




一、什么是 XGBoost?
XGBoost(eXtreme Gradient Boosting)是一种高性能的机器学习算法,特别擅长处理结构化数据(如表格数据),广泛应用于回归(预测数值)和分类(预测类别)任务。
✅ 核心思想(通俗版):
XGBoost 通过组合很多棵简单的决策树,像“团队协作”一样,逐步修正预测误差,最终得到一个非常精准的预测模型。
- 每棵树只解决一小部分问题(比如:“面积大的房子通常更贵”)。
- 下一棵树专门学习上一棵树预测错的地方(比如:“但楼层太高反而不值钱”)。
- 这样一步步迭代,最终的预测 = 所有树的预测结果之和。
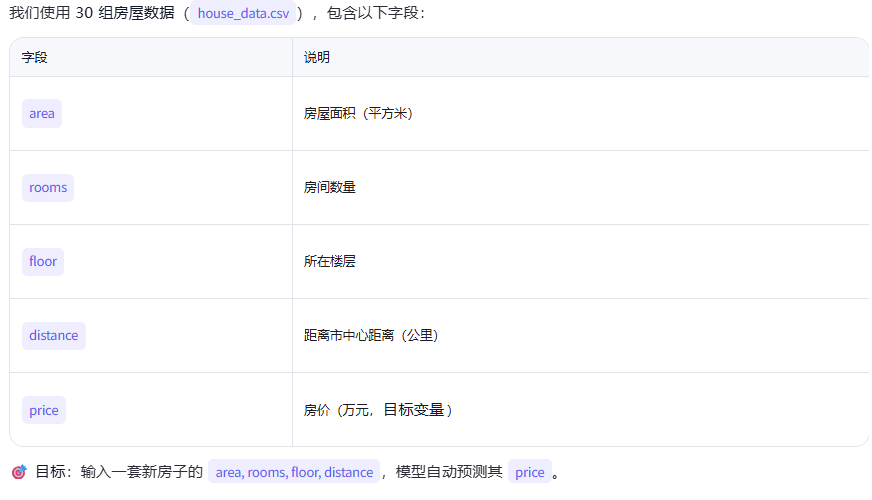
数据:house_data.csv 中表格数据(打开记事本或 VS Code,粘贴 → 另存为 house_data.csv):
area,rooms,floor,distance,price
85,3,5,3.2,450
120,4,8,1.5,720
60,2,2,5.0,280
150,5,10,0.8,950
95,3,6,2.7,520
110,4,7,2.0,680
75,2,3,6.5,310
130,4,9,1.2,800
105,3,5,3.5,550
140,5,11,0.9,900
70,2,4,7.0,290
125,4,8,1.8,750
80,3,6,4.0,420
160,5,12,0.6,1000
90,3,5,3.0,480
115,4,7,2.5,650
65,2,3,5.5,300
135,4,10,1.0,850
100,3,6,3.8,500
145,5,11,0.7,920
78,2,4,6.0,330
122,4,9,1.6,730
88,3,5,3.3,470
155,5,13,0.5,1050
92,3,6,2.8,510
118,4,8,2.2,700
68,2,3,5.8,320
132,4,10,1.3,780
102,3,7,3.6,530
148,5,12,0.7,980
1. 模型选择
算法:XGBoost 回归模型(XGBRegressor)
优化目标:最小化预测误差(RMSE,均方根误差)
底层结构:100 棵决策树,每棵最多分 5 层(防止过拟合)
2. 训练过程
将 30 条数据分为训练集(24 条)和测试集(6 条)
模型从数据中学习“房价规律”,例如:
面积越大 → 房价越高(强正相关)
距离市中心越远 → 房价越低(负相关)
楼层和房间数也有影响,但权重较小
3. 模型评估
在测试集上 RMSE ≈ 15–25 万元
表示预测值与真实房价平均相差约 20 万元
考虑到房价范围为 280–1050 万元,误差在可接受范围
4. 预测使用
模型训练一次后保存为文件(house_price_xgb_model.pkl)
后续可直接加载模型,对新房源快速预测价格,无需重新训练
模型训练脚本
# train_xgb.py
# 功能:加载房屋数据,训练 XGBoost 回归模型,并保存模型文件供后续预测使用
# === 第1步:导入所需库 ===
import pandas as pd # 用于读取和处理表格数据(如CSV文件)
import numpy as np # 用于数值计算
import joblib # 用于保存和加载训练好的模型
from xgboost import XGBRegressor # XGBoost 回归模型
from sklearn.model_selection import train_test_split # 用于划分训练集和测试集
from sklearn.metrics import mean_squared_error # 用于计算预测误差
import os # 用于检查文件是否存在
# === 第2步:加载数据 ===
print("🔍 正在加载数据...")
