



云计算中的高效资源管理:基于低成本树莓派 测试平台的从仿真到实验验证
摘要
在云计算背景下,高效资源管理至关重要,因为它能够提高可扩展性,并随 时间推移实现显著的节能和成本降低。然而,由于云环境具有高度复杂性和 高成本,新开发的资源分配策略通常仅通过仿真手段进行验证,例如使用 CloudSim或定制开发的仿真工具。
本文描述了一种用于验证云资源分配策略的通用方法,阐明了在物理测 试平台上进行实验验证的重要性。此外,还介绍了树莓派作为服务( RPiaaS)的设计与实现,RPiaaS是一种使用树莓派节点构建的低成本嵌入 式测试平台。RPiaaS旨在促进从仿真向更大规模云测试平台上的实验评估 过渡,并采用微服务架构设计,实验及所有必要的管理服务均在容器内运行。
使用多个基准实验对RPiaaS测试平台的性能进行了评估。所得结果不 仅表明使用容器和运行所需RPiaaS服务的开销极小,而且为在树莓派测试 平台与更大规模的传统云测试平台之间扩展实验提供了有用的见解。
然后通过一个案例研究来说明所提出的验证方法,该案例研究重点关注 分层结构的租户数据的分配。将通过仿真获得的结果与实验结果进行了比较。
RPiaaS测试平台被证明是在将实验迁移至大规模测试平台之前进行初步实 验验证的非常有用的工具。
关键词
云计算,实验验证,树莓派测试平台,资源分配,仿真
1 引言
随着越来越多的服务在云中托管,数据中心的碳足迹进一步增加,这凸显了对可用资源进行高效管理的需求。通过 将云应用整合到少量物理服务器上,其余服务器可以进入待机状态,这不仅降低了能耗,还减少了运营成本。此外,高效资源管理可以实现更高的可扩 展性,因为可用资源得到了更优化的利用。
近年来,关于云资源的高效分配开展了大量研究,1‐3从而提出了多种新型资源分配策略。然而,这些新策略的 评估通常仅通过仿真进行,4例如使用CloudSim5或近期开发的DISSECT‐CF模拟器6。尽管仿真器是开发和评估 云资源管理新协议与算法的重要工具,但它们也存在局限性。例如,CloudSim最近受到一些批评4,指出其对I/ O处理的建模过于简化、通信模型有限、通信模型不准确,以及缺乏对服务质量的支持。此外,在使用CloudSi m时,通常需要自定义扩展,例如用于验证基于SDN策略的CloudSimSDN8,或用于建模和仿真容器的 ContainerCloudSim9。仿真实验也缺乏标准化,其适用性在很大程度上依赖于设计一个符合实际使用情况的良好 数据集,这使得基于仿真的验证变得具有挑战性。根据巴克等人10的观点,仿真可有效作为原型机制,提供特定算 法可能性能的大致概念,但很难验证仿真环境是否准确地反映了真实数据中心环境。此外,真实数据中心不断演变, 并受到计划内和计划外变更的影响。如果一个仿真模型在某一特定时间点得到验证,当之后重新运行该仿真时,这 一验证结果可能已不再成立。
因此,虽然云仿真器可用于对大批量实验进行初步评估,但在某个阶段也应考虑使用真实硬件进行实验评估, 因为这些实验通常会产生新的见解。所评估的实验设置可能会引入额外的硬件约束,而这些约束在新算法或仿真工 具设计时并未被考虑,或者这些实验可用于更准确地调整仿真参数。第6节中描述的用例说明了这一点:执行的实 验评估不仅能够测量执行时间等不同有用指标,还导致了对所评估分配策略的重要修改。当出现新技术时,仿真工 具和测试环境都需要进行更改以支持该技术。然而,两者之间存在一个重要区别。典型的测试环境由一组运行常见 Linux发行版的虚拟机或容器组成,因此所需软件组件很可能已在该环境中提供,并有良好文档记录且经过测试。
但是,在使用仿真时,可能仍需开发所需的扩展功能,而这需要对仿真工具的底层机制有深入的理解。
不幸的是,在公有云上运行实验既昂贵又耗时。对于新资源分配策略的设计和微调而言尤其如此,因为这通常 需要使用多个云实例进行多次增量迭代实验。特别是当实验在执行过程中失败时——例如,由于硬件约束或有缺陷 的算法——成本可能迅速增加。公有云计算还存在一些重要限制,因为客户很少能完全控制底层硬件资源。而对硬 件的这种控制级别往往是针对物理硬件层面的资源分配策略所要求的条件之一。11,12用户通常对已配置的虚拟节点的 物理分配控制有限,且公有云自身的资源分配策略和供应机制已深度“固化”。一次有缺陷的资源分配实验甚至可 能导致环境崩溃,因此公有云提供商几乎不可能允许这种级别的访问。因此,专注于资源分配的实验应在实验环境 中执行,而不是在稳定的公共云环境中进行。
对于私有云或社区云而言,大规模学术测试环境(如第2.1节中描述的测试平台)被开发用于支持在多种研究领 域中进行实验,并且相比仿真具有更高的真实性。尽管这些环境支持大规模系统验证,并为实验提供有价值的工具 集,但由于全球研究人员广泛使用,其基础设施资源可用性有限,且软硬件维护成本较高。通常,这些测试平台用 于大规模成熟验证测试,而不适合需要频繁更新的小型重复性测试。此外,这些环境通常采用机架安装方式,因此 不便于异地演示。
本文提出了一种用于验证新型云资源分配策略的通用方法,并设计了一个基于Raspberry Pi节点构建的低成本、 高能效的嵌入式云测试平台。该测试平台为资源分配策略的初步实验验证提供了一个廉价且易用的环境,可在将实 验迁移至大规模云测试平台之前使用。所开发的软件采用微服务架构设计,并提供REST接口以监控所有相关指标, 同时支持基于网页的
用于自动化配置和部署的接口。该测试平台旨在促进向实验评估的迈进,而无需深入研究现有测试平台的复杂细节。
本文的其余部分结构如下。下一节概述了该领域的相关工作。第3节描述了一种用于实验验证新型云资源分配 策略的通用方法,并强调了实验验证的重要性。第4节介绍了嵌入式树莓派测试平台,其性能和成本在第5节中进行 评估。在第6节中,我们通过使用树莓派测试平台验证一种专注于分层结构租户数据分配的自定义资源分配策略, 来说明我们的方法。最后,我们在第7节中总结全文并展望未来的研究方向。
2 相关工作
本节包含两个小节。首先,我们简要概述了可用于资源分配策略实验验证的现有云测试平台。该概述包括可用于配 置新云测试平台的平台,以及可供研究人员构建自有云的现有大规模基础设施。接下来,我们考察了其他使用树莓 派节点构建的微型云测试平台,并说明了它们与第4节中描述的测试平台的主要差异。
2.1 云测试平台
大规模测试平台的摘要见表1。台湾UniCloud测试平台13是一个由社区驱动的混合云平台,服务于台湾的学术界。
UniCloud的主要目标是利用不同组织间多个云中的资源,以应对需求的突发变化。一个自管理的云可以加入该平 台共享其资源,同时从其他具备扩展能力的云中获益。该平台提供了一个Web门户,通过统一接口操作各个云,并 采用云平台的RESTful API实现联邦计算与存储。此外,平台还基于获取的资源监控信息支持基于SLA的资源供给。
