




 本文详细介绍了Linux下的进程管理,包括进程与线程的基础知识,如PCB、thread_info和task_struct结构,以及内核栈的作用。讨论了进程的多种状态和生命周期,特别提到了TASK_KILLABLE状态。此外,文章深入探讨了内核线程、抢占机制、调度策略和优先级,以及如何修改进程优先级。内容涵盖实时进程与普通进程的区别,以及如何查看系统中的实时和普通进程。
本文详细介绍了Linux下的进程管理,包括进程与线程的基础知识,如PCB、thread_info和task_struct结构,以及内核栈的作用。讨论了进程的多种状态和生命周期,特别提到了TASK_KILLABLE状态。此外,文章深入探讨了内核线程、抢占机制、调度策略和优先级,以及如何修改进程优先级。内容涵盖实时进程与普通进程的区别,以及如何查看系统中的实时和普通进程。
引用
一. 进程基础知识
1.1进程
是资源的封装,是处于执行期的程序以及它所管理的资源(如 打开的文件,挂起的信号,进程状态,地址空间等)的总称。
用 PCB(Processing Control Block) 来描述,在linux中,用 struct task_struct 结构体来描述。
pid的数量是有限的,为 32768 (cat /proc/sys/kernel/pid_max)
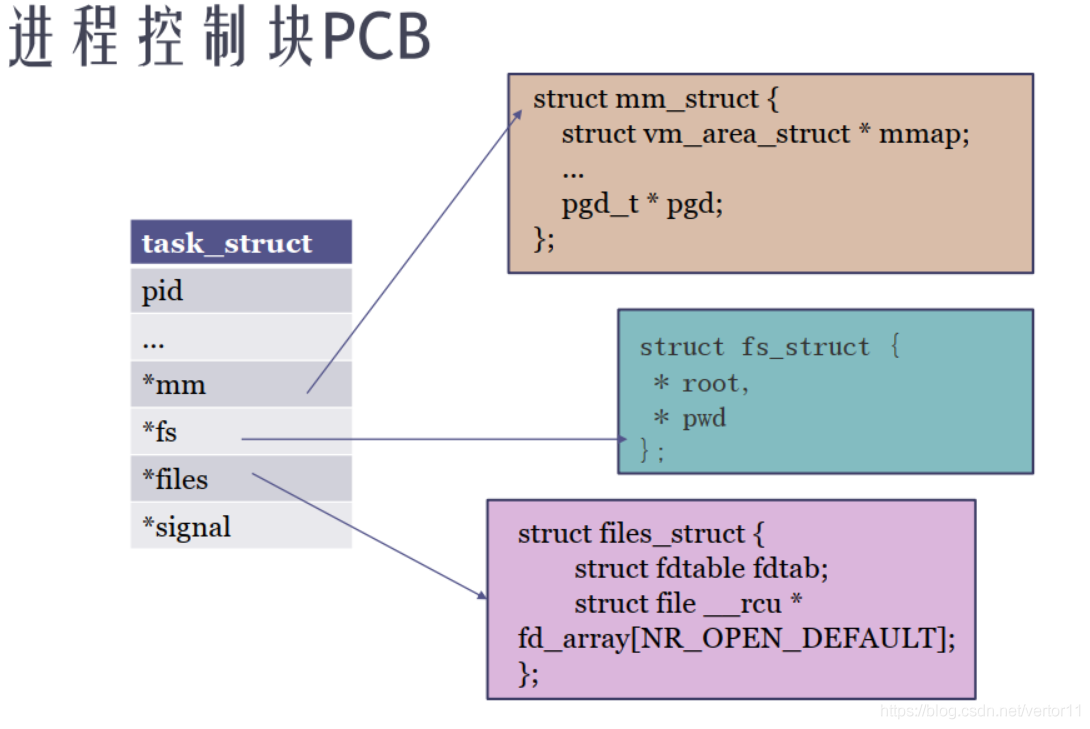
1.2 线程
是调度单位。用struct thread_info(e.g. arm64)来描述 (线程描述符),该结构和进程的内核栈stack存放在同一个单独为进程分配的内存区域。(由于这个内存区域同时保存了thread_info和stack,所以,使用了union 来定义。)
为什么需要thread_info?
内核需要存储每个进程的PCB信息, linux内核是支持不同体系的的, 但是不同的体系结构可能进程需要存储的信息不尽相同, 这就需要我们实现一种通用的方式, 我们将体系结构相关的部分和无关的部门进行分离。
用一种通用的方式来描述进程, 这就是struct task_struct, 而thread_info就保存了特定体系结构的汇编代码段需要访问的那部分进程的数据。
进程最常用的是进程描述符结构task_struct,而不是thread_info结构的地址。为了获取当前CPU上运行进程的task_struct 结构,内核提供了current 宏。
union thread_union {
//x86: CONFIG_ARCH_TASK_STRUCT_ON_STACK is not set.
#ifndef CONFIG_ARCH_TASK_STRUCT_ON_STACK
struct task_struct task;
#endif
//x86,arm64: CONFIG_THREAD_INFO_IN_TASK=y
#ifndef CONFIG_THREAD_INFO_IN_TASK
struct thread_info thread_info;
#endif
//x86: 8k, x86_64: 16k
//arm: 8k, arm64: 16k
//必须是8192的整数倍。
unsigned long stack[THREAD_SIZE/sizeof(long)];
};1.3 进程内核栈
为什么需要内核栈?
