




写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
一. 什么是 LangChain?
LangChain 是一个基于语言模型的框架,用于构建聊天机器人、生成式问答(GQA)、摘要等功能。它的核心思想是将不同的组件“链”在一起,以创建更高级的语言模型应用。LangChain 的起源可以追溯到 2022 年 10 月,由创造者 Harrison Chase 在那时提交了第一个版本。
二. LangChain 包含哪些部分?
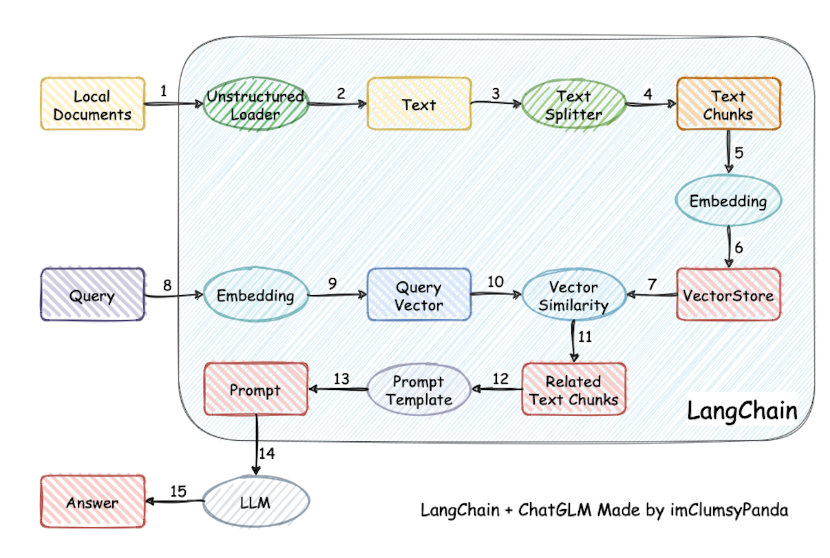
为了能够帮助大家理解,附上LangChain的流程图,如上所示。从上图可知,主要包括以下部分:
- 模型(Models): 这指的是各种不同的语言模型以及它们的集成版本,例如GPT-4等大型语言模型。LangChain对这些来自不同公司的高级模型进行了概括,并封装了通用的API接口。利用这些API,用户能够方便地调用和控制各个公司的大模型。
- 提示(Prompts): 涉及到提示的管理、优化和序列化过程。在大语言模型的应用中,提示词发挥着至关重要的作用,无论是构建聊天机器人还是进行AI绘画,有效的提示词都是不可或缺的元素。
- 记忆(Memory): 它负责存储与
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2331
2331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











