




前言
在本博客中,GMR已经出现过多次,如下图所示
加之,近期我们在研究beyondmimic过程中,在我组建的交流群内,有朋友交流道
- Zorpia:beyondmimic是用gmr重定向的么,gmr重定向效果怎么样呀
- 郑:我尝试的是GMR重定位,感觉效果挺不错的
如此,让我再次关注到了这个GMR,特此,本文来解读下
第一部分 GMR:面向人形动作追踪的通用动作重定向
1.1 引言与相关工作
1.1.1 引言
如GMR原论文所说,要让人形机器人策略在真实世界环境中实现真正的泛化,必须从能够反映物理交互的数据中进行学习
- 鉴于人类与类人机器人在形态结构上的相似性,近期的研究工作
1-Whole-body geometric retargeting forhumanoid robots
2-Learning human-to-humanoid real-time whole-body teleoperation,即为H2O
3-Exbody
4-Real-world humanoid locomotion with reinforcement learning
5-Humanplus
6-Twist
7-Hub: Learning extreme humanoidbalance
8-Kungfubot
利用三维人体运动数据『来源于动作捕捉[9-AMASS],或基于视频的人体动作恢复[7-Hub]、[8-Kungfubot]、[10-VideoMimic]』作为示范,训练类人机器人完成需要类似人类平衡性和灵活性的全身动作
这些类人机器人运动跟踪策略是构建远程操作流程或分层控制系统的基础工具
然而,在骨骼长度、关节活动范围、运动学结构、身体形态、质量分布以及驱动机制等方面,人类与人形机器人之间仍然存在显著差异 - 克服这种体现差异的标准方法是将源人体运动通过运动学重定向到目标人形机器人上
在获得重定向后的数据后,当前机器人研究中一种流行的做法是采用基于强化学习RL的方法,通过参考动作模仿来学习能够完成期望任务的策略
在大多数情况下『除了[11-ASAP]中提到的例外』,该策略会被直接零样本部署到真实世界中。这种做法
要么忽略了重定向过程中引入的明显伪影(如脚滑、地面穿透以及因自身穿透导致的物理不可能动作),强行要求RL策略在保持物理约束的同时模仿物理上不可行的动作
已有研究
12-Humanoid-gym
13-Hover
14-Omnih2o
11-ASAP
表明,虽然可以在仿真中使用带有严重伪影的重定向数据进行策略训练,但将其迁移到现实世界(即sim2real)需要大量的反复试验、奖励函数设计和参数调优
简言之,重定向过程中引入的伪影,如脚部滑动、自我穿透以及物理上不可行的动作,往往会残留在参考轨迹中,留待RL策略去纠正
尽管已有研究展示了动作跟踪能力,但通常需要大量的奖励工程和域随机化才能取得成功(很大程度上缓解或消除重定向带来的伪影)——如果缺乏这些工程化措施,重定向结果的质量就会起到决定性作用
对此,来自Stanford University的研究者:João Pedro Araújo†1, Yanjie Ze†1, Pei Xu†1, Jiajun Wu*1, C. Karen Liu*1,共同提出了一种新的重定向方法——通用动作重定向(GMR)
- 其paper地址为:Retargeting Matters: General Motion Retargeting for Humanoid Motion Tracking
- 其项目地址为:github.io/retargeting_matters
其GitHub地址为:github.com/YanjieZe/GMR
最早发布于2025-08-04: Initial release of GMR. Check our twitter post
后于2025-09-16: GMR now supports to use GVHMR for extracting human pose from monocular video and retargeting to robot.
