




 本文介绍如何使用Spark SQL查询数据并保存至Hive,包括连接MySQL数据库、数据统计及过滤,以及调整分区数量来优化性能。
本文介绍如何使用Spark SQL查询数据并保存至Hive,包括连接MySQL数据库、数据统计及过滤,以及调整分区数量来优化性能。
首先启动spark-shell:
命令:spark-shell --master local[2] --jars ~/software/mysql-connector-java-5.1.35.jar --driver-class-path /home/iie4bu/software/mysql-connector-java-5.1.35.jar
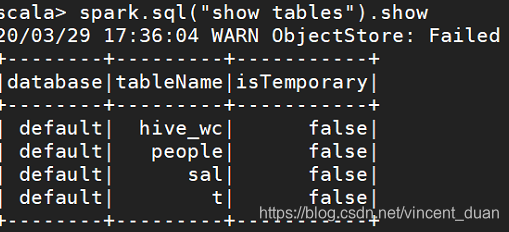
查看当前有哪些表:
spark.sql("show tables").show,结果如下:
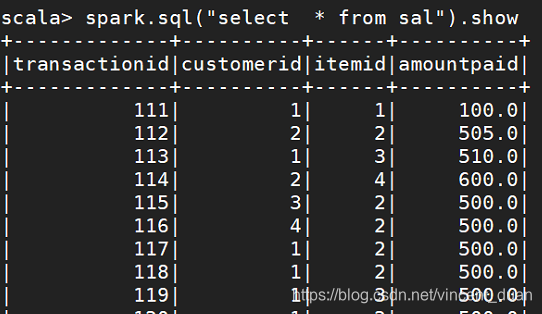
查询sal表:
按照customerid进行统计,然后获取出不是空的customerid:
scala> spark.sql("select customerid,count(1) from sal group by customerid").filter("customerid is not null").show
将查询结果再保存到Hive中
命令:scala> spark.sql("select customerid,count(1) from sal group by customerid").filter("customerid is not null").write.saveAsTable("hive_table_1"),报错信息:

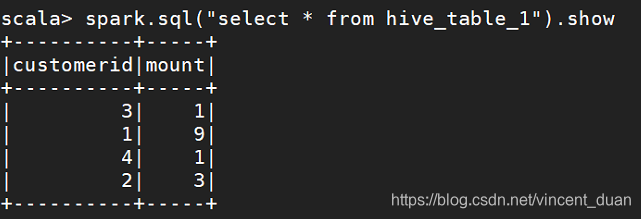
需要修改成:scala> spark.sql("select customerid,count(1) as mount from sal group by customerid").filter("customerid is not null").write.saveAsTable("hive_table_1")
这样查询表就可以看到刚创建的表了:
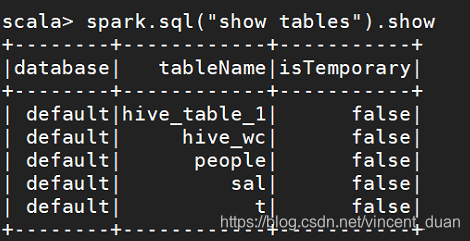
浏览器中查看
我们在浏览器中查看刚才的作业:ip:4040
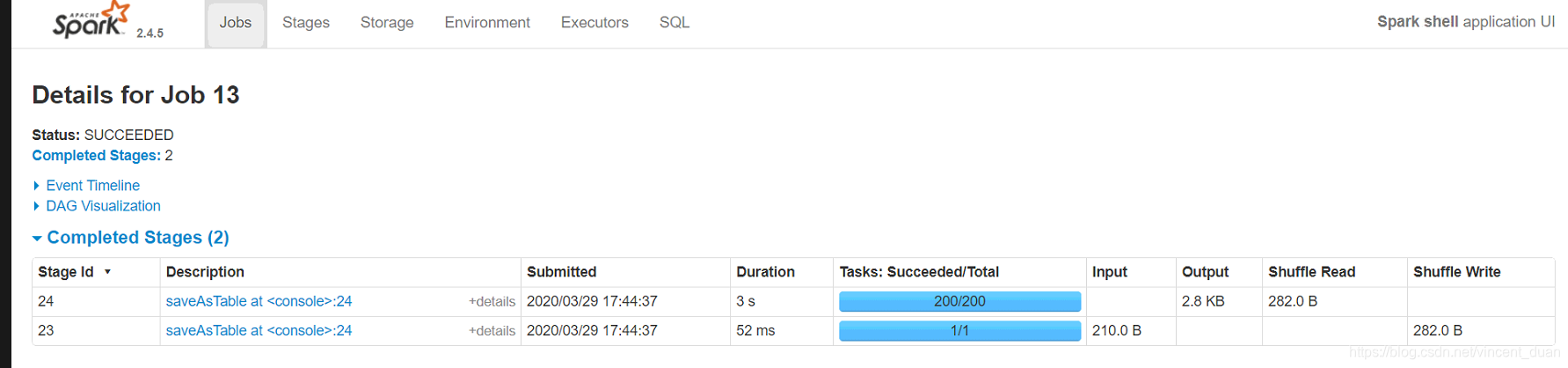

200表示配置分区的数量。
这个值可以手动进行配置:
sparksession.sqlContext.setConf("spark.sql.shuffle.partitions", "10")

然后执行上面的保存成表的操作:
scala> spark.sql("select customerid,count(1) as mount from sal group by customerid").filter("customerid is not null").write.saveAsTable("hive_table_2")
这时再查看看浏览器,发现分区是10了
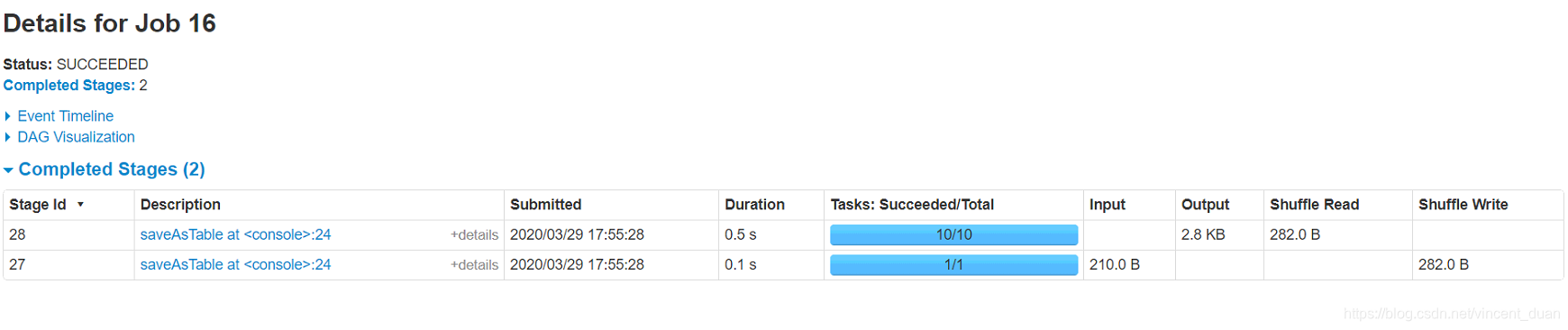
因此在生产环境中,注意设置这个值,默认是200

















 1144
1144




 到【灌水乐园】发言
到【灌水乐园】发言