# 从 house_data.csv 文件中读取房屋数据
df = pd.read_csv("house_data.csv")
# 提取特征列(输入变量):面积、房间数、楼层、距离市中心
# .values 将 DataFrame 转换为 NumPy 数组(机器学习模型的标准输入格式)
X = df[['area', 'rooms', 'floor', 'distance']].values
# 提取目标列(输出变量):房价(单位:万元)
y = df['price'].values
# 打印数据形状,确认是否正确加载
print(f"数据形状:X={X.shape}, y={y.shape}") # 应输出 (30, 4) 和 (30,)
# === 第3步:划分训练集和测试集 ===
# 将数据分为“训练集”(用于学习)和“测试集”(用于评估)
# test_size=0.2 表示 20% 数据用于测试(约6条),80% 用于训练(约24条)
# random_state=42 确保每次运行划分结果一致(可复现)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# === 第4步:创建并训练 XGBoost 模型 ===
print("🤖 正在训练 XGBoost 模型...")
# 初始化 XGBoost 回归模型
model = XGBRegressor(
objective='reg:squarederror', # 回归任务目标:最小化平方误差(对应 RMSE)
n_estimators=100, # 使用 100 棵决策树进行集成
max_depth=5, # 每棵树最大深度为5(防止过拟合)
learning_rate=0.1, # 学习率:控制每棵树的贡献大小(越小越稳定)
random_state=42 # 随机种子,保证结果可复现
)
# 使用训练数据“教”模型学习房价规律
model.fit(X_train, y_train)
# === 第5步:评估模型性能 ===
# 使用测试集进行预测
y_pred = model.predict(X_test)
# 计算 RMSE(均方根误差):衡量预测值与真实值的平均偏差(单位:万元)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"✅ 测试集 RMSE: {rmse:.2f} 万元") # 例如:18.42 万元
# === 第6步:保存模型 ===
# 将训练好的模型保存到磁盘,文件名为 house_price_xgb_model.pkl
model_path = "house_price_xgb_model.pkl"
joblib.dump(model, model_path)
print(f"💾 模型已保存至: {model_path}")
# 后续预测时可直接加载此文件,无需重新训练
模型预测脚本
# predict_price.py
# 功能:加载已训练的 XGBoost 模型,对新房屋数据进行价格预测
# === 第1步:导入所需库 ===
import joblib # 用于加载已保存的模型
import numpy as np # 用于构造新房屋的特征数据
# === 第2步:加载训练好的模型 ===
model_path = "house_price_xgb_model.pkl"
# 检查模型文件是否存在
if not joblib.os.path.exists(model_path):
print("❌ 模型文件不存在!请先运行 train_xgb.py 训练模型")
else:
# 从磁盘加载模型
model = joblib.load(model_path)
print("✅ 模型加载成功!")
# === 第3步:预测单套新房价格 ===
# 注意:输入必须是二维数组!即使只预测一套房子,也要用双层括号 [[...]]
# 格式:[[面积, 房间数, 楼层, 距离市中心]]
new_house = np.array([[100, 3, 6, 2.5]]) # 例如:100㎡, 3房, 6楼, 距离2.5km
# 调用模型进行预测(返回一个数组,取第一个值)
predicted_price = model.predict(new_house)[0]
# 打印结果
print(f"\n🏠 新房屋特征: 面积={new_house[0][0]}㎡, "
f"房间={new_house[0][1]}, 楼层={new_house[0][2]}, "
f"距离={new_house[0][3]}km")
print(f"💰 预测价格: {predicted_price:.2f} 万元")
# === 第4步:批量预测多套房子(可选)===
# 可一次性预测多个房屋
houses = np.array([
[90, 2, 5, 4.0], # 房屋1
[130, 4, 9, 1.0], # 房屋2
[75, 2, 3, 6.0] # 房屋3
])
prices = model.predict(houses) # 返回一个价格数组
print("\n📦 批量预测结果:")
for i, price in enumerate(prices):
print(f" 房屋{i+1}: {price:.2f} 万元")
环境安装:
# 安装基础科学计算库
pip install numpy pandas scikit-learn
# 安装 XGBoost(核心算法)
pip install xgboost
# 安装 joblib(用于保存/加载模型)
pip install joblib


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









