



一种用于乳腺癌检测的双模式深度迁移学习(D2TL)系统,基于对比增强数字乳腺X线摄影
摘要
全视野数字乳腺X线摄影(FFDM)和磁共振成像(MRI)是乳腺癌检测的金标准技术。新兴的对比增强数字乳腺X线摄影(CEDM)融合了FFDM与MRI的互补优势,正逐步被领先医疗机构引入临床实践。目前基于CEDM的临床实践尚不理想,主要依赖临床医生的经验判断。在传统机器学习范式下的自动化诊断系统存在诸多缺陷,例如需要精确的分割、提取不足以表征诊断图像的浅层特征,以及采用缺乏全局目标的顺序设计。我们提出一种基于深度学习(DL)的CEDM诊断系统,其核心是一个新颖的双模态深度迁移学习(D2TL)模型。该系统在多个方面具有创新性,包括:(1)双模式深度架构设计;(2)利用迁移学习在小样本量条件下实现鲁棒模型估计;(3)开发可视化技术以帮助解释模型结果,并促进肿瘤间和肿瘤内恶性程度量化;(4)最小化人为偏差。我们将D2TL应用于来自亚利桑那梅奥诊所的CEDM数据,对良性与恶性肿瘤进行分类。实验结果表明,D2TL优于现有的竞争模型和方法。
关键词 :深度学习;迁移学习;乳腺癌;基于影像的诊断
1. 引言
乳腺癌由于其高发病率和高致病率,导致全球约15%的癌症相关死亡(Ferlay等., 2015)。在美国,约有12%的女性会患上浸润性乳腺癌(Howlader 等., 2017)。美国癌症协会建议对平均风险女性进行筛查测试。如果一名女性没有个人乳腺癌病史或强烈的家族乳腺癌史、无遗传风险因素,并且在30岁之前未接受过胸部放射治疗,则被视为处于平均风险(美国癌症协会,2017)。
全视野数字乳腺X线摄影(FFDM)由于其相对较快的成像时间、低成本和广泛可及性,是乳腺癌筛查和诊断中最常用的技术。然而,由于正常致密乳腺组织引起的遮蔽效应,FFDM的敏感性受到限制。对于有一级亲属乳腺癌病史、已知携带BRCA1/BRCA2基因突变或年轻患者而言,FFDM的敏感性尤其低(Warner etal., 2004)。
动态对比增强磁共振成像(DCE‐MRI)在检测乳腺癌方面具有更高的敏感性,已有相关报道(Berg et al., 2012)。然而,与全视野数字乳腺X线摄影(FFDM)相比,DCE‐MRI的可及性较低,成本更高,且需要更长的成像时间。此外,DCE‐MRI的特异性相对较低,导致对良性肿瘤和/或过度诊断进行不必要的活检比例较高。
这些缺点限制了DCE‐MRI作为乳腺癌筛查首选方法的应用。
对比增强数字乳腺X线摄影是一种新型成像技术,最大限度地结合了全视野数字乳腺X线摄影和动态对比增强磁共振成像的优势。在进行CEDM检查时,通过静脉注射碘基对比剂。两分钟后,分别采集低能量(LE)和高能量(HE)图像。LE图像类似于标准的FFDM图像。随后将HE图像减去LE图像,生成一幅“重组”图像。该重组图像基于与DCE‐MRI相同的原则,突出显示肿瘤新生血管区域。然而,CEDM在图像采集方面比DCE‐MRI便宜得多,且速度快四倍(Patel等,2017)。自问世以来,CEDM已引起广泛关注,并正被全球领先的医疗机构纳入乳腺癌诊疗实践。
目前,如何最优地利用CEDM图像对恶性与良性肿瘤进行分类是研究人员和临床医生亟需回答的最重要问题之一。当前的临床实践主要依赖于放射科医生经过训练的肉眼判断。这已成为阻碍CEDM广泛应用的主要障碍,因为需要专门培训的放射科医生来阅读和解释图像。此外,还存在较大的读者内和读者间变异性,导致CEDM在乳腺癌诊断中的可重复性较低(Tagliafico等人,2016;Lobbes et al.2014)。为了有效应对这些挑战,采用数据驱动的机器学习算法分析CDEM图像以改善诊断结果的自动系统提供了一个有前景的研究方向。
如果使用传统机器学习,一个典型的基于影像的诊断系统将包括三个主要步骤:肿瘤分割、特征提取和分类。
肿瘤分割旨在勾画出肿瘤边界,以便在下一步中从肿瘤区域提取特征。尽管存在计算机化分割算法,但它们通常需要人工干预,例如参数调整和轮廓的手动校正(Wang et al.,2008;Gomez et al., 2010),这可能具有主观性且容易出错。这一局限性在乳腺癌诊断中尤为严重,因为已有研究发现肿瘤形状是预测恶性的重要指标(Naik et al., 2008;Dom ınguez 和 Nandi,2009)。为了正确识别形状,分割算法必须具有很高的准确性,而这是一个难以满足的要求。
