




 本文介绍如何使用Spark进行数据处理,实现TopN统计,并批量将结果插入MySQL数据库。通过示例展示了从读取Parquet文件,进行SQL查询,到最后使用Scala批量插入数据的全过程。
本文介绍如何使用Spark进行数据处理,实现TopN统计,并批量将结果插入MySQL数据库。通过示例展示了从读取Parquet文件,进行SQL查询,到最后使用Scala批量插入数据的全过程。
在MySQL创建表
create table day_netType_access_topn_stat (
day varchar(8) not null,
uid bigint(10) not null,
times bigint(10) not null,
primary key (day, uid)
)
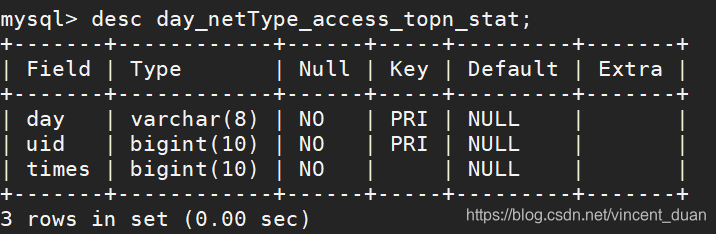
查看表结构:
创建Entity
package cn.ac.iie.log
/**
* 每天访问次数实体类
* @param day
* @param uid
* @param times
*/
case class DayNetTypeAccessStat (day: String, uid:Long, times:Long)
创建Dao
insert
package cn.ac.iie.log
import java.sql.{Connection, PreparedStatement}
import scala.collection.mutable.ListBuffer
/**
* 各个维度统计的DAO操作
*/
object StatDao {
/**
* 批量保存DayVideoAccessStat到数据库
*
* @param list
*/
def insertNetTypeAccessTopN(list: ListBuffer[DayNetTypeAccessStat]): Unit = {
var connection: Connection = null
var pstmt: PreparedStatement = null
try {
connection = MysqlUtils.getConnection()
// 设置手动提交
connection.setAutoCommit(false)
val sql = "insert into day_netType_access_topn_stat (day, uid, times) values (?,?,?)"
pstmt = connection.prepareStatement(sql)
for (ele <- list) {
pstmt.setString(1, ele.day)
pstmt.setLong(2, ele.uid)
pstmt.setLong(3, ele.times)
pstmt.addBatch()
}
pstmt.executeBatch() // 执行批量处理
// 手动提交
connection.commit()
} catch {
case e: Exception => e.printStackTrace()
} finally {
MysqlUtils.release(connection, pstmt)
}
}
}
这里insert数据时,最好使用批处理,提交使用batch操作,手动提交。
将数据保存到Mysql中
package cn.ac.iie.log
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._
import scala.collection.mutable.ListBuffer
/**
* TopN 统计spark作业
*/
object TopNStatJob {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("TopNStatJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled","false")
.master("local[2]").getOrCreate()
val accessDF = spark.read.format("parquet").load("file:///E:/test/clean")
// accessDF.printSchema()
accessDF.show(false)
// 最受欢迎的TopN netType
netTypeAccessTopNStat(spark, accessDF)
spark.stop
}
/**
* 最受欢迎的TopN netType
* @param spark
* @param accessDF
*/
def netTypeAccessTopNStat(spark: SparkSession, accessDF: DataFrame): Unit = {
accessDF.createOrReplaceTempView("access_logs")
val wifiAccessTopNDF = spark.sql("select day,uid,count(1) as times from access_logs where day='20190702' and netType='wifi' group by day,uid order by times desc")
// wifiAccessTopNDF.show(false)
// 将统计结果写入到Mysql中
try{
wifiAccessTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayNetTypeAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val uid = info.getAs[Long]("uid")
val times = info.getAs[Long]("times")
list.append(DayNetTypeAccessStat(day, uid, times))
})
StatDao.insertNetTypeAccessTopN(list)
})
} catch {
case e: Exception => e.printStackTrace()
}
}
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