因为进程在内核态运行时,需要保持自己的栈信息。该栈不同于用户态的进程所用的栈。
用户态进程所用的栈是在进程线性地址空间中。
进程内核栈除了需要保存内核空间过程调用外,还需要保存用户空间栈的数据和返回地址,以便 在返回用户空间继续执行。
进程通过syscall陷入内核时进行栈切换。
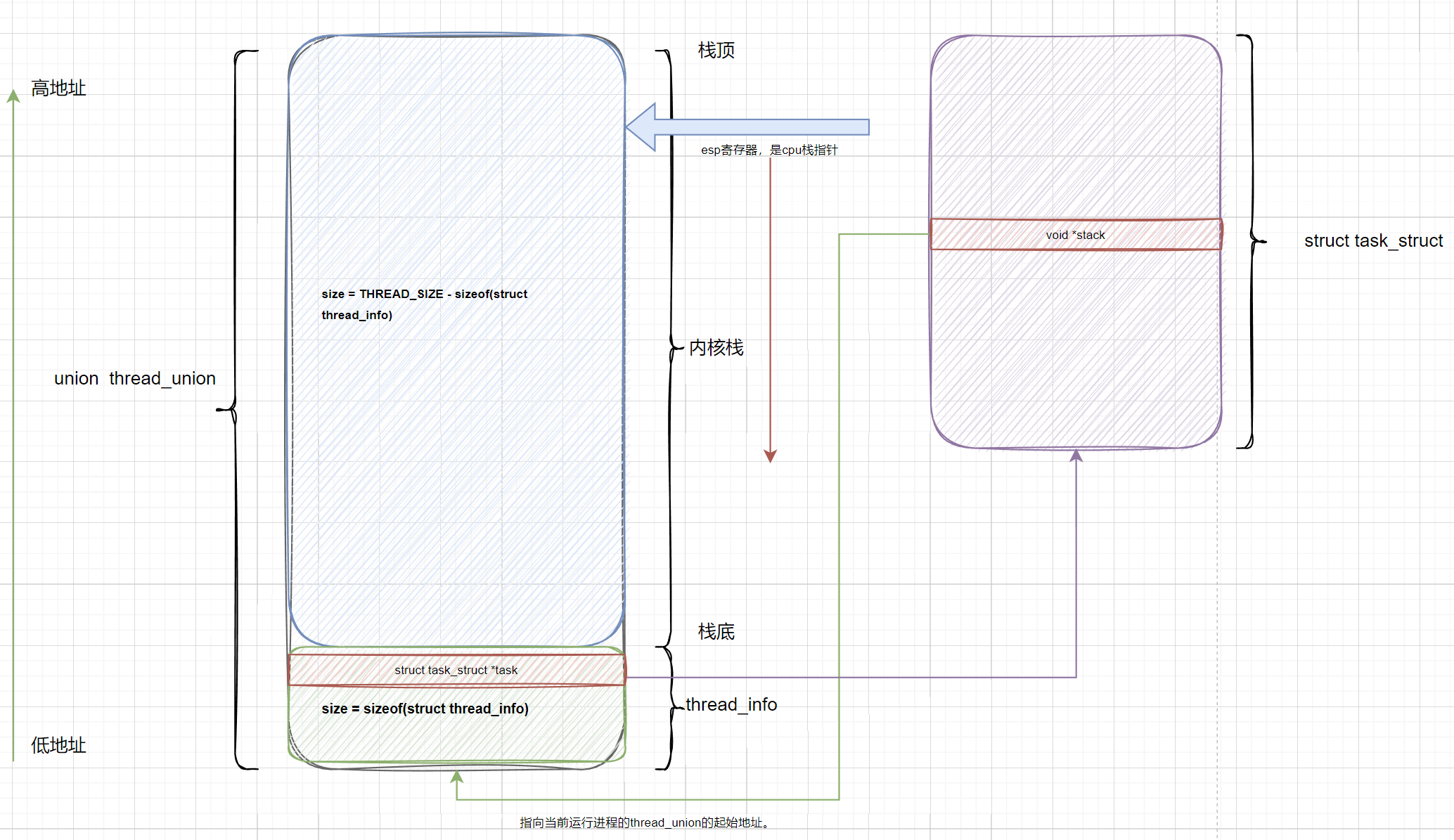
1.4 内核栈stack, struct thread_info, struct task_struct的关系:
经典关系 (CONFIG_THREAD_INFO_IN_TASK=n)
将thread_info存放在内核栈stack中。
在thread_info中保存task_struct指针。
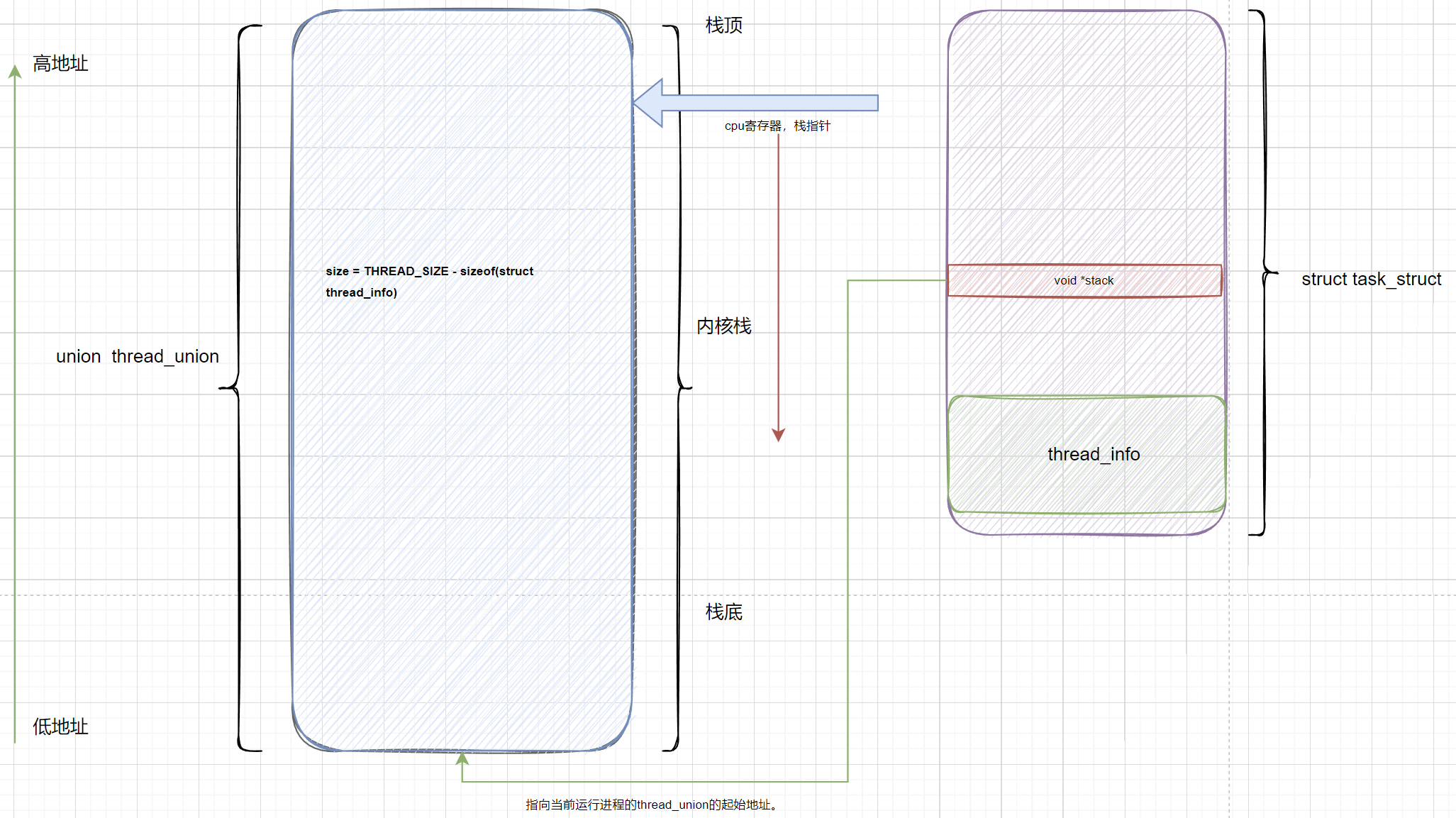
新版关系(CONFIG_THREAD_INFO_IN_TASK=y)
将thread_info放到task_struct中。
如何通过current宏找到当前的task_struct?