分割完成后,通常的下一步是从分割出的肿瘤区域进行特征提取。在基于影像的诊断中,有效的特征提取被认为非常重要(Joo et al., 2004;Armato 和 Sensakovic, 2004;Sun et al., 2013)。医学影像特征通常包括形状和纹理相关特征。如前所述,形状特征高度依赖于分割的准确性。为了提取纹理特征,存在多种纹理分析算法,例如灰度共生矩阵(GLCM;Haralick 和 Shanmugam, 1973)、局部二值模式(LBP;Ojalaet al., 1994)以及 Gabor 滤波器(Gabor,1946)。然而,这些算法中的每一个都有多个调优参数,其选择往往是随意的。因此,有用特征的提取需要通过试错法完成,且通常可重复性较低 (Schwedt et al., 2015;Huet al., 2015)。此外,所有形状和纹理特征都被认为是“浅层”特征。与深度学习 (DL)算法提取的特征相比,它们较为浅层,因为这些特征仅包含对观测图像的一到两层抽象层次,难以充分反映诊断图像的复杂性。最后,在特征提取之后是分类步骤,即使用先前提取的特征训练分类器,以将肿瘤分类为恶性或良性。可供选择的分类算法种类繁多,从线性到非线性,从参数化到非参数化,从生成式到判别式,例如回归、支持向量机(SVM)和随机森林等。
基于传统机器学习的前述三步诊断系统存在明显局限性。除了每一步骤内部的固有缺陷外,这三个步骤是依次进行的,而非处于一个集成框架中。顺序系统的风险包括:(1)误差传播;即早期步骤中的错误会影响后续步骤;(2)次优性;即由于每个步骤仅针对局部目标进行优化,无法保证全局最优性能。
深度学习(DL)的出现开启了机器学习和人工智能 (AI)的新范式。近年来,深度学习在计算机视觉的许多领域取得了成功,包括医学影像。与基于传统机器学习的三步诊断系统相比,深度学习驱动的系统具有多项优势。
首先,深度学习革新了特征提取。通过将观测到的图像视为多个不同层次上分层抽象的结果,深度学习通过从低层特征构建高层特征,提取出特征的深度层次结构,从而前所未有地挖掘出图像中蕴含的丰富信息。其次,在深度架构的优化过程中,特征提取与分类被集成在一起,而传统机器学习则将这两个步骤分离。
在本文中,我们提出了一种基于CEDM的深度学习驱动的乳腺癌诊断系统,其核心是一种新型的双模式深度迁移学习(D2TL)模型。除了利用深度学习架构的最新发展外,D2TL系统还在以下几个方面具有创新性:
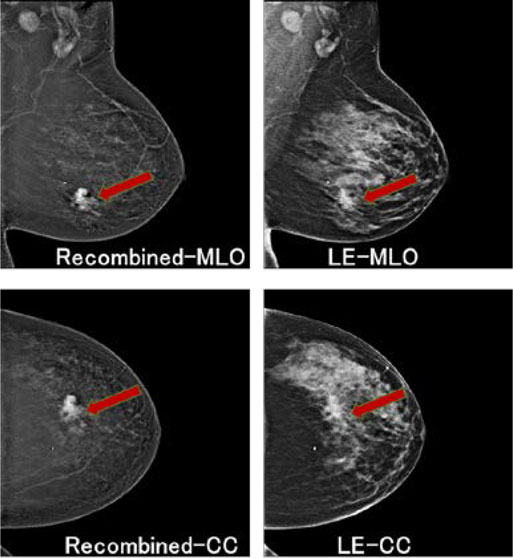
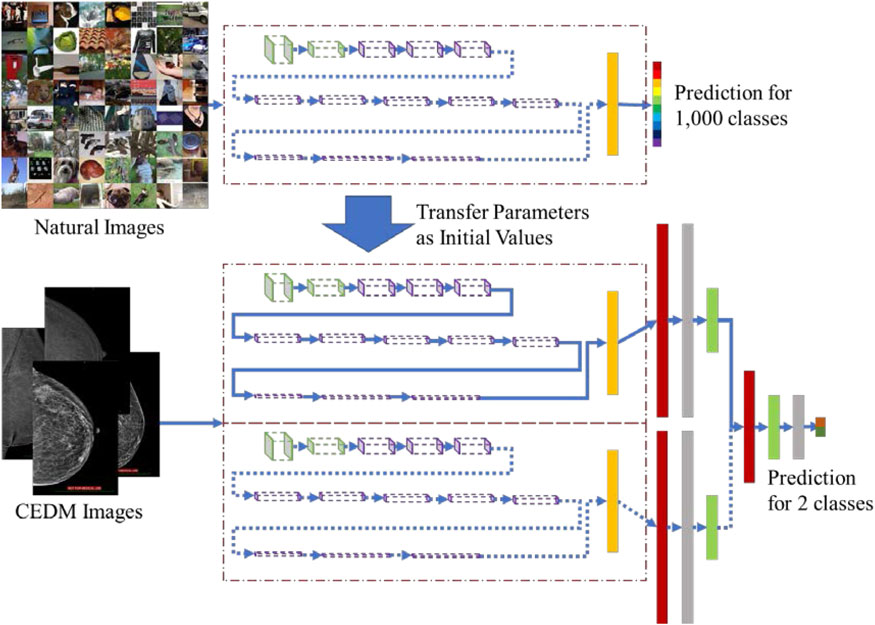
我们提出了一种新颖的双模态深度架构,以应对CEDM图像的特殊特性。如前所述,CEDM检查分别在低能量( LE)和高能量(HE)下生成图像。在每种能量下,均有两张图像对应于可疑乳腺的两个视角,即内外斜位( MLO)和头尾位(CC)。通过从HE‐MLO图像中减去 LE‐MLO图像,得到重组MLO图像;类似地,可获得重组CC图像。因此,在乳腺癌诊断中需要检查四张图像: LE‐MLO、LE‐CC、重组‐MLO和重组‐CC。通过考虑多模态(LE和重组)与多视角(MLO和CC)图像之间的相似性与差异性,我们所提出的设计有助于学习最优特征表示。
我们提出使用迁移学习来训练我们的双模态深度模型,以解决CEDM数据有限的问题。具体而言,我们采用基于 ImageNet构建的预训练Inception V3——一种先进的卷积神经网络(CNN)模型——进行初始参数估计,然后利用CEDM数据微调参数。通过这种方式,将在自然图像分类中获得的知识迁移到使用CEDM的乳腺癌诊断中。
我们开发了可视化技术,以帮助解释深度学习模型的结果。对深度学习(DL)的一个主要批评是其作为黑箱模型缺乏可解释性。这一直是阻碍其广泛临床应用的障碍。临床医生不愿意信任一个他们无法理解的模型。我们的可视化技术能够生成:(1)每个类别(良性或恶性)的图形表示,以显示类别间的差异;以及(2)影响图,以显示图像像素对每位患者诊断结果的贡献。后一种能力有助于量化肿瘤间和

肿瘤内恶性异质性,从而为指导精准治疗提供了有价值的工具。D2TL系统无需精确分割,仅需对肿瘤区域进行粗略定位。这可以由医学培训较少的普通用户完成。此外,尽管肿瘤大小差异显著,但仍可使用统一尺寸框对不同肿瘤进行定位。本质上,D2TL是一个无需分割、对肿瘤大小不敏感且抗定位误差的系统,能够最大限度地减少人为偏差并实现高度自动化。
本文其余部分结构如下:第2节回顾相关工作并指出其局限性;第3节 介绍基于CEDM的D2TL乳腺癌诊断系统的开发;第4节 展示使用真实数据的应用案例研究;以及第5节给出结论。
2. 相关工作
近年来,深度学习模型已用于医学图像分类,并显示出良好的效果。一个主要的研究方向是使用深度学习作为特征提取器,以从图像中提取深度特征。然后可以利用这些特征来构建分类器。例如,Suk 等。 (2014)使用深度玻尔兹曼机 (DBM) 从磁共振成像 (MRI) 和正电子发射断层扫描 (PET) 图像块中提取潜在的层次化特征表示,然后应用支持向量机 (SVM) 对阿尔茨海默病 (AD)、轻度认知障碍 (MCI) 和健康对照进行分类。针对相同的分类任务, Liu ’等。 (2014)设计了一种包含堆叠自编码器 (SAE) 的深度学习架构,用于学习MRI图像的特征表示。 Cheng 等。(2016)使用SAE在两个应用中区分良性和恶性病例:一是基于超声图像对乳腺病变进行分类;二是基于CT扫描对肺结节进行分类。