尽管UniCloud的架构与RPiaaS相似,但一个重要区别在于,RPiaaS并未采用现有的API,而是使用一种轻量级代 理,作为微服务安装在每个节点上以获取当前资源信息。UniCloud平台还解决了跨云问题,例如广域网上的 VLAN创建和跨云实时迁移,这在扩展我们的系统以支持地理上分布的集群间的联邦时可能非常有用。UniCloud 的一个缺点是用户仍需自行构建自己的云环境以集成到平台中,这一过程既昂贵又耗时。通过将RPiaaS的API集成 到UniCloud平台中,便有可能将RPiaaS集群添加到UniCloud混合云平台中。
CloudLab11是一个大规模分布式基础设施,拥有近15000个核心,分布在美国境内的三个站点。它允许研究人 员对云架构及其支持的新应用进行实验。CloudLab 提供对硬件的深度控制,例如对虚拟化、存储或网络层的控制 和可见性。然而,CloudLab 本身并不是一个云,而是让研究人员能够在高度真实的环境中构建他们自己的云。
Chameleon 云12与 CloudLab 类似,是一个大规模云测试平台,包含分布在500多个云节点上的18000个处理器核 心以及5拍字节的存储。研究人员可以使用 Chameleon 测试平台,通过预定义或自定义的软件栈创建定制化的云。
它提供裸机访问,以设计、开发并实验当前云中尚未部署的创新虚拟化技术。此外,它还提供一套丰富的监控工具, 使研究人员能够进行性能分析和
| 测试平台 | Type | 预期用途 |
|---|---|---|
| UniCloud13 | 混合云平台 | 利用不同组织间多个云中的资源 应对需求的突然变化。 |
| CloudLab11 | 分布式云基础设施 | 构建自己的云以实验云架构,并对硬件拥有深度 控制级别。 |
| Chameleon 云12 | 云基础设施 | 使用预定义或自定义的软件栈创建自定义云。 |
| 虚拟墙14 | 大规模通用测试环境 | 高级网络、分布式软件和服务仿真 和评估。 |
| Hyperdrive15 | 高度可重构的云计算实验平台 | 评估攻击和缓解措施对云系统实际影响 |
以高度细化的方式查看其自定义环境,并为所有进程提供详细的跟踪记录。另一个例子是 iLab.t 虚拟墙,14一个用 于高级网络、分布式软件和服务仿真与评估的大规模通用测试环境。虚拟墙由超过 4000 核心分布在 400 多台物理 服务器上组成,这些服务器在软件安装和网络拓扑方面均可完全配置。CloudLab、Chameleon 云和 iLab.t 虚拟 墙允许研究人员创建自己的云,可用于资源管理策略的大规模实验验证。然而,正如我们将在第3节中讨论的那样, 这些测试平台更适合进行较大规模的成熟验证测试,而不适合失败风险较高的初步实验。
Hyperdrive15是一个高度可重构的云测试平台,通过提供辅助的基础设施设置和配置,用于实验性评估攻击和 缓解措施对真实云系统的实际影响。为实现这一目标,它使用一个管理服务器,负责在平台上部署虚拟机监控器 (hypervisor)和自定义镜像。该管理服务器包含DHCP服务器、TFTP 服务器、HTTP 服务器、MQTT 服务器、 云镜像以及包含部署shell脚本的最小化实时Linux操作系统。客户端机器通过预启动执行环境进行网络启动,并获 取Debian 实时操作系统。Hyperdrive的架构与RPiaaS非常相似,因为RPiaaS测试平台也由一个负责部署的管理 节点和多个通过网络启动的工作节点组成,以提供一个高度可配置的测试平台。与Hyperdrive的主要区别在于, RPiaaS提供的是一个通用云测试平台,专为验证资源分配策略而设计,而Hyperdrive测试平台则针对聚焦于云安 全攻击与防御的实验进行了定制。
2.2 RaspberryPi测试平台
为了促进向实验验证的迈进,构建了一个低成本树莓派测试平台,可用于新型云资源分配策略的初步小规模实验验 证。目前已有其他一些项目使用树莓派节点来搭建小规模云测试平台,如表2所示。例如,亚伯拉罕森等人16构建了 一个由300个节点组成的树莓派云集群。该云采用树莓派1型B版节点搭建,这是最早商用的树莓派型号之一,搭载 ARM 700 MHz CPU,单芯片上最大配备512 MB内存。在该测试平台中,基于Debian的定制操作系统被复制到所 有独立的SD卡上,每个节点在启动时向主树莓派节点请求配置文件,并最终注册到集群。主节点负责处理所有节点 的注册与注销请求,并监控当前已注册的所有节点。该测试平台被用于实现一个分布式存储系统,其中所有节点通 过NFS挂载连接到主节点的中心化NAS上的共享卷。然而,逐个更新内存卡是一个繁琐且耗时的过程,尤其考虑到 测试平台中节点数量相对较多。
Pahl等人17通过描述由树莓派节点组成的边缘PaaS云架构,扩展了亚伯拉罕森等人16的初步研究。结合物联网 设备,计算可被推向云的边缘(即树莓派测试平台),而不是将所有数据发送到中心化云。作者同样使用了树莓派 1型B版节点,在所提出的架构中,每个节点都运行Docker服务以托管容器。采用Debian 7镜像来支持存储与集群 管理等核心中间件服务。对于集群管理,开发了一个自定义专用工具,用于节点的底层配置、监控和维护。主节点 负责节点的(注销)注册。在存储管理方面,作者研究了OpenStack Swift,但由于其资源消耗较高,最终也采用 了类似于亚伯拉罕森等人16设置的中心化NAS。
格拉斯哥树莓派云18旨在为云计算基础设施构建一个缩放模型。该云由56个运行Raspbian操作系统的树莓派 1节点组成,操作系统安装在SD卡上,每个节点托管三个Linux容器,以模拟云栈的每一层。
| 测试平台 | 节点型号 | 摘要 |
|---|---|---|
| 亚伯拉罕森等人16 | 树莓派1 | 云集群中,主节点提供配置和注册功能。 |
| Pahl 等人17 | 树莓派1 | 用于物联网设备的、运行Docker的边缘PaaS云。 |
| 格拉斯哥 RPi 云18 | 树莓派1 | 用于云计算的缩放模型,使用LXC容器。 |
| 格拉斯哥 RPi 云19 | 树莓派2和3 | 更新版本,用于评估云模拟器。 |
| Kecskemeti 等人20 | 树莓派2 | 用于评估DISSECT‐CF模拟器的小规模集群。 |
与第4节中描述的树莓派测试平台的主要区别在于:(1)我们专注于构建一个通用的IaaS云测试平台,用于验 证资源分配策略;(2)所有节点通过网络共享挂载根文件系统,而不是将操作系统安装在内存卡上;(3)主节点 使用一个包含集群中所有节点列表的最小化配置文件,而非对节点进行(注销)注册。通过使用网络共享作为根文 件系统,在升级内核或操作系统时更新集群变得更加容易,因为无需单独更新每张内存卡。此外,我们还在不同节 点上使用Docker来托管实验和所需的代理服务。我们的测试平台基于树莓派3B型构建,该型号配备更强大的1.2 GHz 64位四核ARMv8 CPU和1GB内存,因此更适合托管多个Docker容器。
