




什么是数据异构?简单讲,就是将数据进行异地数据异构存储。
数据异构
服务市场使用 BinLake(京东 MySQL 的 Binlog 日志实时采集、统一分发、消息订阅和监控服务)进行数据异构,即通过订阅 MySQL 的 Binlog 日志,通过接收 JMQ 进行数据异地构建存储。
数据异构主要有两种方式,一种是顺序消费、另一种是并行消费。其中,在进行订单、订购的数据异构时是要求保证严格的顺序性的,因为并行消费是无法保证订单的先后顺序的,所以可能造成数据不一致。
但顺序消息的问题主要是单点消费效率慢的问题,以及消费出了问题就会造成阻塞,之前使用服务器进行消费,通过 ip 限制保证单点,后期切换到流式计算平台(strom/flink)进行处理,流式计算在并行写 es 和 jimdb 有天然的优势,但如果异常情况下出现写操作失败,对于 JMQ 的重试系统要做好幂等操作的处理。
订单数据同构
订单数据为顺序消费,一条订单数据,在插入 MySQL 时通过订阅 Binlog,通过 Flink 异构到 Elasticsearch 中。由于是单条记录,不涉及并发消费,可以订阅 Master MySQL。
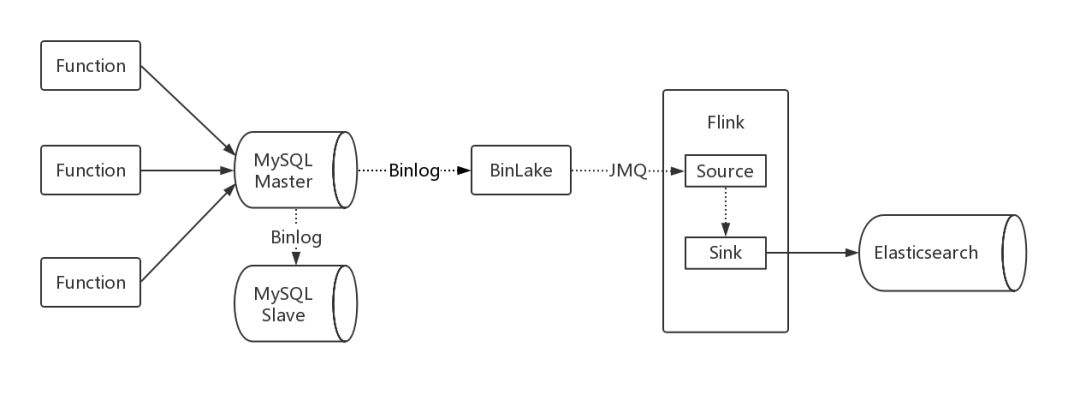
订购数据异构
订购数据的数据异构有些不同,订购数据分为主表和扩展表,在 MySQL 中两张表的数据需要整合异构成一条记录存储到 Es 中。如果采用并行消费,则会出现 Flink 接收消息先后问题,简单说,就是有可能先接收到扩展表的 binlog 后接收到主表的 binlog。
所以改造的方案是,只订阅主表的 binlog,接收到消息后,通过反查 MySQL 的方式,进行数据整合,然后进行数据异构。考虑到对 MySQL 的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2786
2786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