自2012年的ImageNet竞赛(Russakovsky等。, 2015)开始,卷积神经网络—一种深度学习模型—已成为包括医学影像分析在内的计算机视觉应用的主流。自 2014年以来,通过部署更深的网络结构,CNN分类器的性能得到了显著提升(Simonyan和Zisserman,2014; Szegedy等。,2015)。在深度卷积神经网络模型中,许多卷积核被堆叠为计算层,在训练过程中需要估计数百万参数。这类复杂模型需要大量训练样本,以避免参数估计错误。然而,由于成本和可获得性的限制,许多医学图像数据集难以满足这一需求。训练样本的缺乏一直是从零开始构建CNN模型的主要障碍。
为了克服样本量限制,迁移学习提供了一种有效的方法。迁移学习是一类机器学习方法,通过利用相关源领域的数据或知识,为目标领域构建模型(Weiss et al.,2016; Zou et al., 2015; Huang等,2012)。当目标领域数据有限时,从源领域迁移的知识有助于弥补数据短缺问题,并构建一个鲁棒模型。迁移学习可与深度学习相结合,形成一种深度迁移学习框架,该框架首先在大规模数据集(源领域)上预训练深度学习模型,然后利用目标领域的小规模数据集对模型参数进行微调。当医学图像作为目标领域时,一个合理的选择是使用包含数百万张自然图像、涵盖数千类别的 ImageNet数据集作为源领域。研究人员已研究了将 ImageNet分类器中的知识迁移到基于影像的医学诊断中。
例如,Zeng和Ji(2015)结合预训练VGG CNN模型( Simonyan和Zisserman,2014)以及三个卷积层和两个全连接层,用于小鼠大脑原位杂交(ISH)图像的多任务分类。Zhang等(2016)将类似的方法应用于ISH果蝇图像。
在乳腺癌诊断方面,深度学习已应用于全视野数字乳腺X线摄影图像。例如,Dhungel 等。(2015a,2015b)结合R‐CNN模型和随机森林分类器来检测和分类乳腺肿块。基于手动分割的兴趣区域,Arevalo 等。(2016)提出了一种具有四层卷积特征图的CNN分类器用于肿块病变分类。L evy和Jain(2016)利用预训练CNN模型并进行微调,表明从预训练CNN中获得的知识可有效迁移到乳腺肿块分类任务中。针对CEDM图像,Mateos 等。( 2016)提出了一种基于17个GLCM描述符的算法,其敏感性达到0.93,特异性达到0.79。Danala 等。(2018)提出了基于109个特征的多个MLP分类器,这些特征包括肿瘤体积、肿瘤区域熵、背景波动均值、小波特征及其他统计特征,其敏感性达到0.8077,特异性为0.7273。这两项研究均属于前述的传统机器学习框架下的基于图像的乳腺癌诊断方法,该框架需要进行分割、特征提取和分类器训练。这种传统框架的局限性包括对精确分割的需求、浅层特征的使用,以及容易受到误差传播和次优性影响的顺序流程。
据我们所知,目前尚无研究使用深度学习模型分析 CEDM图像以进行乳腺癌诊断。面临的挑战如下:(1) CEDM是一种相对较新的成像技术,因此样本量太小,远不足以满足从头训练深度学习模型的需求。虽然可以从不同机构收集患者图像以建立大型数据存储库,但由于缺乏跨机构的患者隐私保护协议,这一做法目前无法实现。这确实是许多其他医学应用普遍面临的问题,而不仅仅是 CEDM。总体而言,与ImageNet等自然图像相比,构建适用于医学应用的深度学习模型要困难得多,因为自然图像更容易获取,也更便于从不同来源共享。(2)迁移学习
是一种有前景的方法,可通过利用在相关领域(如 ImageNet)中使用大量数据预训练的深度架构的知识,从一个小数据集构建深度学习模型。然而,现有的深度迁移学习模型不能直接适用于我们的问题,因为它们没有考虑多模态和多视角CEDM图像的特殊特性。(3)对深度学习的一个主要批评是其作为黑箱模型缺乏可解释性。尽管深度学习在许多领域取得了巨大成功,但我们对深度学习网络中大量复杂连接的神经元如何工作的理解仍然不足。在医学领域,模型的可解释性因多种原因而显得尤为重要。首先,临床医生往往不愿意使用他们无法理解的模型;其次,一旦他们理解了模型,就能够利用自身的领域知识帮助进行模型验证并提出进一步改进的建议。近年来,许多研究人员致力于推动深度模型的解释能力(Yosinski et al., 2015; Erhan et al., 2009; Zeiler and Fergus, 2014; Simonyan et al., 2013)。这种能力对于我们正在开发的用于乳腺癌诊断的基于CEDM的深度学习模型而言极为重要。(4)深度学习模型已被用于基于FFDM图像的乳腺癌诊断,但尚未应用于CEDM。大多数现有研究依赖人工肿瘤分割作为第一步,并将深度学习用作特征提取器。我们希望避免分割步骤,通过向深度学习驱动的自动化诊断系统发展,减少人为参与。
3. 基于CEDM图像的D2TL诊断系统开发
我们提出的系统基于卷积神经网络。近年来已提出多种不同的卷积神经网络模型。选择合适的卷积神经网络模型对系统的开发至关重要。为了做出合理的选择,我们首先介绍六种前沿的卷积神经网络模型,然后在表1中比较它们的性能。
