




- 论文地址:https://arxiv.org/pdf/2409.02060
- 论文标题:OLMoE: Open Mixture-of-Experts Language Models
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
尽管大语言模型 (LM) 在各种任务上取得了重大进展,但在训练和推理方面,性能和成本之间仍然需要权衡。
对于许多学者和开发人员来说,高性能的 LM 是无法访问的,因为它们的构建和部署成本过高。改善成本 - 性能的一种方法是使用稀疏激活混合专家 (MoE)。MoE 在每一层都有几个专家,每次只激活其中的一个子集(参见图 2)。这使得 MoE 比具有相似参数量的密集模型更有效,因为密集模型为每个输入激活所有参数。
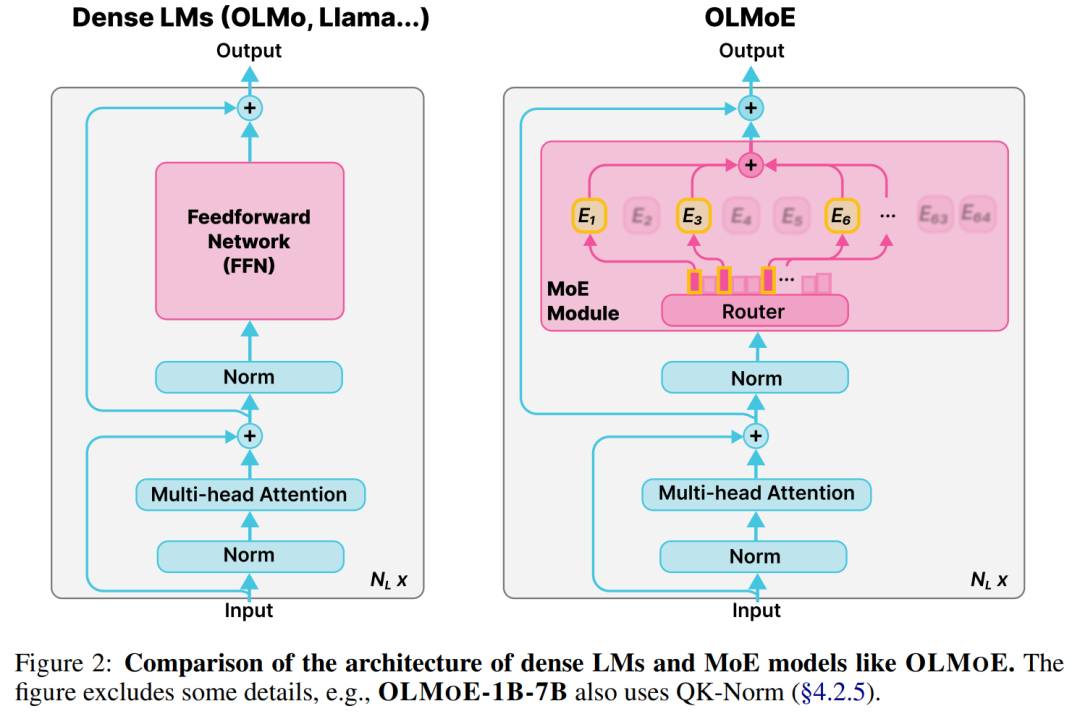
出于这个原因,行业前沿模型包括 Gemini-1.5、 GPT-4 等在内的模型都使用了 MoE。
然而,大多数 MoE 模型都是闭源的,虽然有些模型公开发布了模型权重,但有关训练数据、代码等的信息却很有限,甚至有些研究没有提供这些信息。由于缺乏开放资源和对研究细节的深入探索,在 MoE 领域无法构建具有成本效益的开源模型,从而接近闭源前沿模型的能力。
为了解决这些问题,来自艾伦人工智能研究院、 Contextual AI 等机构的研究者引入了 OLMoE ,这是一个完全开源的混合专家语言模型,在类似大小的模型中具有 SOTA 性能。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











