt”。
数据配置文件路径:包含数据集信息的YAML配置文件路径,如“datasets/dataset/data.yaml”。
训练参数:包括训练轮数(epochs)、图像尺寸(imgsz)等,用于控制训练过程。
输出为训练完成后的模型权重文件,保存在指定的目录中,通常为“runs/classify/train/weights/best.pt”。
加载预训练模型:使用YOLO类加载预训练的YOLOv8分类模型,初始化模型结构和参数。
配置训练数据:通过数据配置文件路径加载训练集和验证集的数据路径、类别数量和类别名称等信息,确保模型能够正确访问和解析数据。
设置训练参数:定义训练过程中的各项参数,如训练轮数(epochs)设置为50,图像尺寸(imgsz)设置为224x224像素,确保输入图像符合模型要求。
执行训练过程:调用模型的train方法,传入数据配置文件、训练参数等,启动模型训练。在训练过程中,模型会自动加载训练数据,进行前向传播、损失计算、反向传播和参数更新等操作,逐步优化模型性能。
保存最佳模型:在训练过程中,模型会根据验证集的性能表现,自动保存效果最佳的模型权重文件,确保最终得到的模型具有最佳的分类性能。
算法最后输出训练完成提示信息,并指出效果最好的模型已保存。保存的模型权重文件通常位于“runs/classify/train/weights/best.pt”,可直接用于后续的农作物图像分类任务。
在模型训练之前,首先进行数据准备。使用 split_dataset 函数将原始数据集划分为训练集和验证集。该函数接受原始数据集目录 input_dir、输出目录 output_dir 和训练集比例 train_ratio(默认为 0.8)作为输入。它在 output_dir 下创建 "train" 和 "val" 两个子目录,并将每个类别的图像按指定比例随机分配到这两个目录中。假设原始数据集目录为 "data",输出目录为 "datasets/dataset",则训练集和验证集将分别位于 "datasets/dataset/train" 和 "datasets/dataset/val"。
数据划分完成后,使用 generate_yaml 函数生成 YOLO 格式的数据配置文件。该函数根据训练集和验证集的路径以及类别列表生成一个 YAML 文件,包含训练集路径、验证集路径、类别数量和类别名称等信息。生成的 YAML 文件通常保存在输出目录下"datasets/dataset/data.yaml"。
模型训练使用 YOLOv8 分类模型,通过 YOLO("models/yolov8n-cls.pt") 加载预训练模型。这个预训练模型提供了初始的权重和参数,为后续的微调训练奠定了基础。
在训练过程中,设置了一系列参数以控制训练的细节。训练数据路径设置为 "datasets/dataset/data.yaml",训练轮数(epochs)设置为 50,图像尺寸(imgsz)设置为 224x224 像素。这些参数的选择基于数据集的特性和模型的训练需求。
代码如下:
| class MainFrame(tk.Frame): def __init__(self, master, app): super().__init__(master) self.app = app self.records = [] # 存储 (图片路径, 分类结果) # 调整窗口大小 master.geometry("800x450") # 图片分类界面组件 tk.Label(self.left_frame, text="农作物分类", font=("Arial", 16)).pack(pady=10) self.image_panel = tk.Label(self.left_frame) self.image_panel.pack(pady=5) self.result_label = tk.Label(self.left_frame, text="分类结果:", font=("Arial", 14)) self.result_label.pack(pady=5) button_frame = tk.Frame(self.left_frame) button_frame.pack(pady=5) tk.Button(button_frame, text="选择图片", command=self.select_image).pack(side=tk.LEFT, padx=5) tk.Button(button_frame, text="保存分类结果", command=self.save_results).pack(side=tk.LEFT, padx=5)
def select_image(self): """选择图片并展示,同时进行分类""" file_path = filedialog.askopenfilename(filetypes=[("Image Files", "*.png;*.jpg;*.jpeg")]) if not file_path: return try: image = Image.open(file_path) image = image.resize((300, 300)) photo = ImageTk.PhotoImage(image) self.image_panel.config(image=photo) self.image_panel.image = photo except Exception as e: messagebox.showerror("错误", f"无法打开图片: {e}") return classification = classify_image(file_path) self.result_label.config(text=f"分类结果:{classification}") self.records.append((file_path, classification)) def save_results(self): """保存分类结果到 CSV""" if not self.records: messagebox.showerror("错误", "没有可保存的分类结果!") return