且作者将GMR与两个开源重定向器
- PHC,该方法被近期多项类人机器人动作跟踪研究广泛采用[2-H2O],[11-ASAP];
- ProtoMotions,用于重定向具有挑战性的动态任务[8];
以及Unitree提供的高质量闭源数据集进行了对比评估
为了隔离重定向方法的影响,作者采用 BeyondMimic[15]对跟踪给定参考动作的强化学习策略进行训练和评估。BeyondMimic 不依赖于奖励调整,并且与作者使用的重定向方法独立开发,因此可以作为评估这些方法的公正手段
- 作者认为,重定向方法的选择对人形机器人性能有着至关重要的影响。虽然基于不同重定向方法生成的动作进行训练的策略通常能够跟踪多种动作,包括简单和高度动态的动作(这一点与以往研究结果一致),但在某些情况下,重定向过程中引入的伪影会使策略的学习变得更加困难,甚至在某些情况下完全无法有效学习
- 这些案例突显了如果没有以往工作中广泛的奖励工程,重定向伪影确实会对某些动作带来挑战(足部穿透、自身交叉和突发的速度尖峰都是在重定向过程中必须避免的关键伪影),并降低策略性能
1.1.2 相关工作
第一,动作重定向是计算机图形学中角色动画常用的数据处理技术
- 经典方法
16-Physically based motion transformation
17-physically-based motion retargeting filter
18-Motion adaptation based oncharacter shape
19-On-line motion retargetting
采用基于优化的方法,并依赖于启发式定义的运动学约束,将动作映射到带有关节的角色上
随着深度学习技术的发展,数据驱动的方法逐渐出现然而,这些方法通常需要配对数据来进行监督学习
20-A variational u-net for motionretargetin
21-Same: Skeleton-agnosticmotion embedding for character animation
或需要语义标签以无监督方式进行模型训练
22-Neural kinematicnetworks for unsupervised motion retargetting
23-Skeleton-aware networks for deep motion retargeting
24-Pose-awareattention network for flexible motion retargeting by body part
或者利用语言模型和可微渲染技术进行视觉评估
25-Semantics-aware motion retargeting withvision-language models
除了针对单一刚体角色的重定向,既有文献还提出了多角色交互重定向的方法
26-Composition of complexoptimal multi-character motion
