






本来是准备写个开发过程 ,写完发现完全是个思考的过程,很值得记录,如果您没有兴趣看过程,可以直接拖到最后
一、创作灵感
原因是专技人员每年都必须学习公需科目和专业科目(据说还有挺多地方纳入考核),以往每年都是网上随便找个快速播放的插件就搞定,今年网站升级后,直接前端操作播放器的脚本都不能用了,于是我决定自己研究一个。
二、思考步骤
既然前端的脚本都失效了,意味着不能通过调用js里面的方法模拟前端发送请求,通常油猴也是这样实现某些功能的。于是我决定从后端请求入手,先看看关键的记录课程进度的方法有没有规律可循,用python模拟这个请求,看看是否能够成功发送请求,如果服务器有响应就补齐请求的请求头和携带参数,实现全自动;如果请求没反应,就看看是不是有一些请求验证,先找到请求的鉴权逻辑,再用python模拟加密过程,最后携带这些鉴权的东西发送课程相关请求。整个过程就是自下而上,从解决关键问题开始入手,如果一开始就失败,那就不用进行后续步骤,节约时间。话不多说,开干!
三、开干
1.直接进入视频播放界面抓请求
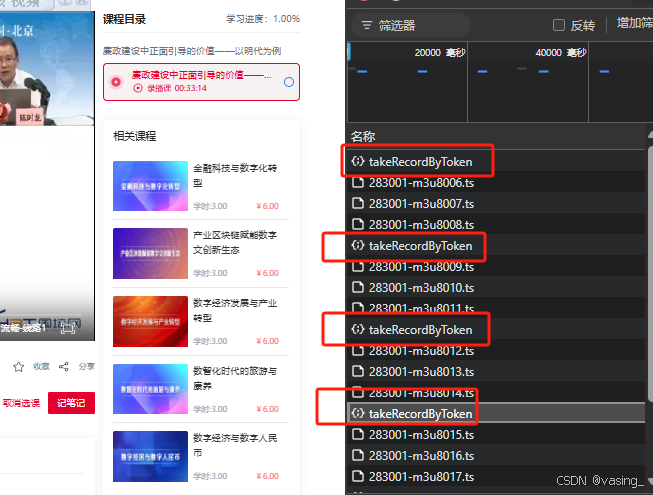
播放视频界面会出现这些动态的请求,很明显ts结尾的是视频流,忽略,takeRecordByToken就是记录课程进度的参数了,先把他转为python,试着发一次再说后话。
2.转换python请求
直接用request库,复制这个请求
import requests
cookies = {
'p_h5_u': '16F1CFCC-428E-40F0-9C1A-7712E951CBFA',
'JSESSIONID': 'C81989CA320CFCA256C4A8BBE704EA87',
'Hm_lvt_69ccfa3777e8e6193e66dde22ab2c896': '1728396152,1729429211',
'HMACCOUNT': 'F7D8AE90398762BB',
'Hm_lpvt_69ccfa3777e8e6193e66dde22ab2c896': '1729429484',
}
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Type': 'text/html;charset=UTF-8',
# 'Cookie': 'p_h5_u=16F1CFCC-428E-40F0-9C1A-7712E951CBFA; JSESSIONID=C81989CA320CFCA256C4A8BBE704EA87; Hm_lvt_69ccfa3777e8e6193e66dde22ab2c896=1728396152,1729429211; HMACCOUNT=F7D8AE90398762BB; Hm_lpvt_69ccfa3777e8e6193e66dde22ab2c896=1729429484',
'Origin': 'https://videoadmin.chinahrt.com',
