




 本文详细介绍了如何使用Python的sklearn库进行线性回归建模,包括加载波士顿房价数据集、训练模型、预测及模型评估。模型使用最小二乘法求解参数,并探讨了在稀疏矩阵情况下的求解策略。线性回归的目标是最小化建模误差的平方和,找到最佳拟合直线。最后,展示了如何获取模型的截距和系数等关键参数。
本文详细介绍了如何使用Python的sklearn库进行线性回归建模,包括加载波士顿房价数据集、训练模型、预测及模型评估。模型使用最小二乘法求解参数,并探讨了在稀疏矩阵情况下的求解策略。线性回归的目标是最小化建模误差的平方和,找到最佳拟合直线。最后,展示了如何获取模型的截距和系数等关键参数。
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
loaded_data = datasets.load_boston()
data_X = loaded_data.data
data_y = loaded_data.target
model = LinearRegression()
model.fit(data_X, data_y) # 训练模型, 找到规律 截距与斜率
print(model.predict(data_X[:4, :])) # 测试将数据喂到模型中
print(data_y[:4]) # 测试数据的标签
# y=0.1x_1 + 0.2x_2 0.3
print(model.coef_) # y=0.1x_1 + 0.2x_2 0.3 打印x的系数0.1,0.2 相当于每个特征对应的x的系数,对应房价来说,比如楼层、地段等等关于x的参数
print(model.intercept_) # 打印0.3, 跟y轴的交点
print(model.get_params()) # 模型的参数 例如{'copy_X': True, 'fit_intercept': True, 'n_jobs': None, 'normalize': False, 'positive': False},这都是在模型定义的时候默认的
model.score(data_X, data_y) : 返回模型的该次预测的系数R2R^2R2,其中
R2=1−u/vu=((ytrue−ypred)2).sum()v=((ytrue−ytrue.mean())2).sum()R^2=1-u/v \\
u=((y_{true} - y_{pred}) ^ 2).sum() \\
v=((y_{true} - y_{true}.mean()) ^ 2).sum()
R2=1−u/vu=((ytrue−ypred)2).sum()v=((ytrue−ytrue.mean())2).sum()
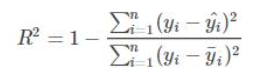
model.fit(data_X, data_y)解析
sklearn.linear_model.LinearRegression求解线性回归方程参数时,首先判断训练集X是否是稀疏矩阵,如果是,就用Golub&Kanlan双对角线化过程方法来求解;否则调用C库中LAPACK中的用基于分治法的奇异值分解来求解。
在sklearn中并不是使用梯度下降法求解线性回归,而是使用最小二乘法求解。
sklearn.LinearRegression的fit()方法:
if self.positive:
if y.ndim < 2:
self.coef_, self._residues = optimize.nnls(X, y)
else:
# scipy.optimize.nnls cannot handle y with shape (M, K)
outs = Parallel(n_jobs=n_jobs_)(