最近,格拉斯哥树莓派云的开发人员通过将树莓派节点替换为较新的树莓派2和3型号,对其云测试平台进行了 升级,并使用更新后的测试平台将其性能与相应的CloudSim模型进行比较。19他们的主要结论是,CloudSim需要 更丰富的输入特征集,并且需要更复杂的模型来模拟分布式应用的节点间通信。因此,根据作者的观点, CloudSim目前在这些实验中的准确性不足,这凸显了实验验证的重要性。同一批作者还使用他们的树莓派云评估 了另外两个云模拟器GreenCloud和Mininet。21在这项对比研究中,他们采用交叉验证方法,将两个模拟器预测 的性能与树莓派测试平台的实际性能进行比较。根据他们的研究结果,GreenCloud模拟器目前无法准确预测微型 数据中心的能耗。而Mininet在建模网络性能方面则提供了合理的准确性。
DISSECT‐CF模拟器的开发人员最近引入了新的模型和扩展,以估算模拟器中新型组件(如树莓派节点)的行 为。20 本文使用这些新模型对基于树莓派的云进行了模拟。通过一个基于Hadoop的应用场景,将模拟器得到的结 果与真实系统获得的结果进行比较,两个环境均由12个树莓派2B型节点组成。作者声称,使用新模型时,该实验的 结果非常接近,平均绝对误差较低,但目前模拟器的进一步改进仍在开发中。
3 资源分配策略的验证
3.1 通用方法
在开发新的资源分配策略时,可以区分出几个步骤。图1总结了新型云资源分配策略的设计、实现和验证的一般步 骤。最初,设计并实现一种新策略。这可能是一个迭代过程,因为在实现过程中可能会引入额外的约束,从而需要 对原始设计进行修改(图中的反馈箭头1)。一旦实现完成,应通过仿真、在云测试平台上的实验评估,或理想情 况下两者的结合来验证该策略。仿真通常是一个良好的起点,因为它们比实验评估成本更低且更省时。这些仿真可 以从简单的单元测试或批处理脚本,到使用艾哈迈德和萨比亚萨奇列出的仿真器之一对云环境进行完整仿真。7在 这些仿真过程中,可能会发现新的优化点或未预料到的限制,进而需要再次修改策略的实现和/或设计(反馈箭头 2)。
使用真实硬件进行实验评估也应被考虑,因为这些实验通常会带来新见解,并可能再次需要对设计和/或实现进 行修改(反馈箭头3)。例如,评估的设置可能会引入之前未考虑的额外硬件约束,或者实验结果可用于更准确地 微调可配置参数。然而,在物理硬件上进行实验既昂贵又耗时。这对于新资源分配策略的设计和微调尤为明显,因 为这通常需要使用多个云实例进行多轮渐进式迭代实验。当执行的实验在执行过程中失败时,例如由于硬件约束或 有缺陷的算法,这些实验可能会变得非常昂贵。因此,在进行大规模实验之前,优先选择在相对小规模测试平台上 进行实验。
尽管可以使用配备多个虚拟机的单个功能强大的服务器作为小规模测试平台,但这种方法存在一些重要限制。首先, 可扩展性受限,因为并行运行的虚拟机数量受到可用资源的限制。理想情况下,服务器应将其资源划分为相等的部分

共享资源,并且虚拟机之间应有明确的隔离,以避免相互影响。此外,虚拟机通过虚拟网络进行互连,该网络的自 定义选项由所使用的虚拟化软件定义。免费虚拟机监控程序通常功能有限,一般安装在操作系统之上,导致明显的 开销。而商用裸金属虚拟机监控程序则除了需要投入服务器硬件外,还伴随着高昂的许可费用。本文介绍的小规模 测试平台解决了这些问题,它在主机之间提供了清晰的隔离,允许对网络拓扑进行完全自定义,并以更低的成本提 供了更高的可扩展性。
理想情况下,新策略也可以在大规模测试平台上进行验证。例如,可以使用第2.1节中描述的大规模学术测试环 境。这些环境支持对新策略进行大规模验证,但通常资源可用性有限,且软硬件维护成本较高。或者,也可以通过 商业公共云提供商来验证新策略。公有云提供商通常采用每实例固定价格或基于实际使用情况的成本模型,这使得 使用大量节点进行实验验证变得非常昂贵。因此,这些大规模私有或公共测试平台应用于大规模成熟验证测试,而 不适合用于具有频繁更新的小型重复性测试。
所提出工作流程的一个潜在问题是,在不同步骤中可能需要具有不同技术背景的人员参与。虽然新策略通常由 研究人员(例如,当该策略基于数学模型时,其具有数学背景)设计,但他或她可能需要开发人员的帮助,以在概 念验证或选定的仿真工具中实现该策略。为了在真实测试平台上执行实验,可能需要系统工程师参与,该工程师需 充分了解物理硬件和网络拓扑,以确保所开发的实验能够在选定的测试平台上顺利运行。
3.2 实践中的实验验证
近年来,关于云环境中资源高效管理的研究已开展了大量工作。表3概述了近期针对资源分配的研究,以及所描述 策略的评估方式(例如通过仿真、小规模或大规模实验,或两者结合的方式)。该列表包含使用IEEE Xplore数字 图书馆找到的与云环境内资源管理相关的出版物,这些出版物发表于2015年至2017年间。列出的大多数策略聚焦于 虚拟机的(静态和/或动态)分配,这些虚拟机通常由所需的CPU周期、内存、磁盘空间和网络带宽数量来定义。
一些策略还考虑了估计或实际的功耗,以及对自定义服务级别协议的合规性要求。
| 出版物 | 目标 | 优化 | 验证方法 | 方法 | 仿真实验 |
|---|---|---|---|---|---|
| Liu 等22 | 虚拟机(任务)请求的分配 | 深度强化 学习 (DRL) | 自定义 | - | |
| Portaluri et al23 | 基于虚拟机实例分配 改进的Dijkstra | MATLAB | - | Simulink | |
| Maenhaut 等人24 | 存储动态分配 装箱问题 | 自定义 | - | 资源 ,基于可定制的 约束 | |
| Khoshkholghi 等人25 | 虚拟机的动态分配, | 自定义算法 | CloudSim | - | 考虑 SLA 约束 关于中央处理器、内存和带宽 |
| Bi等人(2017)26 | 虚拟机的动态分配 | 混合整数非线性规划,模拟 | 自定义 | - | 退火和粒子 Swarm 优化 考虑服务级别协议、已完成和被拒绝的请求以及 能耗 |
| Rampersaud和Grosu27,28 | 虚拟机实例分配, | 装箱问题 | 自定义 | - | 考虑内存共享 共置的虚拟机之间 |
| Atrey 等人29 | 基于服务等级协议的自动扩展 | 自定义算法 | CloudSim | - | 由多个组成的 SaaS 工作流 多租户SaaS服务 |
| Metwally et al30 | 资源通用模型 | MILP | - | 私有云 IaaS云内的资源分配 (80台服务器) | |