'Pragma': 'no-cache',
'Referer': 'https://videoadmin.chinahrt.com/videoPlay/playEncrypt?param=M6FUERTovrwJKhmQd7T7TyNBK%2BVNxhzqSH0PXmorPcZ3rSPEh3uIvka%2FyE3InQ%2F4KQ10ZDPXDfHpXIXR%2BcI5FbEJzxuiNJ27XTKne2kfX8TwXayEpRR%2BBx2qNm6PaNCE53UxECkhSGHXaE2JZNesZcBB1Bq7RHzNHSfUBuJKLjfmarzBgbbLGN2syT6eiq6vwEyaN4d0RseygKNXisXChNY0p7ylVdk4v1dbWewWqZtVdu0J73xZQ7r7FzhTOuZFKAKA5DApDeVet0oKX%2B1T72HaonAl7xEwaRjJS0sISh%2Bx7hh085VbEYnbGOQzwAzt9r1PD1nveiK0F9ElfMXEfEeJyD7Rp3BoP0ox3i7gbmDBdHvIAYusrm%2BSxGJiw0Cwc0%2BSk8b5h7GxnJEpTQXmIReBKmZhOABCb%2BY2hniYaUOl%2FTxpl4WF6VJgWq3%2F1Q8YXijcMrgL52mkVlvg8mqH7cyZbps%2BlrlncBvgPNhLrrMfnojw%2F3rBFCvaVD7oVSCatPfvP%2Fry5fXVUuGWvhil2Gc1Pn3wDeZvDLNu39BtYQIcPsn4JvFAS7bhnDL1T6VAvF2OQdTNM3hbI8Ho2y417ckA4FD%2BuCydSA1K4LfvN32%2BijY20tTM33kP%2F%2BKqIz6LMK9be4N56ZXvt6mKiOGpZxyRTj26en1RgbG59HviGc9YvwQvNtsHeTtL5pCiUtcnNWypiar8z%2FnD4N1CwQc3dqetKDlu3vMvcbKZlUPKBdQ%3D',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0',
'sec-ch-ua': '"Chromium";v="130", "Microsoft Edge";v="130", "Not?A_Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
data = '{"token":"96503fb687505503c28f6587168209e0","time":112}'
response = requests.post(