AlexNet(Krizhevsky 等, 2012)于2012年首次提出,包含八个神经网络层—前五层为具有较大(11 × 11)卷积核的卷积层,后三层为全连接(FC)层。VGG模型 (Simonyan和Zisserman,2014)(也称为ConvNet)由牛津大学视觉几何组于2014年提出,包含16或19层;即分别为“VGG-16”和“VGG‐19”。与AlexNet不同, VGG网络使用较小的卷积核,大小仅为 3 × 3;并通过堆叠较小的卷积核来替代大卷积核。原始Inception模型 (Szegedy 等,2015)(也称为GoogLeNet)使用多种尺寸的卷积核,并采用 1 × 1卷积核,通过增加网络深度以获得更好的表示,并降低特征图的维度以减少复杂度。ResNet将捷径连接引入深度学习,解决了网络加深时出现的退化问题(He等,2016)。InceptionV3 (Szegedy 等,2016)被提出以改进原始的Inception模型,并增加了整个网络的深度。
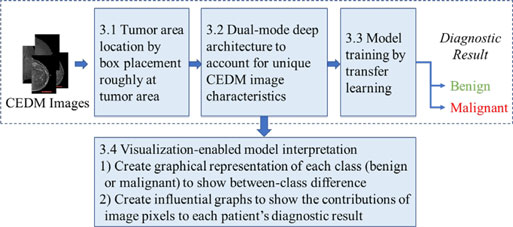
从表1可以看出,在所有卷积神经网络模型中, InceptionV3以相对较少的参数数量取得了最佳性能。因此,我们选择Inception V3作为基础模型来构建我们的系统。具体而言,我们提出的系统包含四个模块,如图1 所示。各模块的详细信息见第3.1节–3.4。
3.1. 肿瘤区域定位
如前所述,传统的基于机器学习的诊断系统需要将肿瘤边界的精确分割作为初始步骤。在D2TL中,既不需要手动分割,也不需要通过计算机算法进行分割。相反,用户只需在肿瘤区域周围大致放置一个框,我们称之为“定位”,以区别于精确分割。只要该框包含肿瘤的某一部分,其位置并不关键。对于不同大小的肿瘤,框的大小可以保持不变。通过这种方式,我们希望最小化人为干预并最大化自动化。
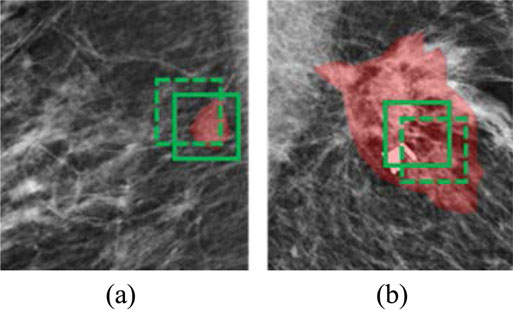
具体而言,在我们的实验中发现,对于包含不同大小肿瘤(范围从 35× 37到1175× 881像素²)的数据,采用尺寸为 256× 256像素²的统一尺寸框效果良好。此处,肿瘤大小a × b对应于完全包含该肿瘤的最小外接矩形。此外,我们的实验表明,框的位置对分类性能没有显著影响。例如,即使我们将每个肿瘤上的框沿随机选择的方向移动 20像素,分类准确率仍保持不变。图2 通过两个肿瘤/患者示例说明了这些实验结果。实验的详细信息进一步在第 4.1节 和第4.2节中给出。
尽管这些实验观察的普适性还有待更多数据验证,但我们初步得出以下结论:(1)D2TL 不需要对每个肿瘤进行精确分割。这大大减轻了临床医生的工作负担,降低了机构对严格医学培训的要求。
| 深度学习模型 | Top‐1 错误率 | 前5错误率 | 参数数量 |
|---|---|---|---|
| AlexNet(Krizhevsky等。,2012) | 37.5% | 17.0% | 6000万 |
| VGG‐16(Simonyan 和 Zisserman,2014) | 28.07% | 9.33% | 1.38亿 |
| Inception(Szegedy 等。2015) | – | 9.15% | 680万 |
| ResNet-50(He等。, 2016) | 20.74% | 5.25% | 2560万 |
| ResNet-152(He等。 ,2016) | 19.38% | 4.49% | 6020万 |
| InceptionV3(Szegedy等。 , 2016) | 18.77% | 4.2% | 2300万 |
在实践中采用CEDM,并有助于提高CEDM在广大患者群体中的可及性。(2)尽管不同患者的肿瘤大小差异显著, D2TL可以对所有肿瘤使用统一尺寸框。需要注意的是,统一尺寸框将包含小肿瘤的全部及其周围的正常组织(图 2(a)),而对于大肿瘤则仅包含其部分区域(图2(b))。在传统机器学习看来,使用这种统一尺寸框远不理想—它为小肿瘤引入了过多噪声(正常组织),而为大肿瘤提供的信号(肿瘤组织)不足;此外,在后续分类中无法利用大肿瘤的形状信息。然而,这些对传统机器学习不利的因素似乎并未影响D2TL。(3)D2TL的性能在一定程度上对框的位置偏移不敏感。这种对小分割误差的容忍性以及从噪声图像中提取预测特征的能力,可能与D2TL及其他基于卷积神经网络的深度学习模型中两类层的功能与协作有关。具体而言,“卷积层”可被视为局部小区域内像素的线性组合。该计算方式对原始输入进行平滑处理,并生成高层抽象,其中每个像素代表原始输入的一个小区域。显然,这种计算对分割的小幅偏移/误差具有容忍性,因为局部特征不会发生显著变化。“池化层”旨在逐步降低表示的空间尺寸,以减少参数量和计算量。从这个意义上讲,池化层也可以被视为对原始输入大范围的一种抽象层次。在深度学习框架设计中,通常会在连续卷积层之间周期性地插入池化层。这两种层共同将一定范围的输入像素抽象为单个值,这意味着如果变化仅发生在很小的范围内(例如微小的偏移),输出不会发生显著变化。随着深度学习模型层数加深,这种容错性会逐层放大,在最深层的末端,这些值可能代表了原始输入的大范围区域,从而对分割误差具有鲁棒性。