| Aral 和 Ovatman (2015)31 | 将虚拟机映射到云数据中心 | LAD子图 | CloudSim | - | 同构求解器 考虑资源利用率, 虚拟机拓扑、性能 和资源成本 |
| Hieu et al32 | 基于虚拟机实例分配 | 自定义算法 | CloudSim | - | 在当前和预测的CPU 利用率 |
| Zhang et al33 | 虚拟机实例分配 | ILP | 自定义 | 私有云 | 减少资源浪费 (4 台服务器) 和功耗 |
在此列表中,值得注意的是,只有两种策略是通过在小规模测试平台上的实验进行验证的,而其他所有策略均是通过 仿真(使用CloudSim或定制开发的仿真软件)进行验证的。特别是当使用自定义仿真软件时,评估结果的质量和可信度 在很大程度上取决于
仿真软件的质量,但通常情况下,论文中缺乏关于模拟器实现方式的足够细节。
3.3 面向嵌入式实验评估
下一节介绍的树莓派测试平台旨在通过提供一个低成本且易于使用的小规模测试平台,促进向嵌入式实验的过渡, 用于对新型资源分配策略进行初步实验评估。如表3所示,近年来开发的大多数策略都集中在虚拟机分配(通常称 为虚拟机打包)以及托管虚拟机所需的各类资源(通常是中央处理器、内存、存储和网络带宽)。通过提供一个简 单的REST接口来监控这些资源,所开发的算法可以轻松接入该测试平台,而无需深入研究OpenStack等复杂云平 台的技术细节。该测试平台并非用于分配虚拟机,而是专为容器分配而设计,因此非常适合用于验证面向容器放置 的策略。与传统虚拟机相比,容器技术具有显著更低的开销,因为容器直接在Linux内核上运行,而最新的树莓派 3B型性能足以承载多个容器。此外,当实验被设计为在容器内执行时,若大规模测试平台也支持相同的容器技术, 则向大规模测试平台迁移的过程将更加简便;这通常不会成为问题,因为Docker等主流容器技术可轻松安装在所 有常见的操作系统上。
以高度细化的方式查看其自定义环境,并为所有进程提供详细的跟踪记录。另一个例子是 iLab.t 虚拟墙,14一个用 于高级网络、分布式软件和服务仿真与评估的大规模通用测试环境。虚拟墙由超过 4000 核心分布在 400 多台物理 服务器上组成,这些服务器在软件安装和网络拓扑方面均可完全配置。CloudLab、Chameleon 云和 iLab.t 虚拟 墙允许研究人员创建自己的云,可用于资源管理策略的大规模实验验证。然而,正如我们将在第3节中讨论的那样, 这些测试平台更适合进行较大规模的成熟验证测试,而不适合失败风险较高的初步实验。
Hyperdrive15是一个高度可重构的云测试平台,通过提供辅助的基础设施设置和配置,用于实验性评估攻击和 缓解措施对真实云系统的实际影响。为实现这一目标,它使用一个管理服务器,负责在平台上部署虚拟机监控器 (hypervisor)和自定义镜像。该管理服务器包含DHCP服务器、TFTP 服务器、HTTP 服务器、MQTT 服务器、 云镜像以及包含部署shell脚本的最小化实时Linux操作系统。客户端机器通过预启动执行环境进行网络启动,并获 取Debian 实时操作系统。Hyperdrive的架构与RPiaaS非常相似,因为RPiaaS测试平台也由一个负责部署的管理 节点和多个通过网络启动的工作节点组成,以提供一个高度可配置的测试平台。与Hyperdrive的主要区别在于, RPiaaS提供的是一个通用云测试平台,专为验证资源分配策略而设计,而Hyperdrive测试平台则针对聚焦于云安 全攻击与防御的实验进行了定制。
2.2 RaspberryPi测试平台
为了促进向实验验证的迈进,构建了一个低成本树莓派测试平台,可用于新型云资源分配策略的初步小规模实验验 证。目前已有其他一些项目使用树莓派节点来搭建小规模云测试平台,如表2所示。例如,亚伯拉罕森等人16构建了 一个由300个节点组成的树莓派云集群。该云采用树莓派1型B版节点搭建,这是最早商用的树莓派型号之一,搭载 ARM 700 MHz CPU,单芯片上最大配备512 MB内存。在该测试平台中,基于Debian的定制操作系统被复制到所 有独立的SD卡上,每个节点在启动时向主树莓派节点请求配置文件,并最终注册到集群。主节点负责处理所有节点 的注册与注销请求,并监控当前已注册的所有节点。该测试平台被用于实现一个分布式存储系统,其中所有节点通 过NFS挂载连接到主节点的中心化NAS上的共享卷。然而,逐个更新内存卡是一个繁琐且耗时的过程,尤其考虑到 测试平台中节点数量相对较多。
Pahl等人17通过描述由树莓派节点组成的边缘PaaS云架构,扩展了亚伯拉罕森等人16的初步研究。结合物联网 设备,计算可被推向云的边缘(即树莓派测试平台),而不是将所有数据发送到中心化云。作者同样使用了树莓派 1型B版节点,在所提出的架构中,每个节点都运行Docker服务以托管容器。采用Debian 7镜像来支持存储与集群 管理等核心中间件服务。对于集群管理,开发了一个自定义专用工具,用于节点的底层配置、监控和维护。主节点 负责节点的(注销)注册。在存储管理方面,作者研究了OpenStack Swift,但由于其资源消耗较高,最终也采用 了类似于亚伯拉罕森等人16设置的中心化NAS。
格拉斯哥树莓派云18旨在为云计算基础设施构建一个缩放模型。该云由56个运行Raspbian操作系统的树莓派 1节点组成,操作系统安装在SD卡上,每个节点托管三个Linux容器,以模拟云栈的每一层。
| 测试平台 | 节点型号 | 摘要 |
|---|---|---|
| 亚伯拉罕森等人16 | 树莓派1 | 云集群中,主节点提供配置和注册功能。 |
| Pahl 等人17 | 树莓派1 | 用于物联网设备的、运行Docker的边缘PaaS云。 |
| 格拉斯哥 RPi 云18 | 树莓派1 | 用于云计算的缩放模型,使用LXC容器。 |
| 格拉斯哥 RPi 云19 | 树莓派2和3 | 更新版本,用于评估云模拟器。 |
| Kecskemeti 等人20 | 树莓派2 | 用于评估DISSECT‐CF模拟器的小规模集群。 |
与第4节中描述的树莓派测试平台的主要区别在于:(1)我们专注于构建一个通用的IaaS云测试平台,用于验 证资源分配策略;(2)所有节点通过网络共享挂载根文件系统,而不是将操作系统安装在内存卡上;(3)主节点 使用一个包含集群中所有节点列表的最小化配置文件,而非对节点进行(注销)注册。通过使用网络共享作为根文 件系统,在升级内核或操作系统时更新集群变得更加容易,因为无需单独更新每张内存卡。此外,我们还在不同节 点上使用Docker来托管实验和所需的代理服务。我们的测试平台基于树莓派3B型构建,该型号配备更强大的1.2 GHz 64位四核ARMv8 CPU和1GB内存,因此更适合托管多个Docker容器。