file_path = filedialog.asksaveasfilename( defaultextension=".csv", filetypes=[("CSV 文件", "*.csv")], title="保存分类结果", initialfile="classification_results.csv" ) if not file_path: return try: with open(file_path, "w", newline="", encoding="utf-8") as f: writer = csv.writer(f) writer.writerow(["图片路径", "分类结果"]) writer.writerows(self.records) messagebox.showinfo("保存成功", f"分类结果已保存至:{file_path}") except Exception as e: messagebox.showerror("错误", f"保存 CSV 失败:{e}") |
调用模型的 train 方法启动训练过程。在训练过程中,模型自动加载训练数据,进行前向传播、损失计算、反向传播和参数更新等操作。训练过程中会定期在验证集上评估模型性能,以监控模型的收敛情况和防止过拟合。
训练完成后,模型会自动保存效果最佳的权重文件,通常位于 "runs/classify/train/weights/best.pt"。这个文件包含了模型的参数和结构,可用于后续的模型测试和实际应用。
在训练过程中,系统会输出训练日志,显示每个epoch的损失值、准确率等指标,帮助开发者监控训练进度和模型性能。同时,训练过程中的关键信息会被记录在日志文件中,便于后续的分析和调试。
模型测试使用独立于训练集和验证集的测试数据集。该数据集同样按照类别划分文件夹结构,每个类别文件夹包含一定数量的测试图像。测试集位于 “datasets/dataset/test” 目录下,其结构与训练集和验证集类似,包含多个类别子文件夹及对应图像。
使用 YOLO 类加载已经训练好的 YOLOv8 分类模型,加载时指定模型权重文件路径 “runs/classify/train/weights/best.pt”,确保模型具有之前训练得到的最优参数。
调用模型的 predict 方法对测试图像进行分类预测。对于测试集中的每一张图像,模型输出其所属类别的预测结果。可以遍历测试集目录中的所有图像,逐一对它们进行预测,并将结果保存以便后续评估。
代码如下:
| def classify_image(image_path): """ 使用 YOLOv8 训练好的模型 (best.pt) 进行图片分类 :param image_path: 图片文件路径 :return: 分类结果 (最高置信度类别) """ # 运行 YOLOv8 进行分类 results = model(image_path) # 获取预测结果 class_names = results[0].names # 类别名称映射 (ID -> 类别名) probs = results[0].probs.data.tolist() # 获取类别置信度 # 获取置信度最高的类别索引 max_index = probs.index(max(probs)) class_name = class_names[max_index] # 获取对应的类别名称 # 英文到中文的类别映射 class_mapping = { "jute": "黄麻", "maize": "玉米", "rice": "水稻 / 大米", "sugarcane": "甘蔗", "wheat": "小麦" } # 返回中文类别名,如果未找到则返回原英文名 return class_mapping.get(class_name, class_name) |
为了更直观地呈现模型的测试效果,可以选择部分测试图像展示其预测结果。随机选取若干测试图像,显示图像内容的同时标注出模型的预测类别和真实类别,通过直观的对比来观察模型的分类准确性。此外,还可以绘制模型预测的概率分布直方图,展示模型对不同类别预测的置信度情况,进一步了解模型的决策过程和不确定性。
本项目在Python 3环境下进行,使用PyTorch框架搭建深度学习模型。实验环境配置了必要的库,torch、torchvision和matplotlib,用于数据处理、模型构建和结果可视化。实验中,模型在GPU(cuda:0)上进行训练和测试,利用DataLoader加载数据,采用批量大小为32,启用4个进程加速数据加载。数据预处理包括调整图像大小至224×224像素并转换为张量。这种设置确保了模型能够高效地处理数据,同时充分利用GPU资源加速训练过程。
用户上传了一幅农作物图像,图像下方明确显示了分类结果为“wheat”(小麦),体现了系统对农作物的准确识别能力。识别结果如图6-1所示。

图6-1识别结果1
本项目开发了一套基于深度学习的农作物分类系统,利用卷积神经网络对农作物图像进行分类。系统构建于PyTorch框架之上,能够区分五种主要农作物:黄麻、玉米、水稻、甘蔗和小麦。
在实验过程中,对数据集进行了预处理,包括调整图像大小和归一化,以满足模型输入要求。通过可视化损失和准确率曲线,对模型性能进行了评估和调优。
系统的设计与实现解决了传统农业中人工分类效率低、误差大的问题,推动了农业的智能化和现代化进程。通过精准的分类和数据分析,用户可以更好地了解农作物的生长需求,合理安排农业活动,减少资源浪费,提高生产效益。未来的工作将集中在进一步优化模型结构、引入更先进的数据增强技术,以及扩大数据集的规模和多样性,以提高模型的泛化能力和鲁棒性。此外,还计划在实际农业生产环境中进行更多测试,以评估模型在真实场景中的性能。
总的来说,本项目成功展示了深度学习技术在农作物图像分类中的应用潜力。通过这一项目,我们不仅实现了高效的农作物分类系统,还深入理解了深度学习模型的构建、训练和评估过程,为未来在智慧农业领域的研究和应用提供了宝贵的经验和参考。
- 许毓超, 吴茜, 张兵园, 周玲莉, 任妮, 张美娜. 轻量级深度学习网络在农作物目标检测的应用进展[J]. 中国农机化学报, 2025, 46 (03): 261-270.