3.2. 双模式深度架构设计
在本节中,我们提出了一种用于D2TL的DL架构的新颖设计,以应对CEDM图像的特殊特性。如前所述,在患者’的CEDM检查中,可疑乳房总共会产生四张图像。 图3 展示了四张CEDM图像的示例。左侧的重组图像突出了对比增强效果,从而呈现出更亮的潜在肿瘤团块。然而,由于抑制了正常乳腺密度,重组图像未能捕捉到纹理信息。相比之下,右侧的LE图像捕获了血管、纤维腺体和皮肤的丰富纹理细节;但肿瘤团块可能隐藏在致密乳腺组织中。显然,同一模式下生成的图像(即,图3中同一列上的两张图像)在特征表示上比不同模式下的图像(即,同一行上的两张图像)具有更高的相似性。


同一模式下的CC和MLO图像方向不同,但在感知特征上差异不大。
如果不考虑前述CEDM图像的特殊特征,可能会采用两种可能的深度学习架构:简单池化,即将来自两个视图和两种模态的四张图像输入到单个深度学习模型中;以及独立建模,即将四张图像分别输入到四个独立的深度学习模型中。这两种架构都不理想。前者假设四张图像具有相同的特征表示,这是一个过于简化的假设,从图3中可以明显看出。后者则未能利用图像之间的相似性。此外,训练四个独立模型计算量大,且相关的过参数化容易导致过拟合,使训练后的模型在未见数据上的泛化能力较差。
我们提出了一种双模式深度学习模型,以利用来自两个视图的图像在特征表示上的模态内相似性。所提出的架构分别包含两个独立的InceptionV3模型,用于重组图像和低能量图像。我们剪除了每个InceptionV3模型的最顶层若干层,然后添加自定义的卷积层,以构建一个二分类(恶性与良性)分类器。
具体而言,每个InceptionV3模型的输入是同一模式下的MLO和CC图像,输出是一个4096维特征表示向量。该向量随后被送入一个包含dropout层和全连接层的抽象层,以生成512维输出。接着,来自特定模式的抽象层的输出被合并,并送入另一个dropout层和全连接层,最后连接到softmax函数,该函数使用0.5作为阈值将样本分类为两类。图4展示了该架构设计的细节。通过将同一
通过单个InceptionV3模型处理单一模式,以及通过独立模型处理不同模式下的图像,所提出的设计尊重了 CEDM生成的四张图像在特征表示方面的独特相似性和差异性。
3.3. 通过迁移学习训练双模式深度学习模型
显然,要使深度学习模型获得良好性能,需要大量样本进行训练。在许多医学应用中,尤其是涉及CEDM等新技术的应用,可用的样本通常非常有限。虽然有人可能会认为可以等到积累足够样本后再进行深度学习模型的训练,但这将耗费大量时间,并阻碍新技术的评估及其在更广泛患者群体中的应用。迁移学习是一类机器学习方法,通过结合来自不同但相关领域所获取的知识与目标领域的特定数据,从而构建出比仅使用目标领域数据性能更好的模型。’的目标领域’数据。将CEDM图像视为目标领域,一个相关的领域是自然图像。已有深度学习模型在ImageNet数据集上进行了训练,该数据集包含数百万张来自数千个类别的自然图像(Simonyan和Zisserman,2014; Szegedy等。,2015)。为了实现从自然图像分类到基于 CEDM的乳腺癌分类的迁移学习,我们提出使用在 ImageNet上预训练的InceptionV3模型,来初始化第 3.2节中提出的双模式深度学习模型的参数估计。然后,我们利用我们的CEDM数据对参数进行微调。图5 展示了使用迁移学习的模型训练过程。
 ; 连接层 (c);dropout层 (d);完整 y连接层(fc)。)
; 连接层 (c);dropout层 (d);完整 y连接层(fc)。)
3.4. 可视化支持的解释
D2TL 是一种基于影像的诊断系统,我们认为该系统中两种解释方式非常重要。其一是理解恶性与良性类别在输入图像空间中的差异。如果我们能为每个类别生成图形表示,通过视觉比较这两幅图,将有助于我们发现哪些图像特征能够区分两类,以及基于图像数据这两类的分离程度如何。
为了生成每个类别的图形表示,Ic; c ∈ {malignant, benign},我们可以求解以下优化问题:
$$
\arg\min_{I_c} \left[ (y_c - f_c(I_c))^2 + \lambda |I_c|_2^2 \right] \tag{1}
$$
这里,$y_c = 0$或1对应于良性或恶性类别。$f_c(I_c)$是类别c的得分,该得分通过将图$I_c$输入训练好的深度学习模型生成。在D2TL中,$f_c(I_c)$是softmax函数的输出,取值范围为0到1: $|\cdot|_2$ 是一个$l_2$‐范数。$\lambda$是正则化参数。本质上,(1)旨在寻找一个经过$l_2$‐正则化的类别c的图,使其最小化真实标签与预测得分之间的损失。这一思想类似于Simonyan等。( 2013)提出的类别表示。通过反向传播方法(Rumelhart等, 1988)求解(1)以找到$I_c$。需要注意的是,CEDM为每位患者生成四张图像,这意味着$I_c$实际上是类别c的一组四张图像。