最近,格拉斯哥树莓派云的开发人员通过将树莓派节点替换为较新的树莓派2和3型号,对其云测试平台进行了 升级,并使用更新后的测试平台将其性能与相应的CloudSim模型进行比较。19他们的主要结论是,CloudSim需要 更丰富的输入特征集,并且需要更复杂的模型来模拟分布式应用的节点间通信。因此,根据作者的观点, CloudSim目前在这些实验中的准确性不足,这凸显了实验验证的重要性。同一批作者还使用他们的树莓派云评估 了另外两个云模拟器GreenCloud和Mininet。21在这项对比研究中,他们采用交叉验证方法,将两个模拟器预测 的性能与树莓派测试平台的实际性能进行比较。根据他们的研究结果,GreenCloud模拟器目前无法准确预测微型 数据中心的能耗。而Mininet在建模网络性能方面则提供了合理的准确性。
DISSECT‐CF模拟器的开发人员最近引入了新的模型和扩展,以估算模拟器中新型组件(如树莓派节点)的行 为。20 本文使用这些新模型对基于树莓派的云进行了模拟。通过一个基于Hadoop的应用场景,将模拟器得到的结 果与真实系统获得的结果进行比较,两个环境均由12个树莓派2B型节点组成。作者声称,使用新模型时,该实验的 结果非常接近,平均绝对误差较低,但目前模拟器的进一步改进仍在开发中。
3 资源分配策略的验证
3.1 通用方法
在开发新的资源分配策略时,可以区分出几个步骤。图1总结了新型云资源分配策略的设计、实现和验证的一般步 骤。最初,设计并实现一种新策略。这可能是一个迭代过程,因为在实现过程中可能会引入额外的约束,从而需要 对原始设计进行修改(图中的反馈箭头1)。一旦实现完成,应通过仿真、在云测试平台上的实验评估,或理想情 况下两者的结合来验证该策略。仿真通常是一个良好的起点,因为它们比实验评估成本更低且更省时。这些仿真可 以从简单的单元测试或批处理脚本,到使用艾哈迈德和萨比亚萨奇列出的仿真器之一对云环境进行完整仿真。7在 这些仿真过程中,可能会发现新的优化点或未预料到的限制,进而需要再次修改策略的实现和/或设计(反馈箭头 2)。
使用真实硬件进行实验评估也应被考虑,因为这些实验通常会带来新见解,并可能再次需要对设计和/或实现进 行修改(反馈箭头3)。例如,评估的设置可能会引入之前未考虑的额外硬件约束,或者实验结果可用于更准确地 微调可配置参数。然而,在物理硬件上进行实验既昂贵又耗时。这对于新资源分配策略的设计和微调尤为明显,因 为这通常需要使用多个云实例进行多轮渐进式迭代实验。当执行的实验在执行过程中失败时,例如由于硬件约束或 有缺陷的算法,这些实验可能会变得非常昂贵。因此,在进行大规模实验之前,优先选择在相对小规模测试平台上 进行实验。
尽管可以使用配备多个虚拟机的单个功能强大的服务器作为小规模测试平台,但这种方法存在一些重要限制。首先, 可扩展性受限,因为并行运行的虚拟机数量受到可用资源的限制。理想情况下,服务器应将其资源划分为相等的部分

共享资源,并且虚拟机之间应有明确的隔离,以避免相互影响。此外,虚拟机通过虚拟网络进行互连,该网络的自 定义选项由所使用的虚拟化软件定义。免费虚拟机监控程序通常功能有限,一般安装在操作系统之上,导致明显的 开销。而商用裸金属虚拟机监控程序则除了需要投入服务器硬件外,还伴随着高昂的许可费用。本文介绍的小规模 测试平台解决了这些问题,它在主机之间提供了清晰的隔离,允许对网络拓扑进行完全自定义,并以更低的成本提 供了更高的可扩展性。
理想情况下,新策略也可以在大规模测试平台上进行验证。例如,可以使用第2.1节中描述的大规模学术测试环 境。这些环境支持对新策略进行大规模验证,但通常资源可用性有限,且软硬件维护成本较高。或者,也可以通过 商业公共云提供商来验证新策略。公有云提供商通常采用每实例固定价格或基于实际使用情况的成本模型,这使得 使用大量节点进行实验验证变得非常昂贵。因此,这些大规模私有或公共测试平台应用于大规模成熟验证测试,而 不适合用于具有频繁更新的小型重复性测试。
所提出工作流程的一个潜在问题是,在不同步骤中可能需要具有不同技术背景的人员参与。虽然新策略通常由 研究人员(例如,当该策略基于数学模型时,其具有数学背景)设计,但他或她可能需要开发人员的帮助,以在概 念验证或选定的仿真工具中实现该策略。为了在真实测试平台上执行实验,可能需要系统工程师参与,该工程师需 充分了解物理硬件和网络拓扑,以确保所开发的实验能够在选定的测试平台上顺利运行。
3.2 实践中的实验验证
近年来,关于云环境中资源高效管理的研究已开展了大量工作。表3概述了近期针对资源分配的研究,以及所描述 策略的评估方式(例如通过仿真、小规模或大规模实验,或两者结合的方式)。该列表包含使用IEEE Xplore数字 图书馆找到的与云环境内资源管理相关的出版物,这些出版物发表于2015年至2017年间。列出的大多数策略聚焦于 虚拟机的(静态和/或动态)分配,这些虚拟机通常由所需的CPU周期、内存、磁盘空间和网络带宽数量来定义。
一些策略还考虑了估计或实际的功耗,以及对自定义服务级别协议的合规性要求。
| 出版物 | 目标 | 优化 | 验证方法 | 方法 | 仿真实验 |
|---|---|---|---|---|---|
| Liu 等22 | 虚拟机(任务)请求的分配 | 深度强化 学习 (DRL) | 自定义 | - | |
| Portaluri et al23 | 基于虚拟机实例分配 改进的Dijkstra | MATLAB | - | Simulink | |
| Maenhaut 等人24 | 存储动态分配 装箱问题 | 自定义 | - | 资源 ,基于可定制的 约束 | |
| Khoshkholghi 等人25 | 虚拟机的动态分配, | 自定义算法 | CloudSim | - | 考虑 SLA 约束 关于中央处理器、内存和带宽 |
| Bi等人(2017)26 | 虚拟机的动态分配 | 混合整数非线性规划,模拟 | 自定义 | - | 退火和粒子 Swarm 优化 考虑服务级别协议、已完成和被拒绝的请求以及 能耗 |
| Rampersaud和Grosu27,28 | 虚拟机实例分配, | 装箱问题 | 自定义 | - | 考虑内存共享 共置的虚拟机之间 |
| Atrey 等人29 | 基于服务等级协议的自动扩展 | 自定义算法 | CloudSim | - | 由多个组成的 SaaS 工作流 多租户SaaS服务 |
| Metwally et al30 | 资源通用模型 | MILP | - | 私有云 IaaS云内的资源分配 (80台服务器) | |
| Aral 和 Ovatman (2015)31 | 将虚拟机映射到云数据中心 | LAD子图 | CloudSim | - | 同构求解器 考虑资源利用率, 虚拟机拓扑、性能 和资源成本 |
| Hieu et al32 | 基于虚拟机实例分配 | 自定义算法 | CloudSim | - | 在当前和预测的CPU 利用率 |
