






论文:Towards Feature Space Adversarial Attack by Style Perturbation
代码(TensorFlow版本):GitHub - qiulingxu/FeatureSpaceAttack: Code for AAAI 2021 "Towards Feature Space Adversarial Attack".
1. 像素攻击缺点和本文贡献
现阶段大多数针对图像分类的攻击都是基于图像像素空间的,也就是说,有界扰动直接应用于像素。但其实对抗性攻击可以在风格相关的特征空间中进行,在训练过程中,CNN可能会提取大量的抽象特征。比如说人肉眼可以观测到的关键特征,其中还有一些次要特征,例如,图像的不同风格(例如,鲜艳的颜色与苍白的颜色,清晰的轮廓与模糊的轮廓)。这些次要特征可能在模型预测中发挥重要作用,本文的贡献如下:
(1):我们提出FeatureSpaceAttack可以往图片注入一些次要特征(例如风格),这些次要特征不是简单的像素扰动,而是给定良性输入上的函数,从而导致模型误分类。由于人类对这些特征并不敏感,因此从人类的角度来看,产生的对抗性示例看起来很自然
(2):像素空间防御技术可能对FeatureSpaceAttack无效(参见评估部分)

2. 前置知识
Arbitrary style transfer in real-time with adaptive instance normalization
3.FeatureSpaceAttack原理
3.1 大致思想
在底层,我们认为通过神经网络前几层(如VGG)的激活值表示为一组抽象特征,包括主要和次要特征。区分这两种类型的特征对于特征空间攻击的质量至关重要。为了避免生成不自然的对抗性示例,我们避免篡改主要特征(或内容特征),并专注于干扰次要风格特征。受风格迁移最新进展的启发(Huang and Belongie 2017),激活的均值和方差被认为是风格。因此,我们专注于扰动均值和方差,同时保留激活值的形状(即这些值的起伏和这种起伏的相对规模)。我们使用梯度驱动优化来搜索可能导致错误分类的风格扰动,我们把相同类里不同图片之间的差异视作为风格差异
在训练过程中,模型选择了许多特征,其中许多特征并没有描述对象的关键特征(或内容),而是人类难以察觉的特征,如风格。这些细微的特征可能在模型预测中发挥不恰当的重要作用。因此,将这些特征注入正常图像可能生成对抗样本导致错误分类。具体来说,攻击包括两个阶段:(1)Decoder training phase:训练一个decoder,该decoder可以将特征空间扰动转换为对人类来说看起来很自然的像素级变化;(2)首先使用基于梯度的优化方法识别可能导致误分类的特征空间扰动,然后使用encoder生成特征空间embedding,再改变embedding的方差和均值来生成相应的对抗样例来发起攻击
3.2 Decoder training phase
下面是训练decoder的整体流程:
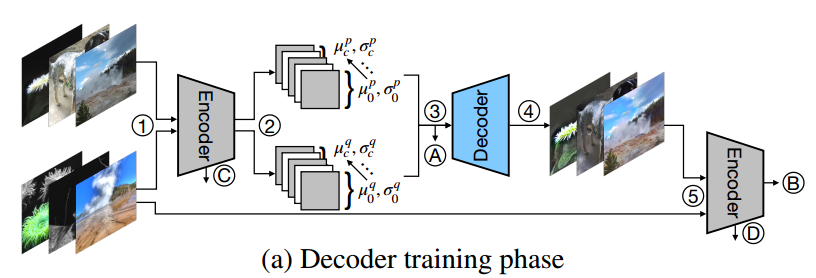