我们希望提供的第二种理解是,可视化每个图像像素对患者诊断结果(良性或恶性)的影响或贡献。设I为来自一位患者的四幅CEDM图像的集合。进一步用向量X表示I中的所有像素:$f_c(X)$是一个D2TL中X的复杂非线性函数,但可以通过泰勒级数近似为线性函数;即,
$$
f_c(X) \approx w_c^T X + b_c \tag{2}
$$
其中,$w_c = \frac{\partial f_c}{\partial X}\bigg| {X_0}$ 可通过反向传播获得。$w_c$中的第j个元素的幅值;$w {cj}$反映了像素$X_j$对诊断结果的影响/贡献。我们可以绘制$w_c$中各元素的绝对值,以可视化所有图像像素的影响。
4. 使用CEDM进行乳腺癌分类的应用
在本研究中,我们从合作机构亚利桑那梅奥诊所( MCA)获得了96例患者的CEDM图像。MCA是首个临床使用Hologic CEDM技术的非beta测试、经美国食品药品监督管理局(FDA)批准的机构。CEDM成像采集协议已在先前的出版物中详细描述(Lewin et al., 2003)。低能量和高能量(HE)图像分别在26–32kVp和45–49 kVp下采集。每个视图(MLO或CC)下的重组图像是通过对HE和LE图像进行减影获得的。这96例患者均具有可疑的乳腺发现,并以活检证实的病理结果作为金标准。活检确认其中48例为恶性病例,其余48例为良性病变。在所有实验中,我们随机选择60例、16例和20例分别用于训练、验证和盲测。由于训练和验证的样本量小,我们应用了数据增强技术。为了确定增强图像的数量,我们参考了

一种用于乳腺癌检测的双模式深度迁移学习(D2TL)系统,基于对比增强数字乳腺X线摄影(续)
4. 使用CEDM进行乳腺癌分类的应用(续)
ImageNet,其共有14,197,122 张图像,属于21,841 个类别;即平均每类约650张图像。在我们的训练集中,共有 240 张图像—每例4张图像(LE‐MLO、LE‐CC、重组‐ MLO和重组‐CC),共60例,分为两类—。为了构建一个类似每类大小的增强训练集,我们将原始训练集中的每张图像增强为五种替代图像。这样每类得到600张图像。增强参数的选择遵循现有卷积神经网络研究中的标准流程 (Jaitly 和 Hinton,2013; Krizhevsky and Hinton,2009),并在表2中进行了总结。
本节中每个实验包含 10 次运行,每次运行进行 100 个周期。在每个周期中,使用数据增强的训练集和验证集,并对患者顺序随机化。选择在验证集上达到最高准确率的模型,用于预测测试集中的病例。将每个测试病例的预测类别与真实类别进行比较,报告总体准确率、敏感性(将真实恶性病例预测为恶性的准确率)和特异性(将真实良性病例预测为良性的准确率)。所有实验均在配备 NVIDIA GeForce GTX 1080 GPU(8GB 显存)和 Intel Core i7 5930K CPU 的计算机上进行。
4.1 肿瘤区域定位中框大小的影响
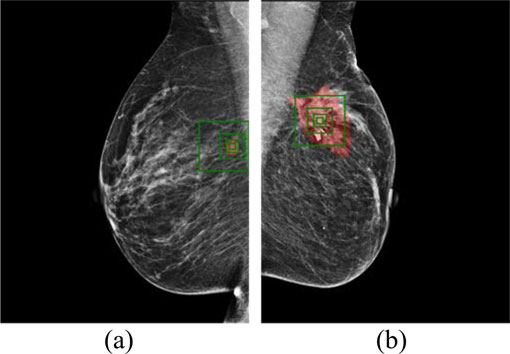
D2TL不需要肿瘤分割,而只需在肿瘤区域周围粗略地放置一个框,我们称之为定位。在本实验中,我们研究框大小对分类性能的影响。具体而言,我们选择了四种不同的框大小, 64× 64、 128× 128、 256× 256和512× 512 像素²。图6显示了来自两位不同患者的肿瘤。每个肿瘤上叠加了四个不同大小的绿色框。每个框的中心由学生作者从重组图像中选择,该学生作者代表了一位接受医学培训较少的普通用户。由本文医学合著者手动分割的肿瘤用红色标出,仅用于帮助读者识别每个肿瘤的位置和形状,但并未在D2TL用于分类中使用。我们的数据集包含大小从 35× 37到1175× 881像素²不等的小肿瘤。对所有肿瘤使用统一尺寸框将导致小肿瘤分析中包含大量正常组织(噪声)(图6(a)),而仅包含部分的分析中包含的肿瘤以及大肿瘤的重要形状特征被排除(图 6(b))。这些情况对传统机器学习来说很困难,但我们想知道它们是否也会影响D2TL。
 小肿瘤(157× 206)和 (b) 大肿瘤(675× 728)。)
小肿瘤(157× 206)和 (b) 大肿瘤(675× 728)。)
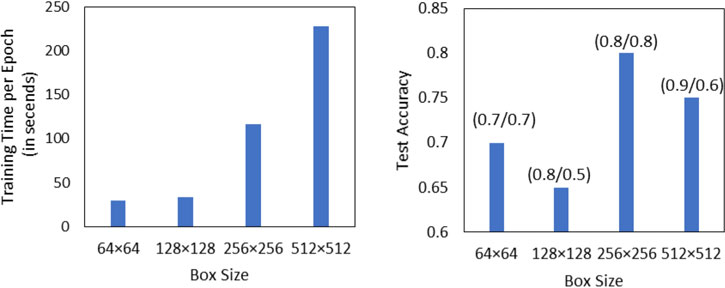