| Zhang et al33 | 虚拟机实例分配 | ILP | 自定义 | 私有云 | 减少资源浪费 (4 台服务器) 和功耗 |
在此列表中,值得注意的是,只有两种策略是通过在小规模测试平台上的实验进行验证的,而其他所有策略均是通过 仿真(使用CloudSim或定制开发的仿真软件)进行验证的。特别是当使用自定义仿真软件时,评估结果的质量和可信度 在很大程度上取决于
仿真软件的质量,但通常情况下,论文中缺乏关于模拟器实现方式的足够细节。
3.3 面向嵌入式实验评估
下一节介绍的树莓派测试平台旨在通过提供一个低成本且易于使用的小规模测试平台,促进向嵌入式实验的过渡, 用于对新型资源分配策略进行初步实验评估。如表3所示,近年来开发的大多数策略都集中在虚拟机分配(通常称 为虚拟机打包)以及托管虚拟机所需的各类资源(通常是中央处理器、内存、存储和网络带宽)。通过提供一个简 单的REST接口来监控这些资源,所开发的算法可以轻松接入该测试平台,而无需深入研究OpenStack等复杂云平 台的技术细节。该测试平台并非用于分配虚拟机,而是专为容器分配而设计,因此非常适合用于验证面向容器放置 的策略。与传统虚拟机相比,容器技术具有显著更低的开销,因为容器直接在Linux内核上运行,而最新的树莓派 3B型性能足以承载多个容器。此外,当实验被设计为在容器内执行时,若大规模测试平台也支持相同的容器技术, 则向大规模测试平台迁移的过程将更加简便;这通常不会成为问题,因为Docker等主流容器技术可轻松安装在所 有常见的操作系统上。
4 树莓派测试平台
本节介绍了树莓派测试平台的设计,以及用于管理和监控该测试平台的RPiaaS。在IEEE INFOCOM 2017会议上曾 展示过运行RPiaaS的测试平台初始版本35,但此后其设计和实现已发生显著变化。目前所有必需的管理服务均在 Docker容器内运行,且这些服务所需的所有配置文件均由主节点自动生成。在最初的集群中,使用一个树莓派节 点作为主节点,所有服务的初始配置过程十分耗时。得益于Docker容器的可移植性,现在任何基于Unix的主机都 可用作主节点,且初始设置时间大大缩短,只需创建一个中央基础镜像和一个描述测试平台拓扑结构的单一配置文 件即可。RPiaaS的开发源代码已通过GitHub向公众开放36,我们鼓励该领域的其他研究人员尝试并根据自己的研 究项目自定义该代码。
4.1 需求
在构建用于资源分配策略实验验证的云测试平台时,应满足以下要求。
•自定义镜像的轻松部署:树莓派计算模块设计为从安装在板上的内存卡启动操作系统。在这种情况下,更新所有 节点上的操作系统可能是一项非常繁琐且耗时的任务,因为每张内存卡都需要被取出、刷写并重新安装。在构建云 测试平台时,应该能够集中地对不同节点上的软件进行一次更新,然后测试平台应提供一种机制将该镜像部署到所 有节点上。
•轻松访问当前和历史资源使用数据:许多资源分配策略基于实际和/或历史资源使用情况来做出决策,以选择最适 合托管特定服务的节点。如果测试平台为此类信息提供了便捷的接口,则在该测试平台上实现所开发的算法将变得 非常简单。
•最低管理开销:为了管理和监控测试平台中的各个节点,需要在所有节点上安装一些额外的软件。该软件应轻量 且资源使用情况较低,为节点执行实验保留足够的空闲资源。
•易于自定义或扩展:每个实验都有不同的需求,在测试平台设计过程中考虑所有可能的需求并不容易。然而,通 过以简洁和模块化的方式设计测试平台软件,应能轻松地对测试平台进行扩展或自定义,以支持各种可能的场景。
本章介绍的树莓派测试平台旨在满足上述所有要求。为了便于部署自定义镜像,节点配置为通过网络启动,而 不是使用内部内存卡。该测试平台提供了一个仪表盘和REST API,用于监控当前和历史的资源使用情况。为此, 在测试平台的每个节点上都安装了一个轻量级服务,用于监控本地资源使用情况。测试平台软件由多个在容器内运 行的微服务组成,这有助于管理服务在硬件和操作系统的异构环境中进行部署,并且使得软件能够轻松地针对各种 实验进行自定义,因为各个服务可以方便地替换。
4.2 架构

图2 展示了一个可能的树莓派测试平台拓扑结构的粗略概述。该测试平台由多个工作节点组成,这些节点被聚合为 每五个节点组成的小型集群。该测试平台使用最新的树莓派3B型节点构建,但任何树莓派型号均可作为工作节点使 用。集群中的每个节点通过以太网交换机相互连接,并通过主节点管理各个工作节点。该主节点可以是树莓派,也 可以是运行合适Linux发行版和所需主控服务的笔记本电脑或台式机等其他设备。为了实现对集群的管理与监控, 开发了作为服务的树莓派(RPiaaS),其包含两个主要组件。
•集群代理服务(CAS),部署在所有工作节点上,用于获取节点的使用信息并控制该节点上的实验,以及
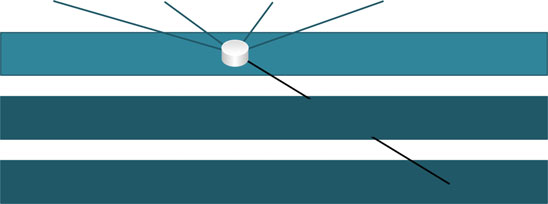
•集群管理服务(CMS),部署在主节点上,通过应用程序编程接口(API)提供对整个测试平台的访问,并提供 一个基于网页的仪表板以监控和管理工作节点。
在主节点上,需要以下服务。
一个DHCP服务器,将用于向不同的工作节点分配IP地址, 一个DNS服务器,将被集群中的所有节点使用 用于网络启动的TFTP服务器,
•一个NFS服务器,因为所有节点都将通过网络共享挂载根文件系统,
•提供对节点的用户友好型访问的集群管理服务 (CMS),以及 用于存储历史资源使用数据的NoSQL数据库系统。
每个工作节点都运行着轻量级CAS,用于与主节点通信。该服务使用Node.js实现,并提供RESTful API,用 于监控节点上的资源使用情况以及控制节点上的实验。主节点上运行着集群管理服务(CMS),该服务使用 Node.js、Python、HTML、JavaScript和Bash脚本实现。该服务为整个测试平台提供RESTful API,同时提供 一个基于网页的仪表板。表4总结了可用的API方法,可用于监控不同工作节点的资源利用率。在给定的路径中, {c}应替换为集群标识符,而{n}对应工作节点标识符。每个集群及集群内的每个节点都应具有唯一标识符。所有 GET请求将返回包含所请求信息的JSON对象。在获取有关集群或单个节点的信息之前,应首先调用ping方法以确 定所选集群或工作节点是否在线。
| 方法 | Path | 描述 |
|---|---|---|
| GET | /info | 已配置集群的概述 |
| GET | /{c}/info | 有关集群的一般信息,包括工作节点列表 |
| GET | /{c}/{n}/ping | 检查所选节点是否可访问 |
| /{c}/{n}/all | 返回以下描述的所有信息 | |
| /{c}/{n}/uptime | 返回系统和集群代理服务的运行时间(以秒为单位) | |