传统做法
通过寄存器(x86的esp寄存器, arm的sp栈栈顶寄存器)找到当前进程的内核栈顶,然后,找到thread_info,然后thread_info中保存了task_struct的指针,即就可以拿到当前进程的PCB了。
新做法(更高效)
x86
使用了current_task这个每CPU变量,来存储当前正在使用的cpu的进程描述符struct task_struct。x86上通用寄存器有限,无法像ARM中那样单独拿出寄存器来存储进程描述符task_sturct结构的地址。由于采用了每cpu变量current_task来保存当前运行进程的task_struct,所以在进程切换时,就需要更新该变量。在arch/x86/kernel/process_64.c文件中的__switch_to函数中有如下代码来更新此全局变量:
arm64:
会通过保存到寄存器(sp_el0)中,直接使用。
1.2 进程的各种状态和生命周期
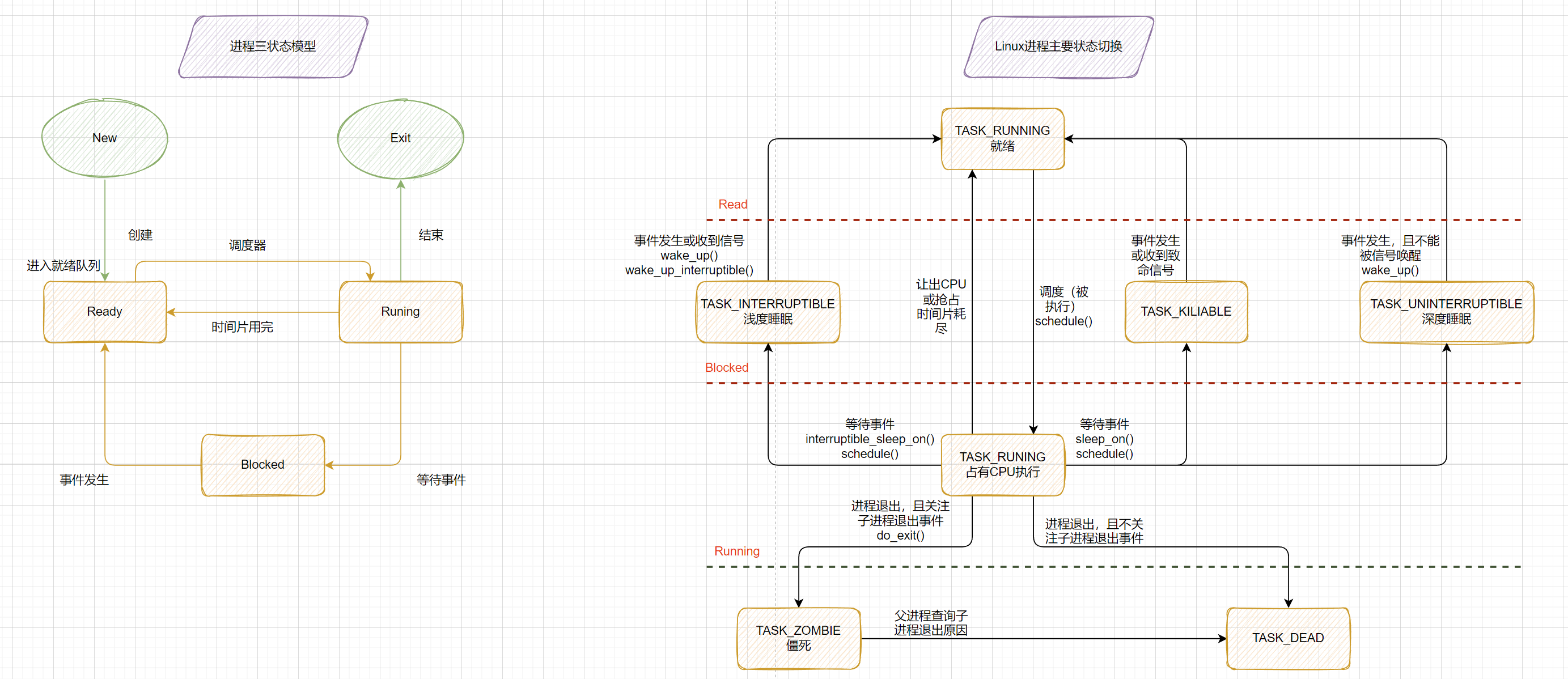
上图中左侧为操作系统中通俗的进程三状态模型,右侧为Linux对应的进程状态切换。每一个标志描述了进程的当前状态,这些状态都是互斥的;
Linux中的 就绪态 和 运行态 对应的都是TASK_RUNNING 标志位,就绪态 表示进程正处在队列中,尚未被调度;运行态 则表示进程正在CPU上运行;
5个互斥状态 state域能够取5个互为排斥的值(通俗一点就是这五个值任意两个不能一起使用,只能单独使用)。系统中的每个进程都必然处于以上所列进程状态中的一种。 | |
状态 | 描述 |
TASK_RUNNING | 表示进程要么正在执行,要么正要准备执行(已经就绪),正在等待cpu时间片的调度 |
TASK_INTERRUPTIBLE | 进程因为等待一些条件而被挂起(阻塞)而所处的状态。这些条件主要包括:硬中断、资源、一些信号……,一旦等待的条件成立,进程就会从该状态(阻塞)迅速转化成为就绪状态TASK_RUNNING |
TASK_UNINTERRUPTIBLE | 意义与TASK_INTERRUPTIBLE类似,除了不能通过接受一个信号来唤醒以外,对于处于TASK_UNINTERRUPIBLE状态的进程,哪怕我们传递一个信号或者有一个外部中断都不能唤醒他们。只有它所等待的资源可用的时候,他才会被唤醒。这个标志很少用,但是并不代表没有任何用处,其实他的作用非常大,特别是对于驱动刺探相关的硬件过程很重要,这个刺探过程不能被一些其他的东西给中断,否则就会让进城进入不可预测的状态 |
TASK_STOPPED | 进程被停止执行,当进程接收到SIGSTOP、SIGTTIN、SIGTSTP或者SIGTTOU信号之后就会进入该状态 |
TASK_TRACED | 表示进程被debugger等进程监视,进程执行被调试程序所停止,当一个进程被另外的进程所监视,每一个信号都会让进城进入该状态 |
2个终止状态 两个附加的进程状态既可以被添加到state域中,又可以被添加到exit_state域中。只有当进程终止的时候,才会达到这两种状态. | |
状态 | 描述 |
EXIT_ZOMBIE | 进程的执行被终止,但是其父进程还没有使用wait()等系统调用来获知它的终止信息,此时进程成为僵尸进程 |
EXIT_DEAD | 进程的最终状态 |
TASK_KILLABLE Linux 中的新进程状态(TASK_UNINTERRUPTIBLE + TASK_WAKEKILL = TASK_KILLABLE) | |
状态 | 描述 |
TASK_KILLABLE | 当进程处于这种可以终止的新睡眠状态中,它的运行原理类似于 TASK_UNINTERRUPTIBLE,只不过可以响应致命信号 |