'https://videoadmin.chinahrt.com/videoPlay/takeRecordByToken',
cookies=cookies,
headers=headers,
data=data,
)
print(response.text)运行结果

天大的好消息,服务器有返回。至此可以确定后续步骤
- 尝试更换请求参数,改变课程进度
- 尝试多次发送请求,是否被拦截
- 尝试补齐获取课程等所有完整过程
3.更换请求参数
这个请求里面只有两个参数,一个token,一个time,很明显time肯定是记录的进度秒数,这个就直接猜测就行,token暂时不知道,但是肯定是跟验证有关的,一步一步来,先看time。
3.1先给time改个值
先加个100秒测试,仍然有返回,刷新页面,确实记录了100秒,再加个500秒,哦豁,没得搞了![]()
这说明,每次增加的时间是有限制的,不能直接给个视频最大的时长,然后结束,但是给到100秒内好像没问题,于是需要看看前面几次的请求参数,这个规律

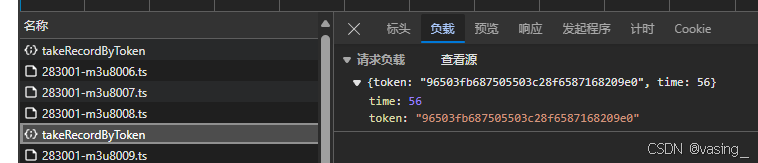
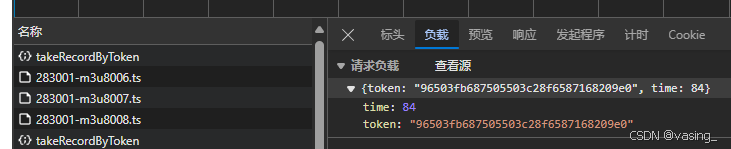
截三张图,想必一眼明了,首先时间是28的倍数,每次增加28秒。按照这个规律给time改参数,试试可否行得通,
if __name__ == '__main__':
token = 'fd33fc71403281f7252a4fedbddb0cbc'
sutytime = 2560
takeRecode2(token,str(sutytime))
time.sleep(1)
takeRecode2(token, str(sutytime + 28))
time.sleep(1)
takeRecode2(token, str(sutytime + 56))
time.sleep(1)
takeRecode2(token, str(sutytime + 84))
time.sleep(1)
takeRecode2(token, str(sutytime + 112))大佬们先别喷,为什么不用循环,目前只是验证猜想,没必要讲究,还没到规范代码那一步。让我们看看运行结果先;
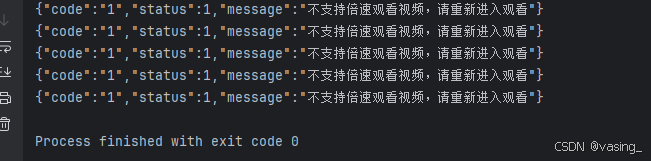
这不又完犊子了吗,别急,观察一下视频播放页面,刷新,进度还是保存在最后一次提交的,但是刷新后,token变了,所以时间参数暂时验证到这,至少目前确定time可以小范围改动后发送请求,让我先解决这个token问题。
3.2 找到token的规律
