 大模型性能核心指标解析
大模型性能核心指标解析







大模型请求过程介绍
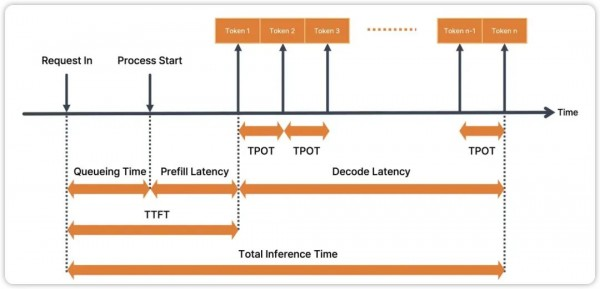
这里这张图非常的清晰,主要就是涉及 TTFT、TPOT、Total Inference Time、 Decode Latency 以及图中没有提及的 TPS,这几个大模型的性能指标不只是适用于纯语言大模型 LLM,也适用于多模态大模型 MLLM,所以还是比较通用
1.TTFT(Time To First Token:首token时间)
定义: 从客户端发送请求到收到第一个SSE事件(通常是第一个文本块)的时间。
重要性: 这是用户感知延迟的最关键指标。即使总生成时间很长,一个快速的首包响应能让用户立刻感觉到“系统已经开始工作了”,体验会好很多。通常要求控制在1秒以内。
2. TGR (Token Generation Rate:令牌生成速率)
定义: 衡量模型输出内容的速度。通常可以折算为 每秒生成的令牌数 (Tokens Per Second - Token/s) 或 每秒生成的字符数/字数。
重要性: 直接决定了用户看到答案的回显速度。速率越高,体验越流畅。
注意: 这个速率可能不是恒定的,可能会随着生成的进行而变化。
3.TPOT(Time Per Output Token:每令牌时间)
定义: 上一个指标(令牌生成速率)分子分母交换
4. TIT (Total Inference Time:总完成时间,总接口时间)
定义: 从请求发送到收到标志流结束的 [DONE|EOF] 事件(或类似信号)的总时间。
重要性: 反映了处理整个请求的整体效率。对于长文本生成,这个时间会显著拉长。
二、性能指标参考
基于常见的 RAG(检索增强生成)架构,使用类似 ChatGPT 3.5 规模的模型(如 7B-13B 参数)的云端部署场景:
| 首token时间(TTFT) | < 1.0s | 非常优秀。用户几乎感觉不到延迟,体验堪比流畅的网页加载。这通常需要高度优化的检索和模型预热。 |
| 1.0 ~ 2.0s | 良好/可接受。用户能感觉到轻微停顿,但不会感到焦躁。这是大多数团队努力达成的目标。 | |
| > 3.0s | 存在风险。用户可能会怀疑系统是否死机,或者重复点击按钮,体验较差。 | |
| 令牌生成速度(TGR) | > 50 token/s | 优秀。答案回显速度很快,类似于一个打字很快的人,阅读体验非常流畅。 |
| 20 ~ 50 token/s | 良好。用户能清晰地看到文字逐个出现,但不会觉得太慢。这是成本和质量的一个平衡点。 | |
| < 20 token/s | 偏慢。用户需要等待较长时间才能看完答案,可能会中途失去耐心。 | |
| 总完成时间(TIT) | – | 这个是根据问题回答难易程度而言,没有参考值 |


















 1006
1006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