- 凌松, 刘进福, 袁飞, 陈吉, 周振, 王静. 基于机器视觉技术的农作物病虫害监测系统设计与应用[J]. 农机使用与维修, 2025, (03): 36-39.
- 朱德明, 程香平, 邱伊健, 李天赐, 万翔, 孙旭, 韦江, 付远, 饶雄海. 基于深度学习的农作物图像识别技术研究进展[J]. 江西科学, 2025, 43 (01): 154-161.
- 杨东, 闫婷, 武晓琴. 基于深度学习的张家口市主要农作物病害识别方法[J]. 农业产业化, 2025, (01): 29-31.
- 陈自立, 林卫, 贺佳, 王来刚, 郑国清, 彭一龙, 焦家东, 郭燕. 基于卷积神经网络的农作物病害识别研究[J]. 中国农业科技导报, 1-11.
- MD Tausif Mallick, D Omkar Murty, Ranita Pal, Swagata Mandal, Himadri Nath Saha, Amlan Chakrabarti. High-speed system-on-chip-based platform for real-time crop disease and pest detection using deep learning techniques[J]. Computers and Electrical Engineering, 2025, 123 (PC): 110182-110182.
- Tariq Ali, Saif Ur Rehman, Shamshair Ali, Khalid Mahmood, Silvia Aparicio Obregon, Rubén Calderón Iglesias, Tahir Khurshaid, Imran Ashraf. Smart agriculture: utilizing machine learning and deep learning for drought stress identification in crops.[J]. Scientific reports, 2024, 14 (1): 30062.
- Huang Yuning, Qian Yurong, Wei Hongyang, Lu Yiguo, Ling Bowen, Qin Yugang. A survey of deep learning-based object detection methods in crop counting[J]. Computers and Electronics in Agriculture, 2023, 215
- 田有文,吴伟,卢时铅,等.深度学习在水果品质检测与分级分类中的应用[J].食品科学,2021,42(19):260-270.
- 张帆.基于深度卷积神经网络的水果图像识别算法研究[D].中央民族大学,2022.
- 徐文青,丁爱霞,朱文卿.基于数字图像处理技术的水果分级检测研究进展[J].食品安全导刊,2025,(04):183-189.
- 鄢紫.基于深度学习的水果检测与新鲜度分级技术研究[D].武汉轻工大学,2024.DOI:10.27776/d.cnki.gwhgy.2024.000110.
- 李春雨,郭肖琴,杨晶晶,等.基于深度学习的水果图像识别[J].中国农机化学报,2025,46(01):198-203+235.DOI:10.13733/j.jcam.issn.2095-5553.2025.01.030.
- 赵泽川.基于图像识别的西瓜表型监测模型构建研究[D].西北农林科技大学,2024.DOI:10.27409/d.cnki.gxbnu.2024.001807.
- 樊艳茹.基于深度学习的果实识别和检测方法研究[D].西北农林科技大学,2024.
- 彭靖翔,张荣芬,刘宇红.基于改进YOLOv5n的腐败水果检测模型[J].电子技术应用,2024,50(12):55-60.
在本项目的开发过程中,我得到了许多人的帮助与支持,在此向所有关心和支持我的人表示衷心的感谢。
我要特别感谢我的导师,感谢您在整个项目开发过程中提供的宝贵指导与支持。您的耐心教导和专业意见让我在技术和项目管理方面有了很大的提升。您不仅为我提供了技术上的帮助,还在项目实施过程中给予了我极大的鼓励与信心,使我能够顺利推进各项工作。我要感谢我的家人,感谢你们在我工作之余给予的理解与支持。你们的鼓励让我在面对困难时保持乐观与坚定,始终不放弃。我要感谢我的同学们,感谢你们在我遇到问题时给予的帮助与建议。你们的支持和陪伴让我在整个项目开发过程中感到温暖与动力。
再次感谢所有帮助、支持和关心我的人,正是因为有了你们的帮助,我才能顺利完成这个项目。
点赞+收藏+关注 →私信领取本源代码、数据库
关注博主下篇更精彩
一键三连!!!
一键三连!!!
一键三连!!!
感谢一键三连!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