图7 显示了每种框大小的训练时间和测试准确率。正如预期的那样,随着框大小的增加,训练时间也随之增加。在四种不同的框大小中,256× 256实现了最高的总体准确率(80%),且敏感性(80%)和特异性(80%)较为均衡。更大的框 512× 512具有更高的敏感性,但特异性显著降低。较大的框在分析小肿瘤时更有可能包含正常组织(噪声),这似乎对特异性造成较大影响。较小的框 128× 128和 64× 64在任何指标上的表现均不如 256× 256。这可能是因为所包含的肿瘤团块信息不足。由于 256× 256框在四种大小中产生的准确率最高,因此我们将在所有后续分析中采用该框大小。
4.2. 框位置偏移的影响
我们希望评估分类性能对于前一节中使用的每个框的位置的鲁棒性。请回顾一下,前一节中的每个框均由学生作者放置,这种放置方式已经相当“粗糙”。在此,我们希望进一步增加框位置的不确定性,以评估我们方法的鲁棒性。具体而言,我们移动前一节中所用每个框的中心前一节中,沿随机选择的方向偏移20像素。此外,为了保持同一视图下两张图像之间的耦合关系,我们使其各自的偏移方向保持一致。图8显示了偏移的框与第4.1节中原原始框位置相比的测试准确率。总体准确率保持不变(80%),而特异性略有提高(90%),敏感性有所下降(70%)。该结果表明D2TL对肿瘤定位中更大的不确定性具有鲁棒性,但可能需要更多数据来确认敏感性和特异性的变化是否显著。此外,我们在10像素和40像素偏移条件下进行了实验,并在每种偏移量下重复实验10次。10像素和20像素偏移量下的测试准确率之间无统计学显著差异(p = 0.487)。40像素偏移量下的测试准确率显著低于20像素偏移量(p< 0.001)。这种性能下降是预料之中的,因为 40像素的偏移可能导致一些框完全位于肿瘤区域之外(请注意,我们数据集中最小肿瘤尺寸仅为35x37)。

4.3. 与简单池化的比较
D2TL 采用一种双模式深度架构设计,利用了特征的模态内相似性来自两个视图的图像的表示。一种直观的替代方法是简单池化,即在四张图像上训练单一深度架构。D2TL与简单池化的区别在于,前者探究由两种模态(低能量和重组)生成的图像的不同特征表示,而后者假设所有图像具有相同的表示。我们希望评估所提出的双模态设计的优势。图 9展示了D2TL与简单池化相比的性能。我们保持两个模型的其他所有设置相同,例如相同的初始化、丢弃率和学习率策略,以便我们可以专注于双模态与单一架构设计之间的比较。如预期所示,双模态设计在训练时所需时间是简单池化的两倍,但在总体准确率和敏感性方面优于简单池化,如图9所示。该结果证明了D2TL尊重CDEM图像独特特征表示的必要性。
4.4. 迁移学习中的调优策略
在训练双模式深度学习模型时采用了迁移学习,其中我们使用在ImageNet上预训练的Inception V3来初始化参数估计,然后利用我们的CEDM数据微调参数。在微调过程中,可以选择调优预训练模型中的所有参数,称为全调优策略,或者仅调优预训练卷积神经网络中若干层的参数,称为半调优策略。D2TL采用了全调优策略,但我们希望了解半调优策略是否也足够有效。半调优策略的潜在优势在于计算效率,因为它只需要调优少数几层的参数。另一个优势可能是降低过拟合的风险,因为我们只有有限的 CEDM数据。具体而言,对于半调优策略,我们选择仅微调深度学习模型最后三个全连接层的参数,因为这些层最接近分类器,对其调优预计比调优远离分类器的层更能影响分类性能。与半调优策略相比,全调优策略需要调优大约五倍多的参数。为了公平比较,我们保持
两种策略的其他所有条件都相同,例如相同的初始化、丢弃率和学习率策略。图10显示了结果。半调优策略的准确率要低得多,并且将所有真实的良性病例分类为恶性(特异性为0%)。这表明,尽管CEDM数据有限,但在迁移学习中,通过调整所有模型参数,充分利用这些数据来偏置预训练的深度学习模型,对于保证良好的性能是必要的。
此外,为了证明迁移学习的有效性,我们将预训练的深度学习模型参数替换为随机初始化,并在全调优策略下将该模型与D2TL进行比较。前者在两个方面表现不如 D2TL:首先,模型训练收敛所需的时间要长得多。在总共200个训练轮次中,采用随机初始化的模型约在第130 个周期才达到90%的训练准确率,而D2TL约在第30个周期即达到相同的准确率。其次,采用随机初始化的模型存在明显的过拟合现象:最后10个周期的平均训练准确率为 96.62%,而验证准确率却下降至50%。相比之下, D2TL在最后10个周期的平均训练准确率和验证准确率分别为99.25%和74.76%。这些结果表明,利用预训练 Inception V3模型参数的迁移学习具有显著优势。
4.5. 可视化支持的解释
使用第3.4节中提出的方法(1),我们可以生成良性类别和恶性类别的图形表示,如图11(a)和(b)所示。其中(a)和 (b)中的每个子图均为 256× 256;即与放置在CEDM上用于肿瘤区域定位的框大小相同。一个明显的观察结果是,恶性类别的图形表示比良性类别的模糊得多。这表明 D2TL能够区分这两类。此外,恶性类别图形表示更模糊的原因可能是恶性肿瘤在图像表型方面更具异质性。如果将恶性类别的图形表示视为某种意义上的“平均值”对所有恶性肿瘤由于异质性导致平均值无焦点,从而产生模糊效果。