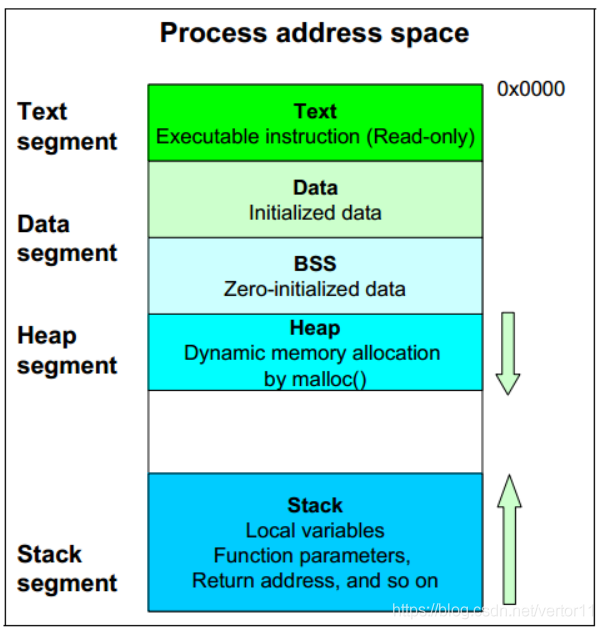
1.3 进程地址空间
可用pmap查看
1.4 内核线程
用ps查看线程时,名字为 [..] 这样的线程,都是内核线程。例如:中断线程化使用的irq内核线程;软中断使用的内核线程ksoftirqd;以及work使用的kworker内核线程。
内核线程没有地址空间,所以task_struct->mm指针为NULL。
内核线程没有用户上下文。
内核线程只工作在内核空间,不会切换至用户空间。但内核线程同样是可调度且可抢占的。普通线程即可工作在内核空间,也可工作在用户空间。
内核线程只能访问3GB以上内核地址空间,而普通线程可访问所有4GB地址空间。
常见内核线程 | prio | policy |
irq | 49 | SCHED_FIFO |
softirq | 120 | SCHED_NORMAL |
worker | 120 | SCHED_NORMAL |
init | 120 | SCHED_NORMAL |
kthreadd | 120 | SCHED_NORMAL |
cfinteractive | 0 | SCHED_FIFO |
中断内核线程优先级很高,为49,并且使用了实时调度策略。softirq和worker都是普通内核线程。
init_workqueues中创建了绑定CPU0的两个kworker_pool,分别是nice=0和nice=-20。apply_workqueue_attrs创建unbund worker_pool,即kworker/uX:0,也有两个attr,分别是nice=0和nice=-20
其它特殊内核线程init优先级为120,kthreadd优先级为120.
cfinteractive优先级最高,主要处理CPU Frequency负载更新。
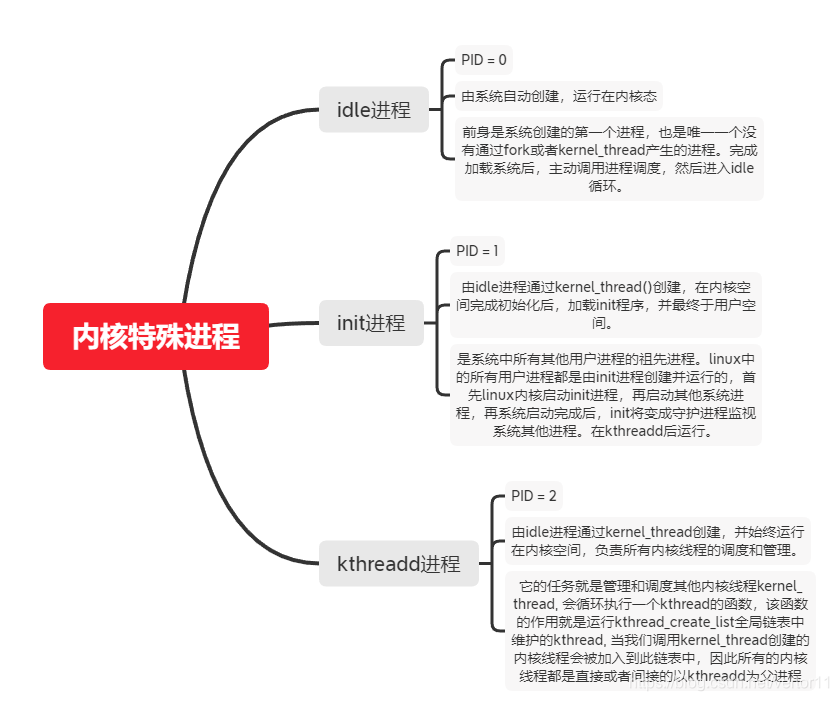
1.4.1几个特殊的内核进程
1.4.2内核线程相关API
kernel_thread()
kernel_thread接口,使用该接口创建的线程,必须在该线程中调用daemonize()函数,这是因为只有当线程的父进程指向”Kthreadd”时,该线程才算是内核线程,而恰好daemonize()函数主要工作便是将该线程的父进程改成“kthreadd”内核线程;默认情况下,调用deamonize()后,会阻塞所有信号,如果想操作某个信号可以调用allow_signal()函数。
kthread_create()
kthread_create接口,则是标准的内核线程创建接口,只须调用该接口便可创建内核线程;默认创建的线程是存于不可运行的状态,所以需要在父进程中通过调用wake_up_process()函数来启动该线程。
kthread_run()
创建并启动线程的函数; 线程一旦启动起来后,会一直运行,除非该线程主动调用do_exit函数,或者其他的进程调用kthread_stop函数,结束线程的运行。
kthread_should_stop(), kthread_stop()
停止线程
kthread_should_park(), kthread_parkme(), kthread_park(),kthread_unpark()
当在其他某个地方,调用 kthread_park(practice_task_p)后,线程将在kthread_parkme()处挂起睡眠,直到其他某个地方执行了kthread_unpark(practice_task_p)后,线程才被唤起,继续执行。