delayed(optimize.nnls)(X, y[:, j])
for j in range(y.shape[1]))
self.coef_, self._residues = map(np.vstack, zip(*outs))
elif sp.issparse(X):
X_offset_scale = X_offset / X_scale
def matvec(b):
return X.dot(b) - b.dot(X_offset_scale)
def rmatvec(b):
return X.T.dot(b) - X_offset_scale * np.sum(b)
X_centered = sparse.linalg.LinearOperator(shape=X.shape,
matvec=matvec,
rmatvec=rmatvec)
if y.ndim < 2:
out = sparse_lsqr(X_centered, y)
self.coef_ = out[0]
self._residues = out[3]
else:
# sparse_lstsq cannot handle y with shape (M, K)
outs = Parallel(n_jobs=n_jobs_)(
delayed(sparse_lsqr)(X_centered, y[:, j].ravel())
for j in range(y.shape[1]))
self.coef_ = np.vstack([out[0] for out in outs])
self._residues = np.vstack([out[3] for out in outs])
else: # 如果X不是稀疏矩阵
self.coef_, self._residues, self.rank_, self.singular_ = \
linalg.lstsq(X, y)
self.coef_ = self.coef_.T
如果训练集X是稀疏矩阵,就用sparse_lsqr()求解,否则使用linalg.lstsq()。
scipy.linalg.lstsq()方法就是用来计算X为非稀疏矩阵时的模型系数。这是使用普通的最小二乘OLS法来求解线性回归参数的。
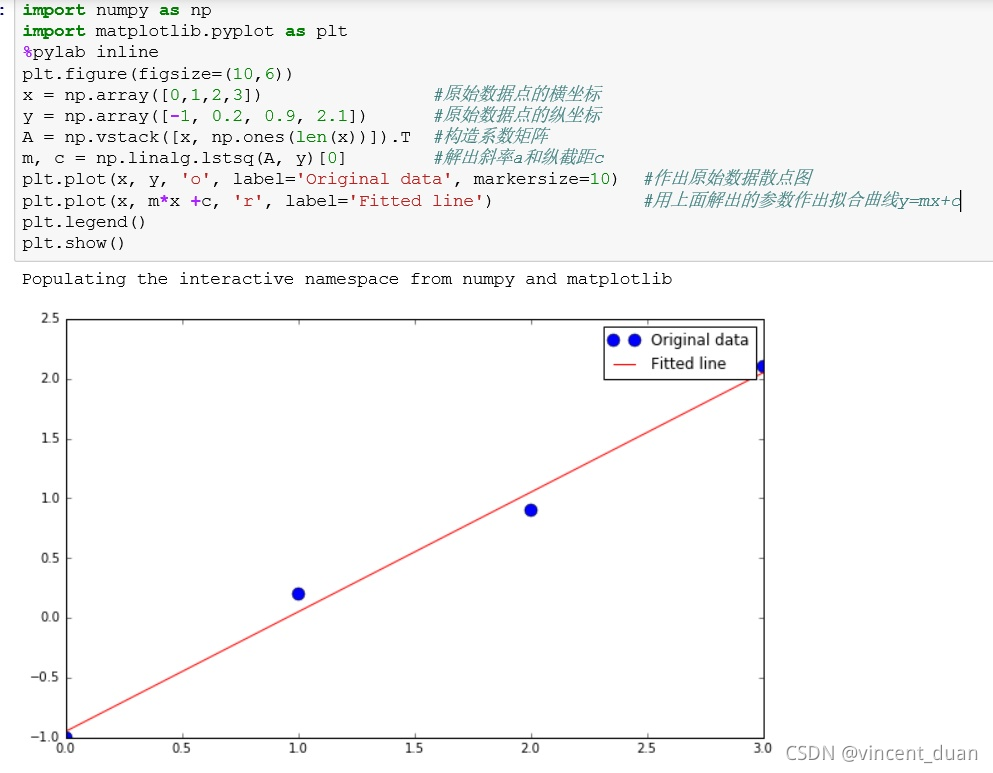
模型的参数可以通过lin_reg.intercept_(截距)、lin_reg.coef_(系数)查看参数。
线性回归拟合原理
拟合就是把平面上一系列的点,用一条光滑的曲线连接起来。因为这条曲线有无数种可能,从而有各种拟合方法。拟合的曲线一般可以用函数表示。
对于一元线性回归(单变量线性回归)来说,学习算法为 y = ax + b 换一种写法:hθ(x)=θ0+θ1x1h_θ(x) = θ_0 + θ_1x_1hθ(x)=θ0+θ1x1
线性回归实际上要做的事情就是: 选择合适的参数(θ0,θ1)(θ_0, θ_1)(θ0,θ1),使得hθ(x)h_θ(x)hθ(x)方程,很好的拟合训练集。实现如何把最有可能的直线与我们的数据相拟合。
我们选择的参数决定了我们得到的直线相对于我们的训练集的准确程度,模型所预测的值与训练集中实际值之间的差距就是建模误差(modeling error)。
我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数。 即使得损失函数最小

















 528
528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