接下来,重点关注良性类别的图形表示。我们可以观察到,在每幅重组图像的中心周围存在一些粗糙的椭圆形结构(用红色虚线圆圈标出),而这些在低能量图像中几乎看不到。这与重组图像和低能量图像的特性一致:重组图像抑制了组织纹理,使肿瘤团块更加明显,而低能量图像则展示了丰富的组织纹理细节,但代价是难以清晰显示肿瘤团块。
此外,使用第3.4节中提出的方法(2),我们可以量化每个图像像素对患者诊断结果(良性或恶性)的影响/贡献。图12(a) 显示了一位良性患者的CEDM图像。每个图像像素对诊断结果的影响以颜色图的形式显示在(b)中,其中更亮的蓝色表示更高的影响。可以看出,高影响力像素集中在肿瘤团块上,特别是重组‐MLO和LE‐CC子图像上。图12 显示了一位恶性患者的CEDM图像及其影响图。可以得到与图13 类似的观察结果,并且进一步发现 LE‐MLO图像也包含一些高影响力像素。通过观察不同患者的患者特异性影响图,我们可以获得一些有趣的发现:在图像上高影响力像素的位置存在患者间的差异。在单个患者/肿瘤内部,不同位置像素的影响表现出空间异质性。如果像素影响反映了恶性程度,则如图12 和图13所示的影响图可用于量化瘤内恶性分布。这将对精准治疗具有重要意义,不仅可指导个体患者层面(肿瘤间)的治疗,还可指导患者肿瘤内部每个位置层面(肿瘤内)的治疗。
最后,我们承认本节中的所有观察结果均为初步结论。我们所采用的用于解释D2TL的可视化方法存在明显局限性,包括在生成重构图时所使用的公式(1)优化问题缺乏全局最优性,以及缺乏评估这些图的严格标准。事实上,如何解释深度学习模型已被认为是一个重要但具有挑战性的问题,迄今为止取得的成果有限。另一方面,我们希望利用本节中的结果来展示一些初步尝试,以提供对深度学习结果的解释,从而进一步促进临床医生对深度学习的接受和采用。

4.6. 与传统机器学习的比较
我们将D2TL与在基于影像的诊断系统中使用的传统机器学习框架进行比较。后者需要三个步骤:肿瘤分割、特征提取和分类。具体而言,每位肿瘤均由一名经董事会认证的乳腺放射科医生在重组图像上手动绘制肿瘤轮廓来进行分割。然后,我们使用三种著名的纹理分析算法——灰度共生矩阵、局部二值模式和Gabor filters—用于从分割的肿瘤中提取纹理特征。灰度共生矩阵和局部二值模式是常用的基于强度的纹理分析算法。它们提取的纹理特征可表征小邻域内像素的空间关系。Gabor是一种基于频率的算法,使用一组Gabor滤波器在不同的空间频率分辨率下提取特征。这三种纹理分析算法均已实现在现有的Python包scikit-image和mahotas中,在本实验中采用默认设置进行使用。此外,我们计算了分割后肿瘤轮廓的四个形状特征。这些形状特征在乳腺癌分类中被广泛使用:紧凑度、最小与最大径向长度的比值、熵以及弯曲能量(Page et al., 2003; Liang et al., 2012)。利用所有纹理和形状特征,我们采用三种先进的分类算法构建分类器:GLM‐LASSO、支持向量机和随机森林。我们使用相同的训练、验证和测试数据划分
对于这些分类算法而言,D2TL的结果如图14所示。这三种算法的总体准确率均低于D2TL。这些算法的特异性非常低(60%),意味着将良性肿瘤误判为恶性的风险较高,从而导致不必要的活检和/或过度诊断。这种较差的性能可能是由于从分割到分类过程中误差的传播、仅使用纹理和形状进行浅层特征表示的不足,或肿瘤分割、特征提取和特征分类三个独立步骤中框架的次优性所致。D2TL克服了所有这些局限性,从而实现了更优的性能。
最后,我们讨论了研究结果对当前乳腺癌临床实践的意义。乳腺影像报告和数据系统(BI‐RADSV R)是由美国放射学会建立的标准化工具,用于指导放射科医生对乳腺影像发现进行分类。被分为BI‐RADSV R 4类和5类的病例建议进行活检或外科会诊。目前据报道,这些病例中仅25%在一年内获得恶性肿瘤的组织学诊断(Rosenberg et al., 2006)。这一比例过低。我们的研究表明,通过采用所提出的D2TL系统,有望将这一比例提高到80%,协助放射科医生的决策,将对当前的患者护理连续性产生积极影响。
5. 结论
在本文中,我们提出了一种基于CEDM图像的深度学习驱动的乳腺癌诊断系统,称为D2TL。该D2TL系统包含四个关键组成部分:肿瘤区域定位、双模态深度架构、基于迁移学习的模型训练以及可视化支持的解释。我们将 D2TL应用于MCA收集的CEDM数据,以分类良性与恶性肿瘤。D2TL的表现优于其他竞争性深度学习模型(如简单池化和半调优迁移学习)以及传统机器学习方法。本文的贡献主要在于应用层面,而非从头设计新的深度学习架构或研究其理论性质。由于当前样本量小,后者目前尚不可行,但随着更多CEDM数据的积累,这将成为一个有前景的未来研究方向。另一个未来方向是除图像外,进一步结合患者风险因素(如年龄和基因型)以提高分类准确率。


















 1462
1462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