do_exit()
当线程执行到函数末尾时会自动调用内核中do_exit()函数来退出或其他线程调用kthread_stop()来指定线程退出。
1.6 抢占
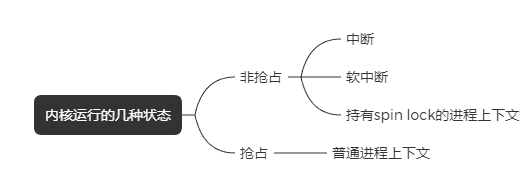
使用抢占式内核可以保证系统响应时间. 最高优先级的任务一旦就绪, 总能得到CPU的使用权。当一个运行着的任务使一个比它优先级高的任务进入了就绪态, 当前任务的CPU使用权就会被剥夺,或者说被挂起了,那个高优先级的任务立刻得到了CPU的控制权。如果是中断服务子程序使一个高优先级的任务进入就绪态,中断完成时,中断了的任务被挂起,优先级高的那个任务开始运行。
缺点
不能直接使用不可重入型函数。(即需要考虑高低优先级线程之间相关数据的竞态情况,需要加锁保护)
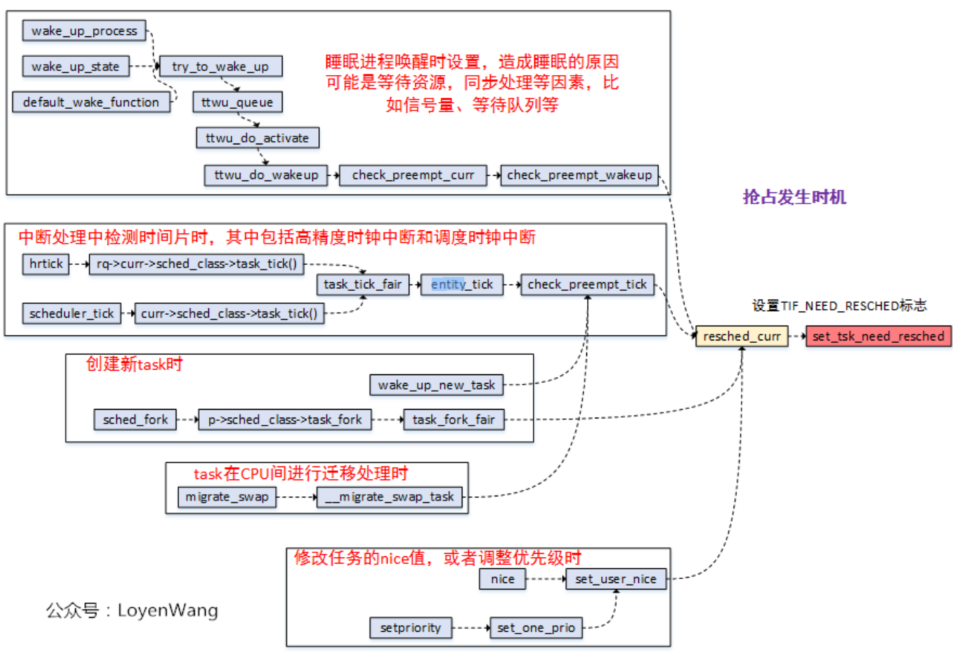
1.6.1 抢占触发点
不管是用户抢占还是内核抢占,抢占触发点是一样的。
内核提供了set_tsk_need_resched() 函数来将 thread_info中flag字段设置成TIF_NEED_RESCHED;
设置了TIF_NEED_RESCHED 标志,表明需要发生抢占调度;
1 | 信号量、等待队列、completion等机制唤醒时都是基于waitqueue的,而waitqueue的唤醒函数为default_wake_function(),其调用try_to_wake_up() 将被唤醒的任务更改为就绪状态并设置 need_resched 标志。 |
2 | 时钟中断处理例程检查当前任务的时间片,当任务的时间片消耗完时,scheduler_tick() 函数就会设置 need_resched 标志; |
3 | 新建一个任务时,可能会使高优先级的任务进入就绪状态; |
4 | 对CPU(SMP)进行负载均衡时,当前任务可能需要放到另外一个CPU上运行 |
5 | 设置用户进程的nice值时,可能会使高优先级的任务进入就绪状态; |
6 | 改变任务的优先级时,可能会使高优先级的任务进入就绪状态; |
1.6.2 抢占执行点
用户抢占
抢占执行发生在进程处于用户态。抢占的执行,最明显的标志就是调用了schedule() 函数,来完成任务的切换。具体来说,在用户态执行抢占在以下几种情况:
异常处理后返回到用户态;
中断处理后返回到用户态;
系统调用后返回到用户态;
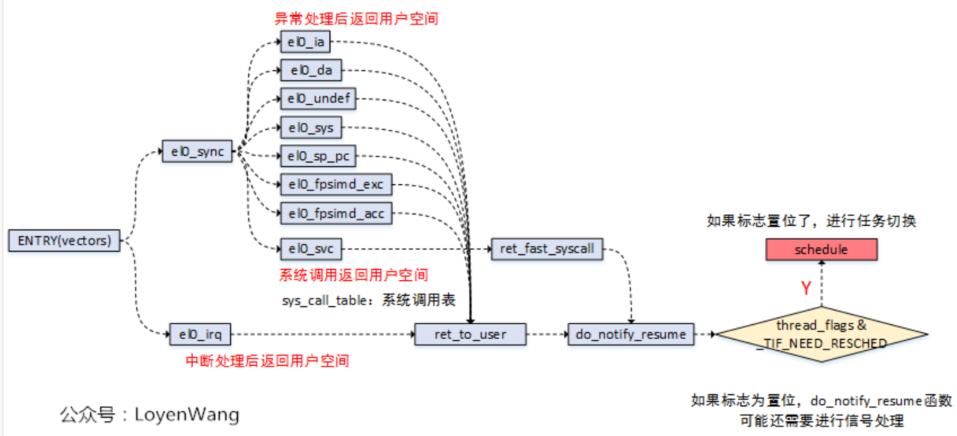
内核抢占
抢占执行发生在进程处于内核态。
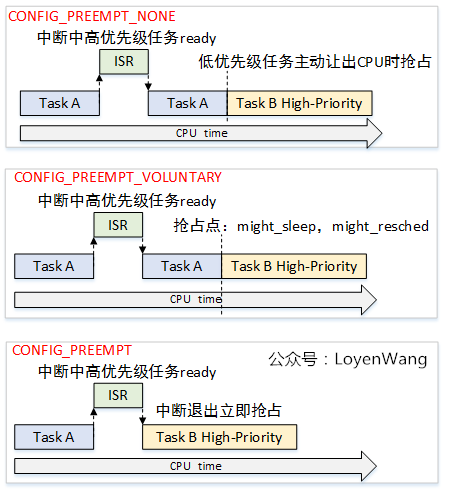
Linux内核有三种内核抢占模型:
CONFIG_PREEMPT_NONE
不支持内核抢占,中断退出后,需要等到低优先级任务主动让出CPU才发生抢占切换。
但是,linux也有针对不可内核抢占做了低延迟处理,即在一些耗时的routine中添加cond_resched() ,主动让出CPU;
一般服务器选择这种策略;
CONFIG_PREEMPT_VOLUNTARY
支持内核自愿抢占,即在一些耗时的routine中增加抢占点(提高实时性),在中断退出后遇到抢占点时进行抢占切换;
目前在linux上,该模型和上面模型相似,除了cond_resched() 点外,还增加了 might_resched(),实际等价于 __cond_resched()。
一般桌面系统选择这种策略;
CONFIG_PREEMPT
支持内核抢占,当中断退出后,如果遇到了更高优先级的任务,立即进行任务抢占;
有实时响应的内核选择这种策略;
三种抢占模型下,相关主动出让cpu的API

