




 本文介绍如何在SparkSQL中集成HiveContext,包括配置HiveSite、添加Hive依赖、使用HiveContext处理Hive中的数据。通过具体代码示例展示了如何读取Hive表并显示数据。
本文介绍如何在SparkSQL中集成HiveContext,包括配置HiveSite、添加Hive依赖、使用HiveContext处理Hive中的数据。通过具体代码示例展示了如何读取Hive表并显示数据。
使用SparkSQL时,并不需要搭建一个Hive,只需要一个HiveSite就可以
添加Hive配置文件
将Hive中的hive-site.xml复制到spark中的conf文件夹下。
添加依赖
在pom.xml文件中添加HiveContext的依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
Hive中的数据
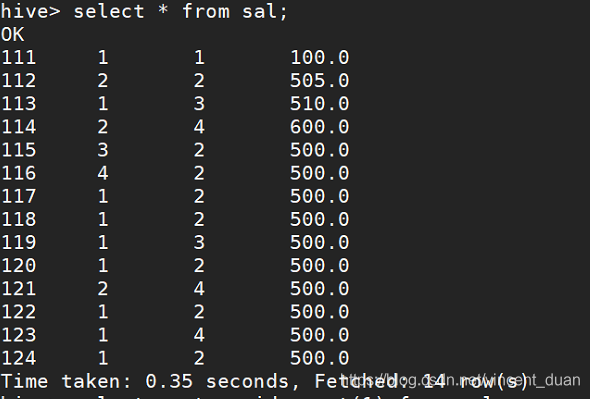
相关代码
package cn.ac.iie.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.hive.HiveContext
/**
* HiveContext的使用
* 使用时需要通过 --jars 把mysql的驱动传递到classpath
*/
object HiveContextApp {
def main(args: Array[String]): Unit = {
// 1. 创建相应的Context
val sparkConf= new SparkConf()
// 在生产或测试环境中,APPName和Master是通过脚本指定的
sparkConf.setAppName("HiveContextApp")
sparkConf.setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val hiveContext = new HiveContext(sc)
// 2. 相关处理:json
hiveContext.table("sal").show()
// 3. 关闭资源
sc.stop()
}
}
使用Maven进行打包:mvn clean package -DskipTests
测试运行
运行前需要添加mysql的JDBC Driver,因此添加一个Driver:mysql-connector-java-5.1.35.jar
运行命令:spark-submit --class cn.ac.iie.spark.HiveContextApp --jars /home/iie4bu/software/mysql-connector-java-5.1.35.jar --master local[2] /home/iie4bu/lib/sql-1.0-SNAPSHOT.jar
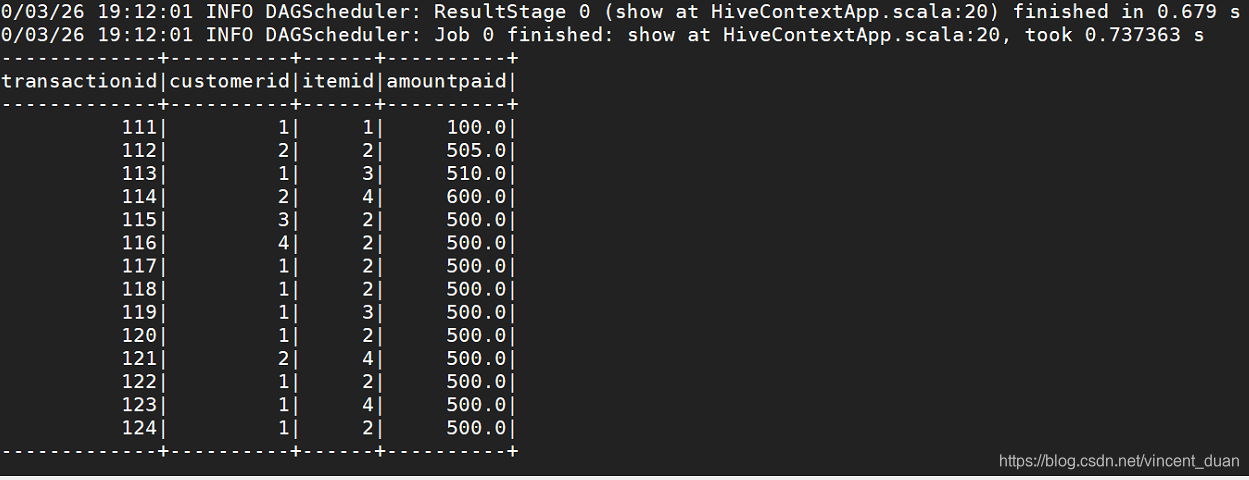
控制台输出结果:

















 2563
2563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