27-Simulation and retargeting of complex multi-character interactions
28-Geometry-awareretargeting for two-skinned characters interaction
以及适用于可变形角色的重定向方法
29-Surface based motionretargeting by preserving spatial relationship
30-Contact-aware retargeting of skinned motion
31-Skinned motion retargeting with residualperception of motion semantics & geometry - 在机器人领域,尽管数据驱动方法已被广泛用于控制人形机器人
2-H2O
3-Exbody
4-Real-world humanoid locomotion with reinforcement learning
5-Humanplus
7-Hub
8-Kungfubot
6-Twist
10-visualmimic
15-Beyondmimic
通过模仿学习生成类人动作,但在真实机器人上获取配对或具有语义标签的动作数据较为困难,这限制了数据驱动重定向方法在人形机器人上的应用
虽然已有一些研究
32-Robust motion mapping betweenhuman and humanoids using cycleautoencoder
33-Imitationnet: Unsupervisedhuman-to-robot motion retargeting via shared latent space
34-Unsupervised neural motion retargeting for humanoid teleop-eration
探索了基于学习的人形机器人动作重定向方法,但这些工作仅关注于简单的手臂和上半身动作
本文则专注于涉及行走等全身动作重定向的方法,并且这些方法无需预先收集任何数据
第二,朴素的方法[3-Exbody],[5-Humanplus]直接将源人类动作的关节旋转复制到目标人形机器人的关节空间
- 然而,由于人类个体与人形机器人在拓扑结构和形态上的差异,常常会导致诸如漂浮、脚部穿透与滑动以及末端执行器(脚和手)漂移等伪影
- 此外,还需要额外的处理步骤,将人类的SO(3)关节空间转换为人形机器人(通常仅配备旋转关节)所适用的空间
第三,通过求解逆运动学(IK)问题,整体几何重定向(WBGR)方法能够在允许源关节空间与目标关节空间不对齐的情况下实现全身重定向
- 基础的WBGR方法[35-Robust real-time whole-body motion retargeting from human to humanoid],[1-Whole-body geometric retargeting forhumanoid robots]