| /{c}/{n}/usage/cpu | 返回每个核心的实际CPU使用率以及有关CPU的一些信息 | |
| /{c}/{n}/usage/memory | 返回实际内存(RAM)使用情况 | |
| /{c}/{n}/usage/disk | 返回实际磁盘使用率(基于 /data 目录) |
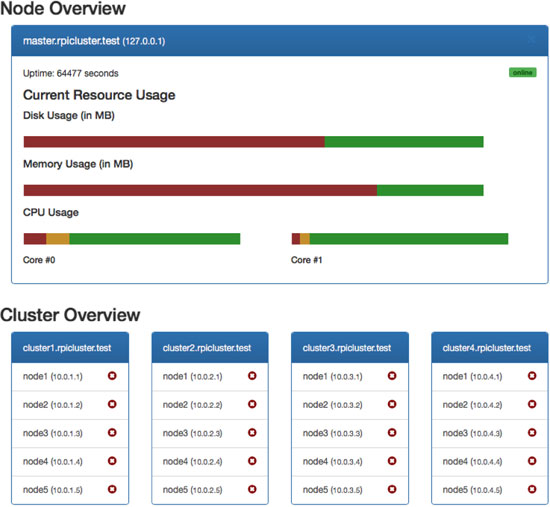
图3显示了测试平台的一小部分,而图4展示了集群管理服务提供的仪表盘的部分屏幕截图。集群管理服务以可配置 的时间间隔(例如每60秒)轮询所有工作节点。在此更新期间,通过从工作节点获取当前的资源利用率(CPU负载、内 存使用率和本地磁盘使用率)。

RESTful API。这些信息随后存储在主节点的中央数据库中。通过这种方式,不仅可以显示管理界面上的实际资源 使用情况,还可以显示每个工作节点的历史使用情况。集群管理服务(CMS)和CAS都是轻量级的,消耗较少的系 统资源,具体将在第5节中说明。由于采用模块化设计,这两种服务都可以轻松扩展或自定义,以支持各种实验。
4.3 微服务与容器
RPiaaS 的两个服务以及所有其他必需的服务(例如 DHCP 和 NFS)均作为微服务在 Docker 容器内运行,所有服 务都通过自定义的 Docker‐compose 文件进行部署。这使得在多种不同的操作系统上部署 RPiaaS 变得简单直接, 且这些容器甚至可以通过 Kubernetes 或 Docker Swarm 部署到 Swarm 中。针对基于 ARM 的系统(例如使用 树莓派作为主节点)和基于 x86/x64 的系统(例如在基于Linux的桌面部署主控服务),分别提供了独立的 Docker‐compose 文件。图5 展示了运行在不同 Docker 容器内的各个微服务的概览。RPiaaS 系统设置包含 5 个 不同的容器:
• rpiaas-cms 是一个运行上述 RPiaaS 集群管理服务的 Docker 容器。该容器使用最新的节点镜像作为基础镜像, 并通过单个 JSON 文件对测试平台进行配置。集群管理服务提供用户友好型仪表板,以及面向整个测试平台的应用 程序编程接口。此外,所有其他微服务所需的配置文件均可在集群管理服务中自动生成。
• rpiaas-mongo是一个运行MongoDB实例的Docker容器,用于存储历史资源使用数据。
rpiaas-dnsmasq容器托管一个dnsmasq实例,负责向各个节点提供DNS、DHCP和TFTP服务。由于该容器需要在 物理网络接口上监听DHCP请求,因此配置为在主机网络模式下运行。
• rpiaas-nfs容器托管了一个nfs-kernel-server实例,这是NFS服务器的一种流行实现,用于向测试平台的所有节点提 供基础镜像。
• rpiaaS‐cas 是一个运行RPiaaS CAS的Docker容器。这是唯一需要部署到所有节点上的服务,而所有其他服务 仅部署在主节点上。
尽管多个容器需要自定义配置文件,但集群的初始配置仅需一个JSON文件。集群管理服务容器随后会自动为 其他容器生成所有必需的配置文件。这些配置文件可通过基于网页的仪表板下载,或通过以下方式获取
使用简单的 curl 或 wget 请求的脚本。因此,首次在主节点上启动服务时,最初只需启动 rpiaas-cms 容器以获取 其他容器的配置文件。配置文件需要保存到相应的目录中,之后便可启动其他容器。这些步骤可以轻松实现自动化, 例如通过使用 bash 脚本。
需要注意的是,由于rpiaaas‐dnsmasq容器需要使用主机网络模式,RPiaaS仅在基于Unix的操作系统上才 能完全正常运行。这意味着该容器将与物理主机共享网络适配器。在某些Docker发行版中,例如Docker for Windows或MacOS,Docker守护进程是在虚拟机内运行的。因此,网络接口不会桥接到物理网络适配器,而是 桥接到通过内部NAT网络连接到主机的虚拟网络接口。
4.4 启动工作节点
最新的树莓派3B型提供了(实验性)网络启动支持,使用预启动执行环境。然而,由于较旧的节点(例如最初的树 莓派和树莓派2B型)不支持此功能,因此添加了对两种不同启动模式的支持,如图6所示:
•一种完整的网络启动,其中工作节点从TFTP服务器加载内核和引导文件。在加载内核和所需的引导文件后,根文 件系统作为NFS网络共享挂载。对于这些工作节点,内部SD内存卡仅用作本地存储(例如用于存储容器),而引 导文件或操作系统均不位于内存卡上。
•从本地内存卡引导,并使用网络共享作为根文件系统。在此模式下,内核和引导文件需要复制到SD卡的一个小型 FAT32启动分区上(例如,大小为100 MB)。在该启动分区中,config.txt(这是树莓派启动时使用的主要配置文 件,替代传统计算机中的BIOS)被配置为通过NFS网络共享挂载根文件系统。加载内核和引导文件后,工作节点 继续通过NFS加载操作系统,类似于之前的引导模式。内存卡的其余部分被格式化为第二个ext4分区,用作本地存 储。
两种模式之间的唯一区别在于内核和引导文件的加载方式。在进行完全网络启动时(仅树莓派3支持),这些 文件从TFTP服务器加载,由于文件集中管理,因此可以非常方便地更新所有工作节点上的内核。在第二种启动模 式中,内核和其他引导文件需要复制到内存卡上,因此要更新内核时,必须逐一更新所有内存卡。然而,这两种启 动模式都通过NFS网络共享挂载根文件系统。因此,基础镜像(包含操作系统)

并且所需的软件包可以集中更新或修改,而无需移除所有内存卡(只要新的基础镜像使用相同的内核)。第4节.5 详细总结了创建启动分区(TFTP或本地内存卡)和基础镜像(NFS)所需的步骤。
在传统的云环境中,使用NFS共享作为根文件系统并不常见,但值得注意的是,云数据中心内部的物理服务器 通常通过网络使用iSCSI来挂载LUNs,从而将存储与计算资源分离,这一点是类似的。然而,在这种情况下,存储 网络通常与虚拟机网络相分离,并且经常使用带有高速光纤连接的专用交换机,以实现最大的磁盘吞吐量。在 RPiaaS测试平台中,我们本可以使用iSCSI代替NFS来挂载根文件系统,但这会导致更复杂的设置和配置,并增加 主节点的开销。我们也没有将存储网络进行分离,但正如本文后面将讨论的那样,NFS引入的开销将非常小,因为 执行的实验所使用的容器将存储在本地内存卡上,而不是NFS共享中。
4.5 准备基础镜像