刷新页面从第一个token开始,多截图保存几次请求,看看token的规律,跟上面的图一样,token前几次都是一样,只有时间以28的倍数增长,但是四五次请求后,token变了,搜一下这个新token,发现是最后一次请求时,服务器返回的,客户端记录了这个token,在下一次新请求时带上了新token,那不就续上了吗,所以接下来的步骤很明显:
- 时间仍然每次加28秒,记录每次的token,如果token改变就换上新的token发请求
- 找到第一个token的来源,实现本节课的自动化播放
第一个步骤很简单,从客户端复制第一个token,放到代码里面接上,看看运行结果再说,别一次性搞太多,容易崩心态。
if __name__ == '__main__':
token = '96503fb687505503c28f6587168209e0'
sutytime = 30
add = 28
for i in range(100):
print(i)
res = takeRecode2(token, str(sutytime + add * i))
time.sleep(1)
if res['code'] != "0":
res = takeRecode2(token, str(sutytime + add * i))
else:
if res['data'] != token:
token = res['data']运行结果会让你柳暗花明
刷新页面,进度条成功涨了一大截,按照这个速度就相当于28倍速看视频了。
至此其实已经没有必要再往下写了,猜想已经验证成功,单节课可以28倍速刷完,剩下的工作就是找到第一个token,然后找到所有课程的请求参数,循环课程执行这个请求,这些都是很基本的操作了。整个就是一个思考过程,自下而上,一步步验证猜想。花费了不到20分钟时间快速验证了猜想的可行性。如果你也想获取完整代码可以+v:vasing2
简单罗列一下剩下的步骤:
- 找到课程的第一个token:全局搜索就行,发现在首次打开课程视频页面的html里面,解析出来直接用就ok
- 获取所有课程循环执行:从小节课程倒推章节课程,再倒推学年课程,这里就跟用户登录有关了,请求头里的cookie有鉴权,不过是很简单的方式。
- 可选步骤:用多线程同时刷,所有课程同步进行,刷完一年的课程相当于这一年最长的一节视频的时长除以28(理论上是这么多,实际运行下来还是要花一个小时,手动狗头)
4.按照前面步骤补齐代码
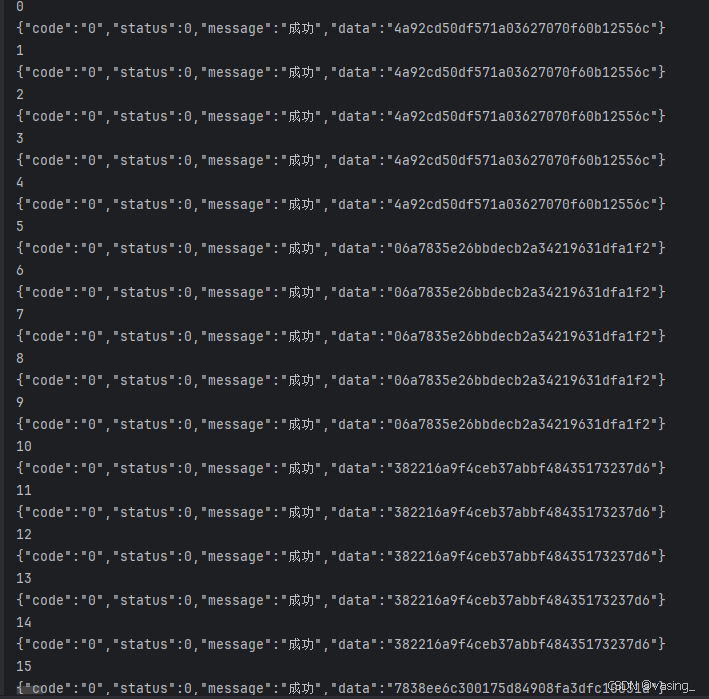
代码太多没法贴了,让我们看看最后代码写完的截图吧。收工
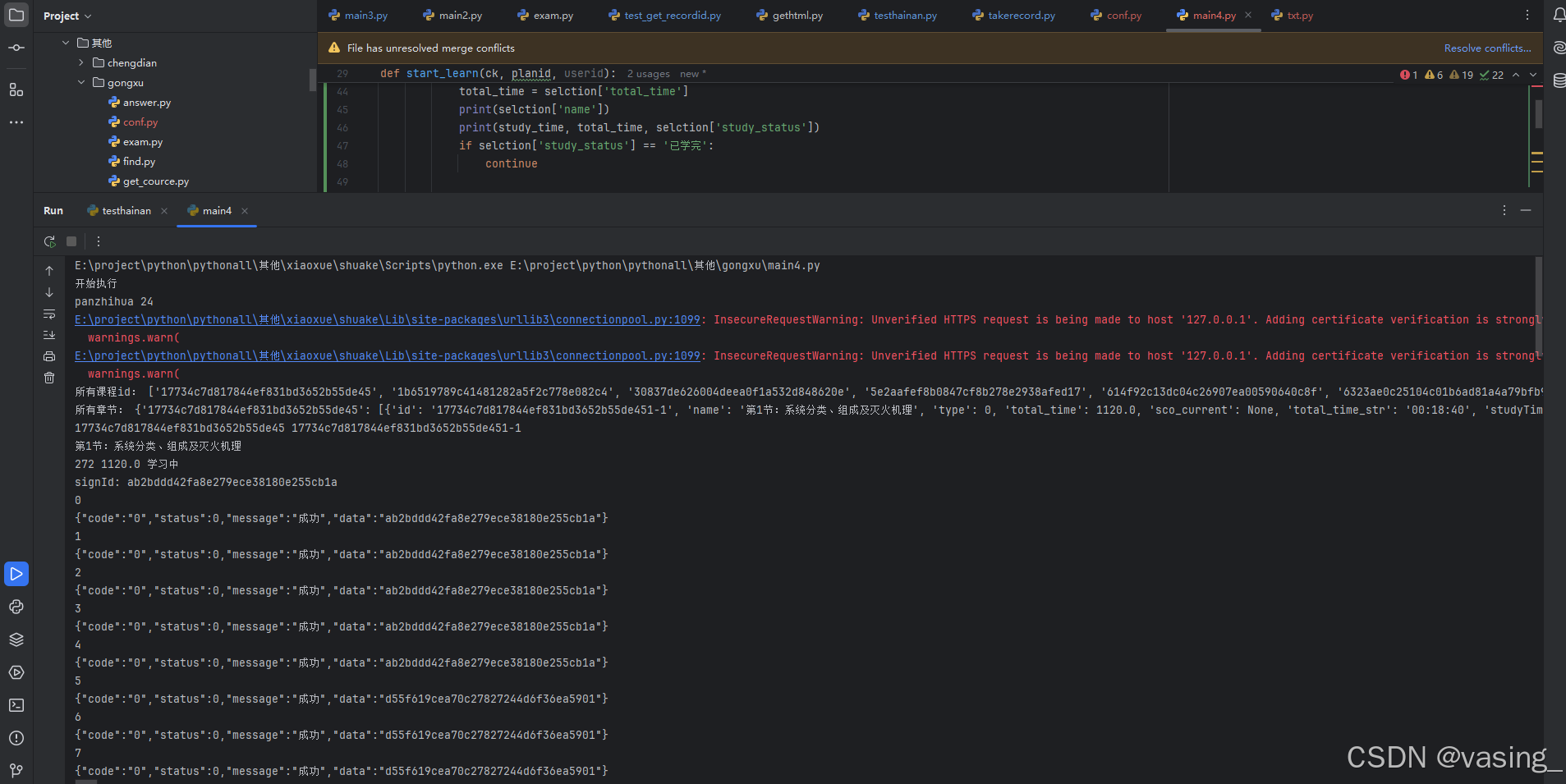
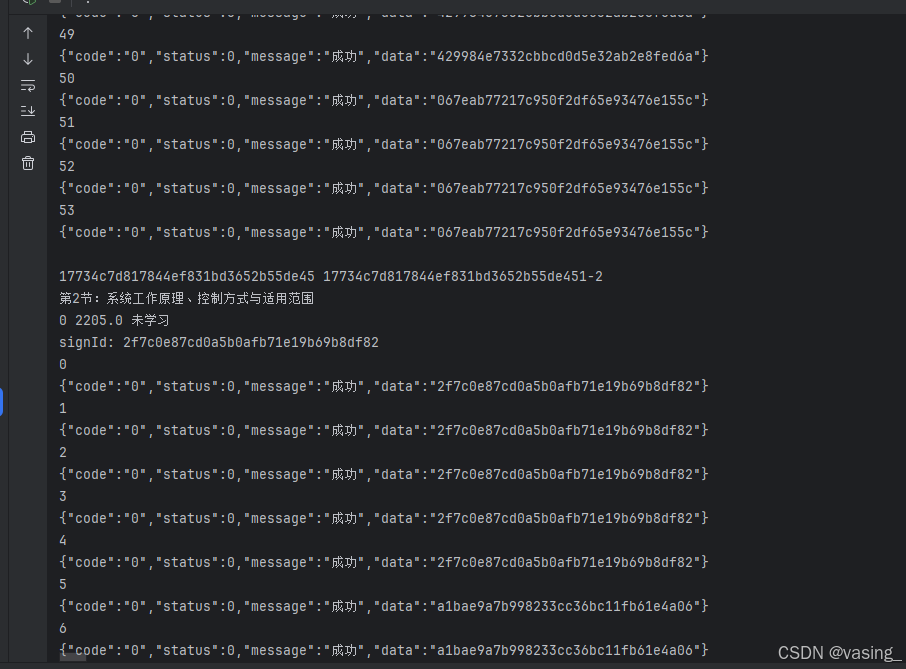

















 3192
3192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