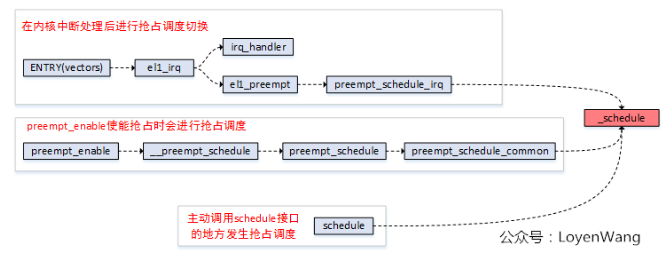
抢占执行点
不管是主动进行调度还是被动抢占式调度,最后,都会调用到__schedule() ,而 __schedule() 是属于关抢占上下文,在调度期间不允许被抢占。
被动抢占调度
中断执行完毕后
主动调度
preemp_enable()
schedule()
cond_resched()
msleep()/usleep_range()/ssleep()/fsleep()
waitqueue
semaphore, mutex,completion
spin_unlock()
local_bh_enable()
二. 进程调度
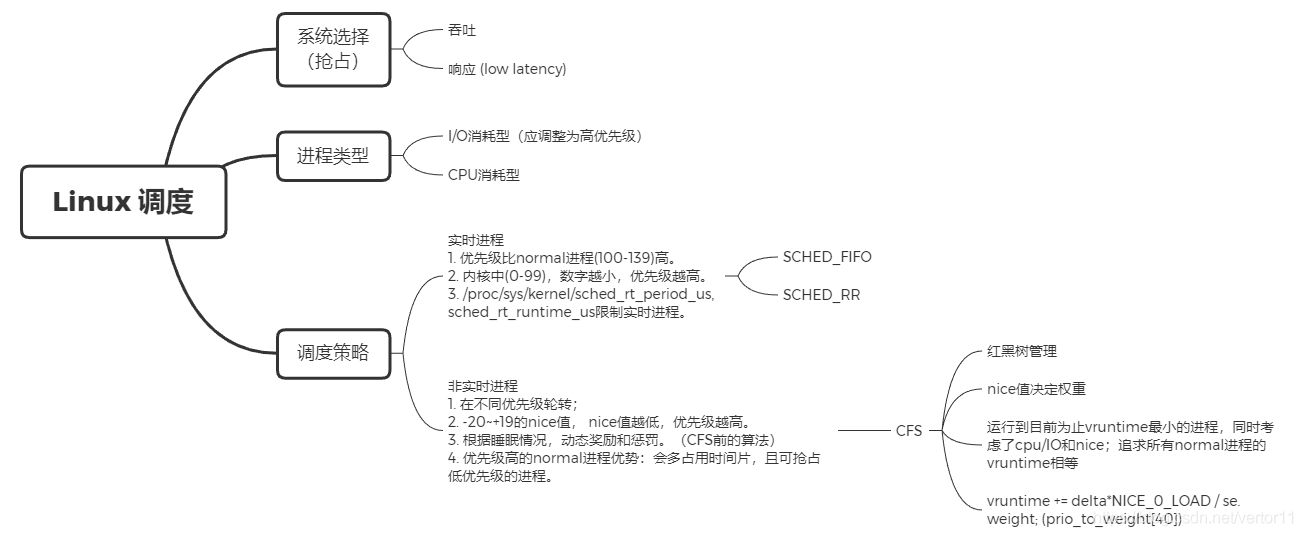
2.1吞吐 vs 响应:吞吐和响应之间的矛盾
响应:最小化某个任务的响应时间,哪怕牺牲其他任务为代价。
吞吐:全局视野,整个系统的workload被最大化处理。
2.2 I/O 消耗型 vs CPU消耗型
IO bound: CPU利用率低,进程的运行效率主要受限于I/O速度。
CPU bound:多数时间花在CPU上面(做运算)
2.3 优先级
linux系统中有多种优先级,下面是其关系:
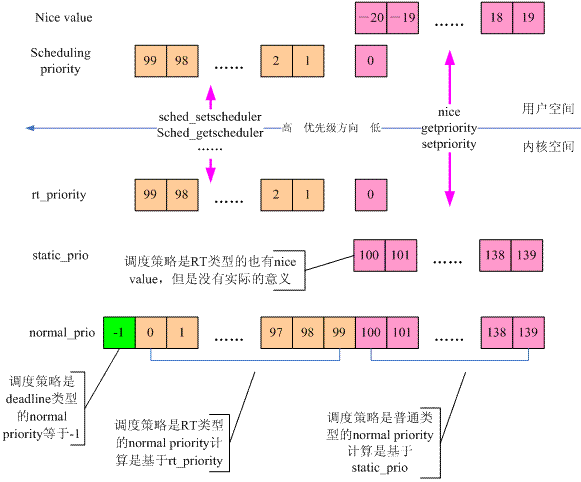
优先级 | |
字段 | 描述 |
static_prio | 用于保存静态优先级,可以通过nice系统调用来进行修改;(100 ~ 139) |
rt_priority | 用于保存实时优先级;0 - MAX_RT_PRIO-1 (0 - 99) |
normal_prio | 值取决于静态优先级和调度策略; |
prio | 用于保存动态优先级,调度器最终使用的。0 ~ 139(包括 0 和 139) |
2.3.1 prio动态优先级
prio 的值是调度器最终使用的优先级数值,即调度器选择一个进程时实际选择的值。
prio 值越小,表明进程的优先级越高。prio 值的取值范围是 0 ~ MAX_PRIO,即 0 ~ 139(包括 0 和 139),根据调度策略的不同,又可以分为两个区间,其中区间 0 ~ 99 的属于实时进程,区间 100 ~139 的为非实时进程。
当进程为实时进程时, prio 的值由实时优先级值(rt_priority)计算得来;
prio = MAX_RT_PRIO - 1 - rt_priority // 进程为实时进程
当进程为非实时进程时,prio 的值由静态优先级值(static_prio)得来。
prio = static_prio // 进程为非实时进程
2.3.2 static_prio 静态优先级
静态优先级不会随时间改变,内核不会主动修改它,只能通过系统调用 nice 去修改 static_prio。
通过调用 NICE_TO_PRIO(nice) 来修改 static_prio 的值, static_prio 值的计算方法如下:
static_prio = MAX_RT_PRIO + nice +20
MAX_RT_PRIO 的值为100,nice 的范围是 -20 ~ +19,故 static_prio 值的范围是 100 ~ 139。 static_prio 的值越小,表明进程的静态优先级越高。
2.3.3 normal_prio归一化优先级
normal_prio 的值取决于静态优先级和调度策略,可以通过 _setscheduler() 函数来设置 normal_prio 的值 。
对于非实时进程,normal_prio = static_prio
