




 本文介绍如何使用Apache Storm进行实时数据流处理,并利用Redis存储处理结果。通过具体示例,包括SentenceSpout数据源、SplitSentenceBolt数据拆分、WordCountBolt词频统计及WriteRedisBolt结果存储,展示了一个完整的实时计算流程。
本文介绍如何使用Apache Storm进行实时数据流处理,并利用Redis存储处理结果。通过具体示例,包括SentenceSpout数据源、SplitSentenceBolt数据拆分、WordCountBolt词频统计及WriteRedisBolt结果存储,展示了一个完整的实时计算流程。
使用Redis将最终Bolt的结果存储起来。
引入storm-redis依赖,继承AbstractRedisBolt。
1. pom.xml
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-redis</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
2. SentenceSpout
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
public class SentenceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private List<String> sentenceList = Arrays.asList(
"Hadoop,Storm,Hive,HBase",
"Storm,HBase,Storm"
);
private Integer index = 0;
@Override
public void open(Map<String, Object> conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
/**
* Storm将会循环调用该方法
*/
@Override
public void nextTuple() {
if (index < sentenceList.size()) {
final String sentence = sentenceList.get(index);
// 发射时需要指定 消息id
collector.emit(new Values(sentence), index);
index++;
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
}
3. SplitSentenceBolt
/**
* 将句子分隔成单词
*/
@Slf4j
public class SplitSentenceBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
try {
String sentence = input.getStringByField("sentence");
String[] words = sentence.split(",");
// 将每个单词流向到下一个Bolt
for (String word : words) {
// 发射时携带发射过来的input
collector.emit(input, new Values(word));
}
// 处理成功了给当前tuple做一个成功的标记,调用上游的ack方法
collector.ack(input);
} catch (Exception e) {
log.error("SplitSentenceBolt#execute exception", e);
// 异常做一个失败的标记,调用上游的fail方法
collector.fail(input);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
4. WordCountBolt
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.HashMap;
import java.util.Map;
public class WordCountBolt extends BaseRichBolt {
private OutputCollector collector;
private Map<String, Long> wordCountMap = null;
/**
* 大部分示例变量通常在prepare中进行实例化
* @param topoConf
* @param context
* @param collector
*/
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.wordCountMap = new HashMap<>();
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Long count = wordCountMap.get(word);
if (count == null) {
count = 0L;
}
count++;
wordCountMap.put(word, count);
collector.emit(new Values(word, count));
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
5. WriteRedisBolt
import org.apache.storm.redis.bolt.AbstractRedisBolt;
import org.apache.storm.redis.common.config.JedisPoolConfig;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import redis.clients.jedis.JedisCommands;
import java.util.HashMap;
import java.util.Map;
public class WriteRedisBolt extends AbstractRedisBolt {
public WriteRedisBolt(JedisPoolConfig config) {
super(config);
}
@Override
protected void process(Tuple tuple) {
String word = tuple.getStringByField("word");
Long count = tuple.getLongByField("count");
JedisCommands jedisCommands = getInstance();
jedisCommands.hset("wordcount", word, count.toString());
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
6. WordCountTopology
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.redis.common.config.JedisPoolConfig;
import org.apache.storm.topology.TopologyBuilder;
import org.example.redis.bolt.SplitSentenceBolt;
import org.example.redis.bolt.WordCountBolt;
import org.example.redis.bolt.WriteRedisBolt;
import org.example.redis.spout.SentenceSpout;
public class WordCountTopology {
public static void main(String[] args) throws Exception {
// Redis配置
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig.Builder()
.setHost("127.0.0.1")
.setPort(6379)
.setPassword("123456")
.setTimeout(3000)
.build();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new SentenceSpout(), 1);
builder.setBolt("split-bolt", new SplitSentenceBolt()).shuffleGrouping("spout");
builder.setBolt("word-count-bolt", new WordCountBolt()).shuffleGrouping("split-bolt");
builder.setBolt("write-redis-bolt", new WriteRedisBolt(jedisPoolConfig)).globalGrouping("word-count-bolt");
StormTopology topology = builder.createTopology();
// 提交拓扑
Config config = new Config();
config.setDebug(true);
if (args == null || args.length == 0) {
// 本地模式
config.setDebug(true);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("WordCountTopology", config, topology);
} else {
// 集群模式
config.setNumWorkers(2);
StormSubmitter.submitTopology(args[0],config,builder.createTopology());
}
}
}
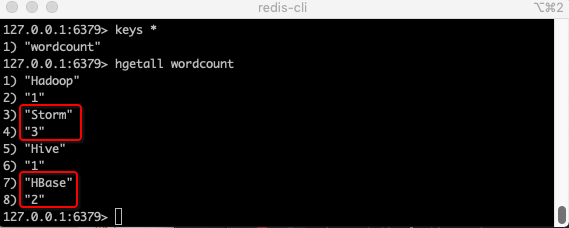
7. 运行mian方法


















 1048
1048




 到【灌水乐园】发言
到【灌水乐园】发言









