




 本文深入解析HDFS(Hadoop分布式文件系统)的架构原理,包括NameNode和DataNode的角色及功能,阐述文件如何被切分成block存储,以及NameNode如何管理block与DataNode的映射关系。
本文深入解析HDFS(Hadoop分布式文件系统)的架构原理,包括NameNode和DataNode的角色及功能,阐述文件如何被切分成block存储,以及NameNode如何管理block与DataNode的映射关系。
NameNode(master) and DataNodes(slave)
一个HDFS集群包括一个NameNode和一些DataNode。NameNode管理了一个文件系统的命名空间,可以供客户端访问这些文件。DataNode负责数据的存储。
NameNode暴露出namespace,允许用户的数据存储在文件系统中。
一个文件会被切分成一个或者多个blocks,这些block会被存储在一系列DataNode中。NameNode会执行文件系统namespace操作,例如打开文件、关闭文件、重命名文件或者目录。NameNode存储了block和DataNode的一个映射关系,block的副本数,block的大小等。
例如一个文件a.txt的文件大小时150MB,blocksize=128MB,那么在文件系统中a.txt会被拆分成2个block,一个block1大小是128MB,另一个block2大小是22MB。那么block1存放在哪个DataNode上?block2存放在哪个DataNode上?这就是NameNode的作用,NameNode存放的就是这些元数据信息,即block与DataNode的映射关系,对用户来说时透明的。此外DataNode根据NameNode的具体指令来进行block的创建删除备份等。
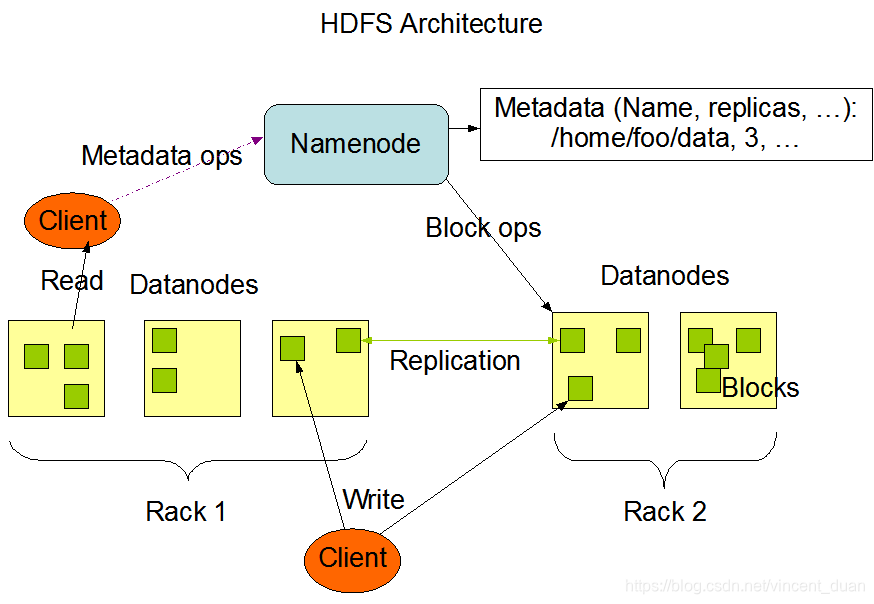
NameNode和DataNode可以运行在普通的机器上。HDFS使用java语言进行开发,因此机器上应该有jdk运行环境,安装完jdk,才可以运行NameNode和DataNode节点。
通常情况下:一台机器部署NameNode,其余机器部署DataNode,并不排斥多个DataNode运行在同一个机器上。

















 181
181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