对于实时进程,normal_prio = MAX_RT_PRIO-1 - p->rt_priority。
2.3.4 rt_priority实时优先级
rt_priority 值的范围是 0 ~ 99,只对实时进程有效。
prio = MAX_RT_PRIO-1 - p->rt_priority
即rt_priority 值越大,则 prio 值越小,故 实时优先级(rt_priority)的值越大,意味着进程优先级越高。
rt_priority 的值也是取决于调度策略的,可以在 _setscheduler 函数中对 rt_priority 值进行设置。
2.4 调度器类SCHED_CLASS和调度策略 policy
所谓调度,就是按照某种调度的算法,从进程的就绪队列中选取进程分配CPU,主要是协调对CPU等的资源使用。进程调度的目标是最大限度利用CPU时间。
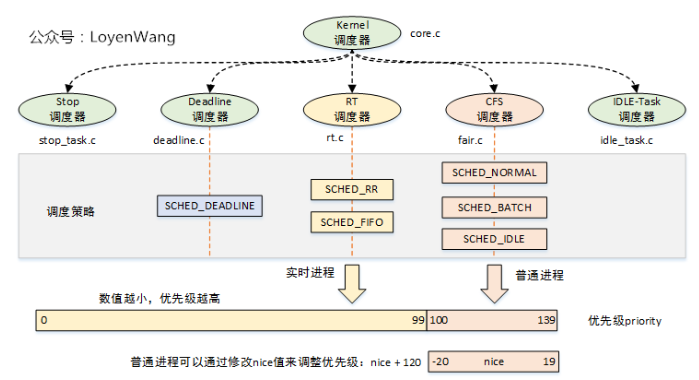
2.4.1调度器类
内核默认提供了5个调度器,Linux内核使用struct sched_class来对调度器进行抽象。
目前系統中,Scheduling Class的优先级顺序为stop_sched_class > dl_sched_class > rt_sched_class > cfs_sched_class > idle_sched_class
调度器类 SCHED_CLASS | 描述 | |
Stop调度器 stop_sched_class | 优先级最高的调度类,可以抢占其他所有进程,不能被其他进程抢占; 作用: 1.发生在cpu_stop_cpu_callback 进行cpu之间任务migration; 2.HOTPLUG_CPU的情况下关闭任务。 | |
Deadline调度器 dl_sched_class | 使用红黑树,把进程按照绝对截止期限进行排序,选择最小进程进行调度运行; | |
RT调度器 rt_sched_class | 实时调度器,为每个优先级维护一个队列; | |
CFS调度器 cfs_sched_class | 完全公平调度器,采用完全公平调度算法,引入虚拟运行时间概念; | |
IDLE-Task调度器 idle_sched_class | 空闲调度器,每个CPU都会有一个idle线程,当没有其他进程可以调度时,调度运行idle线程; |
2.4.2 调度策略
Linux内核提供了一些调度策略供用户程序来选择调度器,其中Stop调度器和IDLE-Task调度器,仅由内核使用,用户无法进行选择。
字段 POLICY | 描述 | 所在调度器类 |
SCHED_DEADLINE | 限期进程调度策略,使task选择Deadline调度器来调度运行; | Deadline |
SCHED_RR | 实时进程调度策略,时间片轮转,进程用完时间片后加入优先级对应运行队列的尾部,把CPU让给同优先级的其他进程; | RT |
SCHED_FIFO | 实时进程调度策略,先进先出调度没有时间片,没有更高优先级的情况下,只能等待主动让出CPU; | RT |
SCHEE_NORMAL | 普通进程调度策略,使task选择CFS调度器来调度运行; | CFS |
SCHED_BATCH | 普通进程调度策略,批量处理,使task选择CFS调度器来调度运行; | CFS |
SCHED_IDLE | 普通进程调度策略,使task以最低优先级选择CFS调度器来调度运行; | CFS |
2.5 RT调度策略和普通进程在调度算法上的差异
Linux的RT调度策略和普通进程在调度算法上面有差异,RT的SCHED_FIFO和SCHED_RR采用的是一个bitmap:
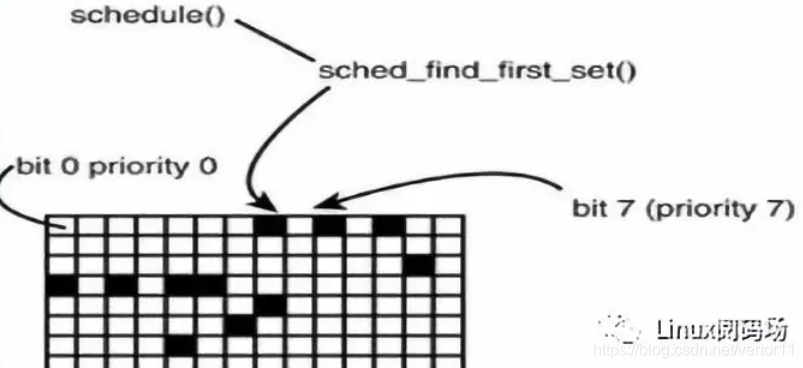
每次从第0bit开始往后面搜索第一个有进程ready的bit,然后调度这个优先级上面的进程执行,所以,在内核里面,prio数值越小,优先级越高。但是,从用户态的API里面,则是数值越大,优先级越高。
下面的代码,一个线程通过调用API把自己设置为SCHED_FIFO,优先级50。

这个上面的50,对应内核的49 (从内核的视角上面来看,又会用99减去用户在chrt里面设置的优先级)。
如果我们把优先级设置为51:

这个51,对应内核bitmap上面的48。
所以,你会发现,从用户的视角来看,数值变大,优先级变高。
对于RT的进程而言,TOP的视角里面的 PR= -1 -用户视角。
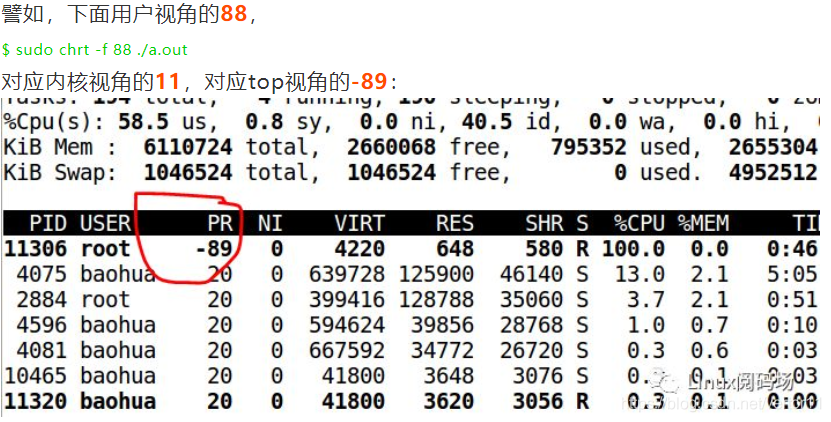
注:只有最高优先级的RT进程,才在top里面显示为rt。(用户视角的99---内核bitmap视角的0)
2.6 普通进程的优先级 nice
普通的讲nice的人相对来说比较简单,我们更关注它的nice值,-20~19之间,nice越低,优先级越高,权重越大,在CFS的红黑树左边的机会大。
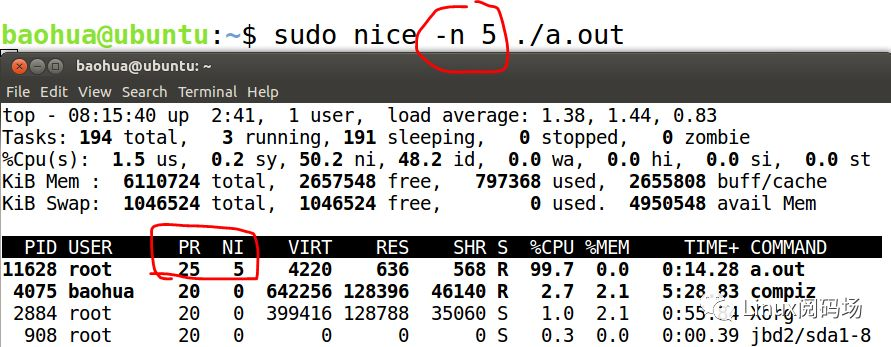
你发现.nice为5的进程,在top命令显示PR是25。
下面我们看nice是-5的:
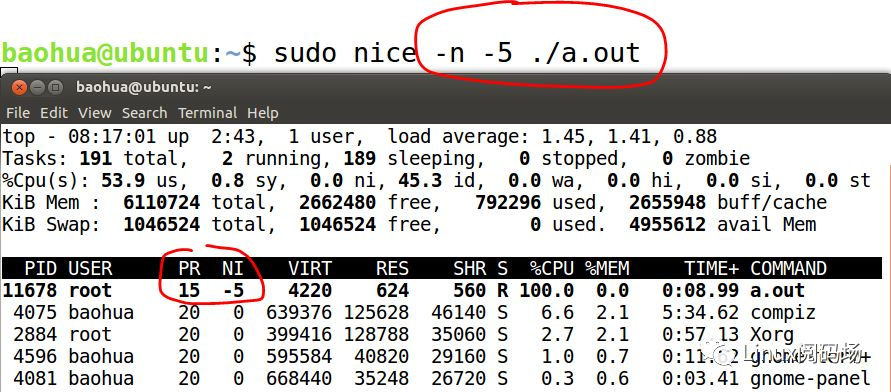

它显示的是PR=15。
由此大家可以发现规律,对于普通的采用CFS策略的NORMAL进程,top里面的 PR=20+NICE

由此发现,在top里面,RT策略的PR都显示为负数;最高优先级的RT,显示为rt。top命令里面也是,数字越小,优先级越高。
2.7 ps 中的RTPRIO, PRI,NI
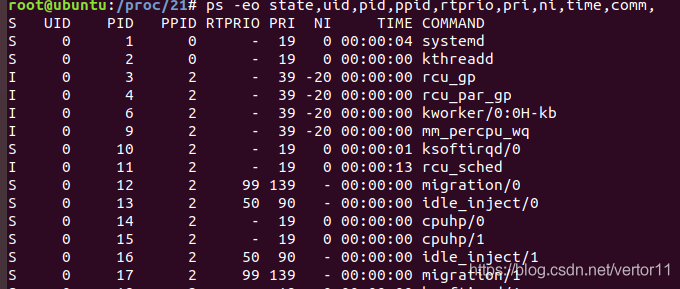
一个是PRI,一个是NI,这到底是什么东西?相对而言,PRI也还是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小进程的优先级别越高。那NI呢?就是我们所要说的nice值了,其表示进程可被执行的优先级的修正数值。如前面所说,PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为:PRI(new)=PRI(old)+nice。这样,当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行。
到目前为止,更需要强调一点的是,进程的nice值不是进程的优先级,他们不是一个概念,但是进程nice值会影响到进程的优先级变化。
注:这里的PRI = 139 - 内核中prio。即该值越大,优先级越高。
2.8 rt的门限

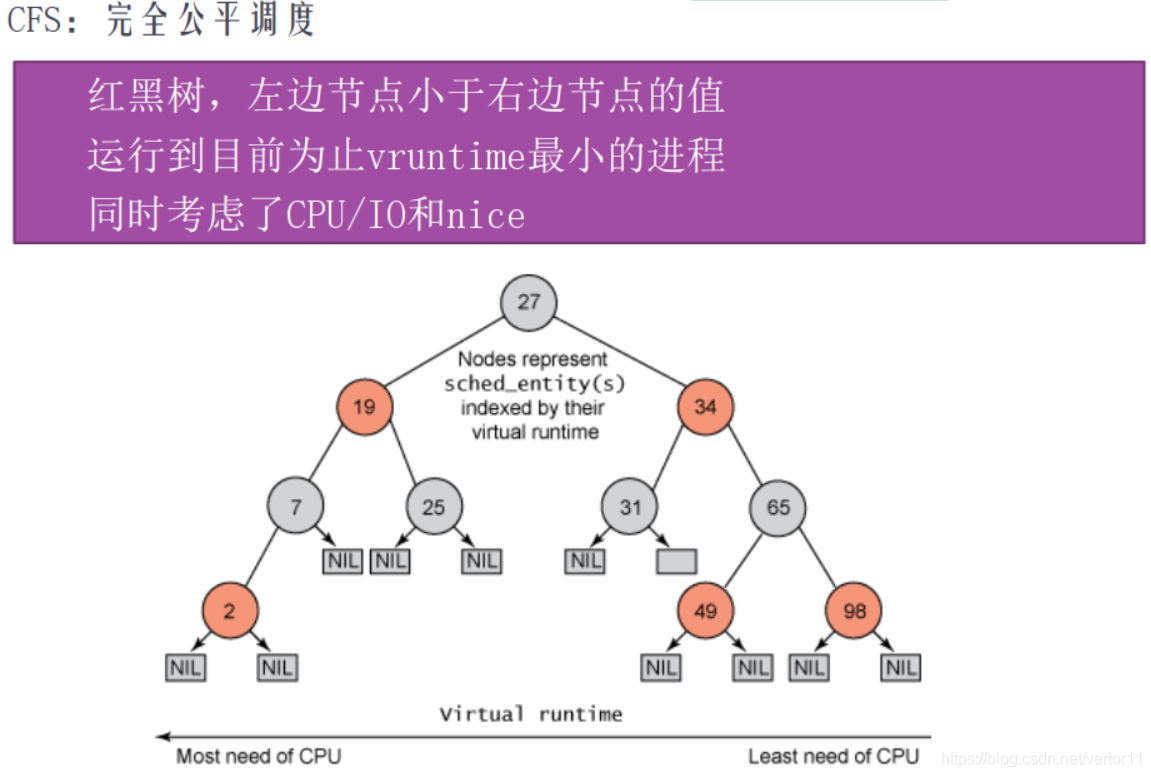
2.9 CFS调度


2.10 怎样修改进程优先级?


2.10.1 实时进程调度

2.10.2 非实时进程的调度和动态优先级


2.11 怎样查看linux系统中的实时进程和普通进程?
ps -eo state,uid,pid,ppid,rtprio,time,comm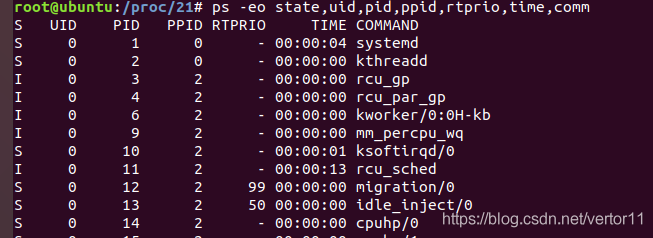
RTPRIO
"-": 表示普通进程
"数字": 表示优先级为xx的实时进程

















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