忽略了笛卡尔空间中的尺寸差异,仅通过逆运动学来匹配关键连杆的方向 - 相比之下,HumanMimic [36]则通过逆运动学实现关键点的笛卡尔位置匹配,同时采用手动设定的系数对源动作进行缩放
第四,H2O [2] 利用近期在计算机图形学中关于人体表示的研究,采用 SMPL [37] 模型将机器人形状拟合为人体,并据此对动作进行缩放,然后再求解逆运动学(IK)问题
- 相关的参考实现可在 PHC[38] 代码库中找到,本文将该方法称为 PHC 重定向方法
该方法通过正向运动学利用梯度下降法来求解 IK 问题,但这一过程耗时较长,限制了其在实时场景中的应用 - 尽管 PHC 方法已被许多后续工作采用
14-Omnih2o
13-Hover
39-Harmon
11-ASAP
但在动作重定向过程中并未考虑动作的接触状态,这可能导致漂浮、脚步滑移以及与地面穿透等伪影
此外,SMPL 设计用于人体表示,对于与人类形态存在较大差异的机器人,其适用性有限
- 其他研究 [40-Protomotions: Physics-based character animation]、[8-Kungfubot]、[6-Twist] 探索了不同的使用方式
——
这些IK求解器[41-Mink: Python inverse kinematics based on MuJoCo]通过对源动作的笛卡尔关节位置进行缩放,然后计算广义速度,使其在原地积分后能够减少缩放后源动作与机器人之间在笛卡尔关节位置和姿态上的误差 - ProtoMotions方法[40]采用全局轴对齐缩放因子,对源动作中的关节笛卡尔位置进行缩放,然后最小化源人体动作与机器人之间匹配关键部位的位置和姿态误差的加权和
比如,KungfuBot[8]采用了ProtoMotions的方法,但关闭了缩放功能
1.2 通用动作重定向GMR的完整方法论
整个GMR的流程如下图所示
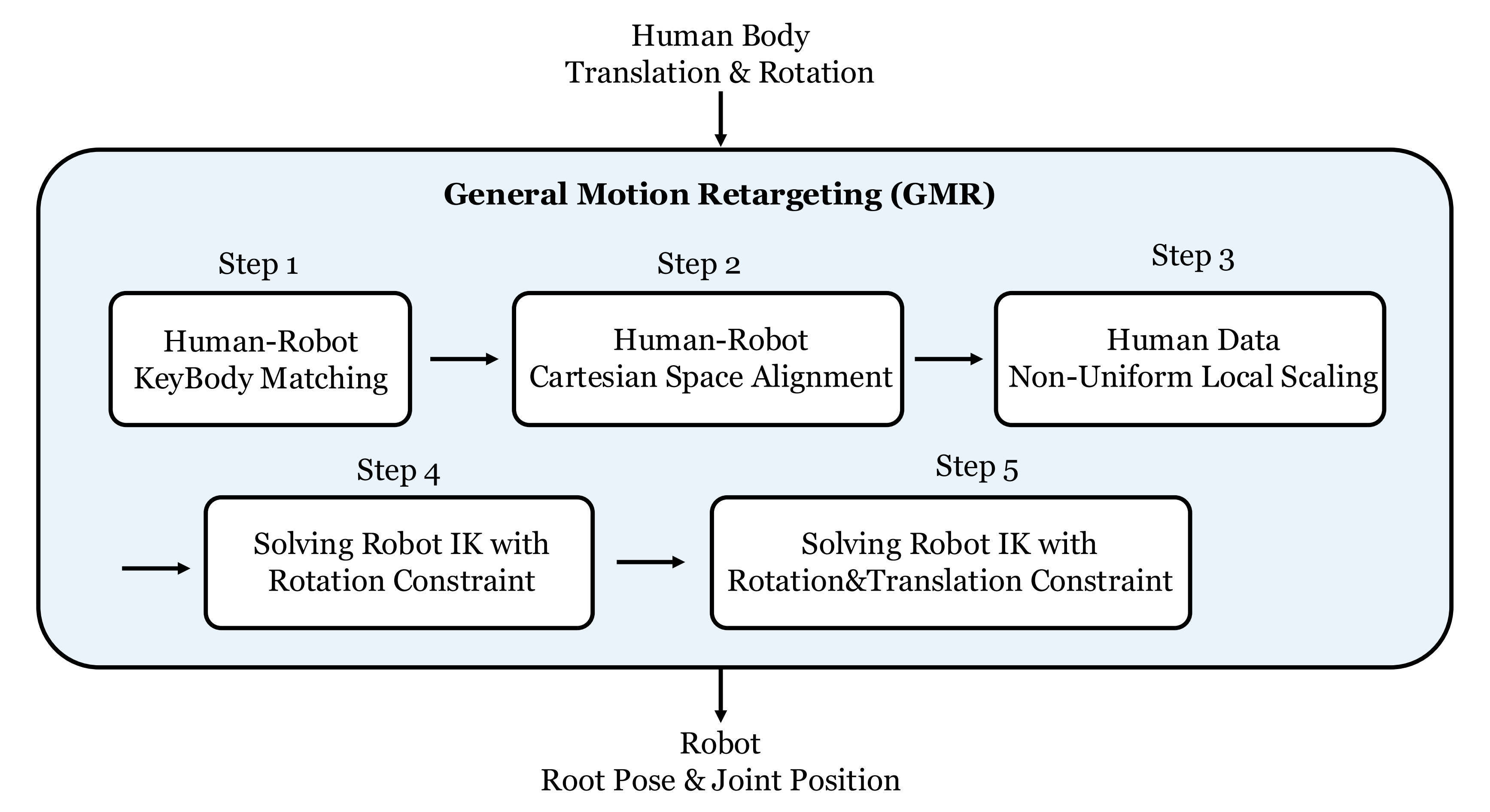
1.2.1 步骤1:人-机器人关键身体部位匹配
首先,从源人类骨骼中的身体部位列表开始(这些部位可以来自动作捕捉系统,或如BVH 和SMPL 等格式的文件),以及目标人形机器人骨骼(可在XML 或URDF 机器人描述文件中找到)
用户首先需要定义人类和机器人关键身体部位之间的映射(通常包括躯干、头部、腿、脚、手臂和手)
这些信息用于为逆运动学(IK)求解器建立优化问题。用户还可以为这些关键部位的位置和姿态跟踪误差提供权重
1.2.2 步骤2:人-机器人笛卡尔空间静止姿态对齐
作者对人体的姿态进行偏移,使其在静止姿态下与机器人身体的姿态保持一致。在某些情况下,作者还会对某一身体部位的位置添加局部偏移。这有助于减轻如文献[2-H2O]中所描述的内八字等伪影
1.2.3 步骤3:人体数据非均匀局部缩放
作者发现,大多数在其他重定向方法中出现的伪影都是在对源动作进行缩放时引入的,这突显了正确缩放的重要性
作者的缩放流程的第一步是根据源人体骨架的高度计算一个通用缩放因子。该通用因子用于调整为每个关键身体部位定义的自定义局部缩放因子
自定义缩放因子的设置使作者能够考虑下半身与上半身之间的缩放差异