为了创建一个可供所有工作节点使用的基础镜像,可以使用一个独立树莓派节点。在安装好首选的操作系统和所有 必需的软件包后,可以通过SSH使用rsync将根文件系统的完整副本传输到主节点,例如通过在主节点上执行清单1 中的命令。在此示例中,来自独立工作节点(IP地址为node_ip)的根目录通过rsync复制到主节点上的/nfs/base/文 件夹(该命令在主节点上执行)。根文件系统传输完成后,可以将独立节点的/boot分区复制到主节点上用于 TFTP的目录,或复制到一个临时文件夹,以便在网络启动准备内存卡时将这些文件重新复制回启动分区。复制完/ boot分区的文件后,应修改cmdline.txt文件,如清单2所示,以告知工作节点通过NFS挂载根文件系统。请注意,此 文件中不配置NFS服务器和NFS根路径,因为这些设置会在启动时从DHCP服务器自动获取。
尽管CAS可以直接在树莓派的操作系统上运行,但我们更倾向于在工作节点上安装Docker,并在Docker容器 中启动CAS。通过这种方式,其他实验也可以在节点上的容器中执行,甚至可以将工作节点配置为Docker集群。
Docker在许多常见的操作系统(如Raspbian)上都受到官方支持,并且可以通过单个命令轻松地在树莓派上安装。
建议同时安装Docker‐compose,因为该工具可以通过单个YAML文件轻松部署多个容器。安装 Docker‐compose工具有多种方法,但最简单的方法是使用pip(一个基于Python的包管理器)来安装该工具。清 单3总结了用于安装Docker和Docker‐compose的命令。
清单 1 使用 rsync 传输根文件系统
rsync -avz --exclude='/proc/*' --exclude='/sys/*' --exclude='/dev/*' --exclude='/run/*' --exclude='/tmp/*' --exclude='/mnt/*' --exclude='/media/*' pi@node_ip:/ /nfs/base/
清单 2 cmdline.txt在 /boot分区中的内容
dwc_otg.lpm_enable=0 console=serial0,115200 console=tty1 root=/dev/nfs nfsroot=192.168.1.1:/nfs/base,vers=3 rw ip=dhcp rootwait
清单 3 在树莓派上安装 Docker 和 Docker-compose
curl -sSL https://get.docker.com | sh
sudo usermod -aG docker pi
sudo pip install docker-compose
然而,当容器存储在基于NFS的文件系统上时,Docker将无法启动容器,因为默认的overlayFS存储驱动仅支 持ext4或xfs底层文件系统。37启动容器时,Docker守护进程将无法为容器创建overlay挂载,并会返回错误消息。
一种变通方法是使用devicemapper作为存储驱动,38但Docker文档强烈不建议这样做,因为它需要配置 direct‐lvm以避免极差的性能。39此外,将所有容器都存储在NFS分区上也是不良做法,因为这会导致工作节点与 主节点之间的网络连接迅速成为瓶颈。更好的解决方案是配置Docker将所有容器和镜像(及其他相关文件)存储 在本地内存卡上,例如存储在 ∕data∕docker文件夹内 er。通过修改Docker守护进程文件(/etc/docker/daemon.json), 可以轻松实现这一点,如代码清单4所示。
清单 4 /etc/docker/daemon.json的内容,用于配置 Docker 将所有文件存储在 /data/docker 文件夹内
{
"data-root": "/data/docker"
}
在转移根文件系统并复制/boot分区后,独立节点的内存卡可以替换为包含单个ext4分区的内存卡,或一个包含 来自已复制/boot文件夹内容的小型启动分区以及将内存卡其余部分格式化为第二个ext4分区的内存卡,具体取决于 第4.4节中使用的启动模式。在启动工作节点之前,需要修改包含挂载分区自动化过程所需信息的/etc/fstab文件, 以便将ext4分区挂载为工作节点上的/data文件夹。例如,在使用本地内存卡上带有启动分区的启动模式时,该文件 可按示例5所示进行配置。
清单 5 /etc/fstab在使用本地内存进行网络启动时 ory card
/dev/mmcblk0p2 /data ext4 defaults,noatime 0 2
所有工作节点都可以使用主节点上已传输的根NFS文件夹的独立副本来作为根文件系统,或者共享同一个文件 夹。当执行的实验在Docker容器内运行时(如果按照清单4配置,则这些容器存储在本地内存卡上),共享NFS文 件夹通常不会出现问题;但在此场景下,建议在 ∕data内创建一个文件夹,或甚至在内存卡上创建一个额外分区, 用于存储诸如/var/log之类的临时文件。然后可以使用UNIX软链接来链接新文件夹,或者如果使用额外分区,则可 通过修改/etc/fstab文件实现自动挂载。
5 性能与成本比较
在本节中,我们通过三个基准实验评估第4节中描述的RPiaaS测试平台的性能,这些实验分别侧重于中央处理器性 能、磁盘I/O和内存带宽。对于每个实验,实现了两个版本:第一个版本设计为直接在主机的操作系统上运行,而 第二个版本则在Docker容器内执行。这两个版本均在四种不同的环境中运行:单个树莓派3节点、RPiaaS测试平台 的一个工作节点(运行CAS并通过CMS管理)、运行在私有云环境中的虚拟机,以及托管在亚马逊EC2公有云环境 中的虚拟机。这些实验不仅提供了树莓派测试平台与传统云环境相比的性能洞察,还提供了有关RPiaaS平台引入的 开销以及使用容器所带来的开销的有用信息。在本节末尾,我们还从资本支出和运营支出的角度,比较了RPiaaS测 试平台与公有云和私有云环境的成本。
5.1 基准实验
5.1.1 中央处理器性能
首先执行的实验是CPU基准测试,该测试基于素数计算,使用开源的Sysbench40基准测试套件。在此基准测试中, 检查从3到给定最大值max_prime之间的所有数字是否为素数,并返回素数的总数,如代码列表6所示。此操作重复 10000次,使用指定数量的线程。测量总执行时间以及每次操作所需的时间。
代码列表6 Sysbench CPU基准测试中的相关代码
for (int num = 3; num <= max_prime; num += 2) {
int is_prime = 1;
for (int i = 3; i * i <= num; i += 2) {
if (num % i == 0) {
is_prime = 0;
break;
}
}
if (is_prime) prime_count++;
}
5.1.2 磁盘 I/O 性能
第二个实验

















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