- 例如,目标身体在笛卡尔空间中的位置由以下公式给出
其中,为人体骨架的高度,
为设定缩放因子时假定的参考高度,
表示身体部位的位置,
为对应于身体部位
的缩放因子
- 注意,当该身体部位为根节点时,缩放方程可简化为
作者发现,通过对根部平移应用统一的缩放因子,对于避免引入脚部滑动伪影至关重要
1.2.4 步骤4:带有旋转约束的机器人逆运动学求解
接下来,作者希望找到机器人广义坐标 (包括根部平移、根部旋转和关节数值),使其相对于参考姿态最小化身体位置和方向误差
为了避免局部最优解,作者采用了两阶段处理过程
- 给定目标姿态,在第一阶段,求解如下优化问题,仅考虑身体方向和末端执行器的位置(定义为公式4):
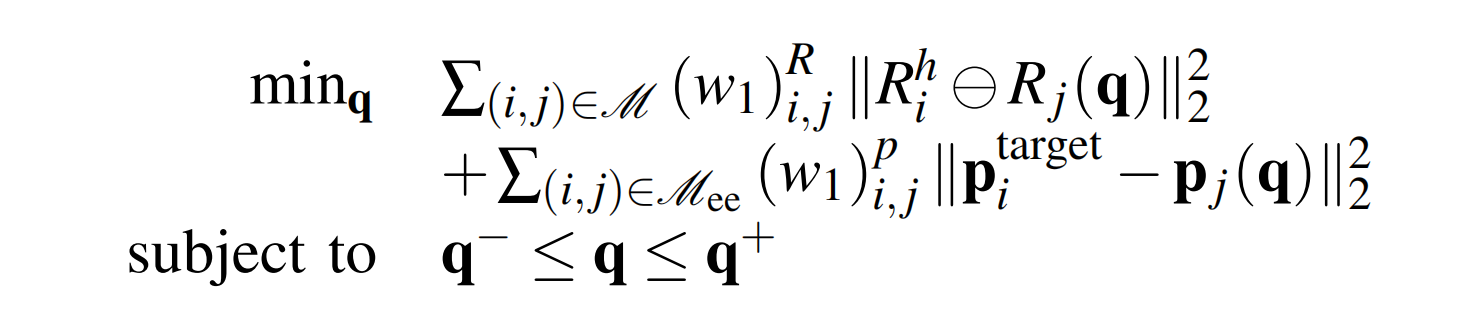
在上述内容中
表示人体
的朝向
和
分别是机器人身体
的笛卡尔位置和朝向(通过正向运动学获得)
是
与
在
中的朝向差的指数映射表示
和
分别是第一阶段优化中的位置和朝向误差权重
以及人体根关键体的方向偏航分量进行初始化
优化受到关节最小值和最大值
和
的约束
————
作者发现有时需要收紧这个范围以避免非人类动作。且使用Mink(一种微分逆运动学求解器)来解决这个问题。这意味着,不是寻找最小化代价函数的值,而是计算广义速度
,通过积分可以降低代价
这是通过求解以下优化问题实现的
其中
是公式4 中的损失函数
是损失关于
的雅可比矩阵
是由
和
引入的权重矩阵
是微分IK 求解器的一个参数,并不一定对应于参考动作帧之间的时间差
作者再运行求解器直至收敛(价值函数的变化小于给定阈值,将其设为 0.001),或者达到最大迭代次数(10 次)
1.2.5 步骤5:利用旋转与平移约束进行精调
- 最后,作为上述流程的第二阶段
作者将前一个问题的解作为初始猜测,继续求解
它使用了一组与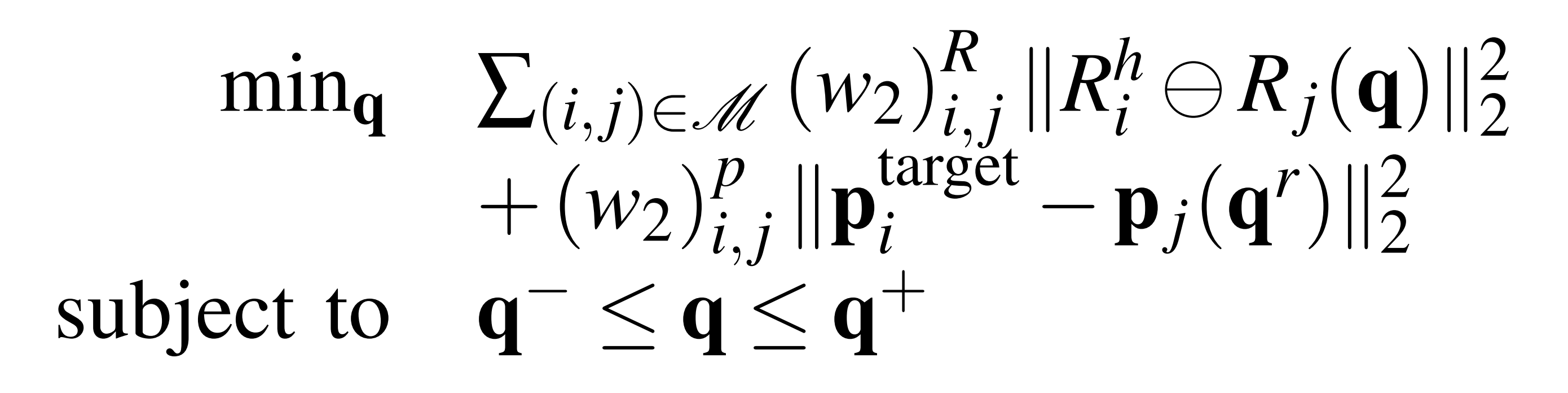
————
第一阶段
——————————
所用不同的权重和
,并且考虑了所有关键部件的位置
且,第一阶段优化中的终止条件同样适用
上述方法主要用于重定向单一姿态。对于运动序列的重定向,该方法会依次应用于每一帧,并将前一帧的重定向结果作为第4步优化的初始猜测
完成整个运动序列的重定向后,通过正向运动学计算所有机器人部件在各时刻的高度。随后,将最小高度值从全局平移中扣除,以修正高度伪影(如悬浮或穿透地面现象)
// 待更
第二部分 PHC:实时仿真虚拟人的持续控制
- 其paper地址为:Perpetual Humanoid Control for Real-time Simulated Avatars
- 其项目地址为:zhengyiluo.com/PHC-Site
其GitHub地址为:github.com/ZhengyiLuo/PHC
// 待更


















 1916
1916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