①②③:每次训练输入两张图片,一张称为content,一张称为style,两张图片都是同一个类别(因此它们的差异可以直观地视为风格差异),这两张图片被馈送到固定的encoder,该encoder本质上由预训练模型的前几层组成(例如VGG),通过encoder生成的两个特征空间称为embedding,是三维矩阵,然后计算每一个通道均值和方差,我们使用这些均值和方差去合并生成ntegrated embedding 。例如:给定一个正常图像xp和另一个图像xq(来自与xp相同的类),训练过程首先将它们通过预训练的编码器f(例如,VGG-19,在图上称为encoder)来获得嵌入Bp = f(xp);Bq = f(xq) ∈ R H·W·C,其中C为通道尺寸,H和W为每个通道的高度和宽度。对于每个通道c,计算跨空间维度的均值和方差
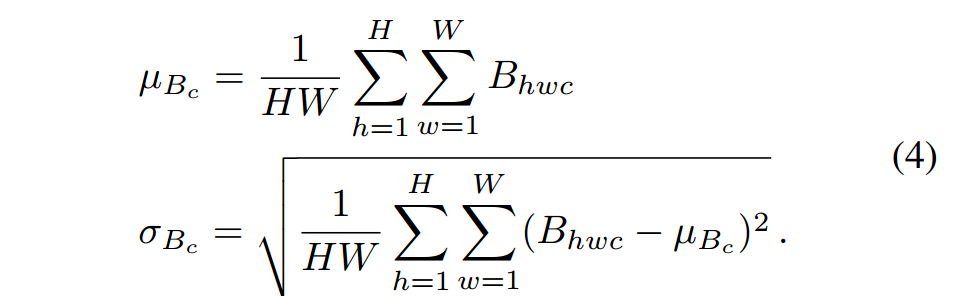
然后根据下面的公式直接合并Bp,Bq的embedding为integrated embedding
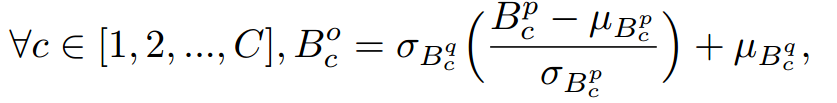
④⑤:正式训练decoder,目的是将integerated embedding变成和content一样的图片,以实现肉眼观察不了的扰动添加,步骤是将integerated embedding通过decoder变成对抗图像reconstruction,然后再通过encoder生成embedding(称为Br),再次将content通过encoder生成embedding(称为Bo),然后尽量实现Br和Bo越接近越好,Br和Bo的差距称为内容损失(L content)
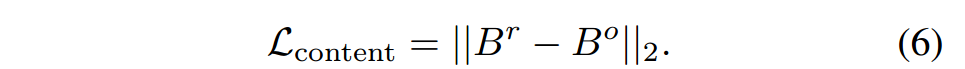
并且我们希望通过decoder生成的对抗图像reconstruction(Xr)在风格上接近style(Xq)图片,才能起到很好的风格迁移效果,风格损失的定义如下
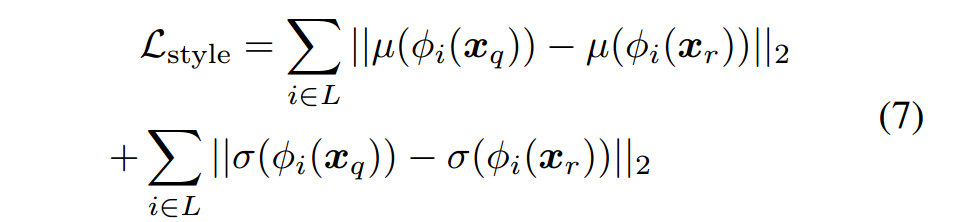
其中![]() 指定的是encoder的第i层,
指定的是encoder的第i层,![]() 和
和![]() 指出均值和方差,最后decoder的训练是最小化Lcontent + Lstyle
指出均值和方差,最后decoder的训练是最小化Lcontent + Lstyle
3.3 Two Feature Space Attacks
训练完decoder后,下面是特征空间攻击的整体流程
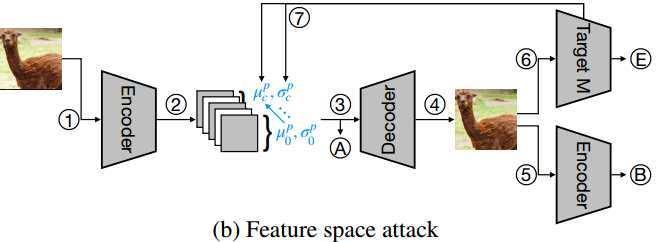
Encoder和Decoder的参数均被固定住,这里只有content图片被输入到Encoder中,生成的embedding矩阵会根据公式改变均值和方差(这个就是添加扰动的过程),然后再通过Decoder还原为对抗图片,A和B会计算content Loss,被攻击分类模型Target M会预测图片类别,并和真实类别对比生成adversarial loss 以指导均值和方差改变的方向,adversarial loss 在代码中使用的是CW Loss,下面给出图片更改均值和方差的方式
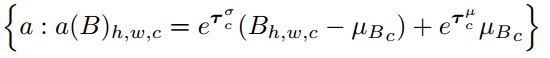
均值和方差都会类似于PGD攻击限制在一定的范围,![]()
![]() 都是超参数可以理解为PGD攻击的步长,B即embedding,hwc分别代表长宽和通道
都是超参数可以理解为PGD攻击的步长,B即embedding,hwc分别代表长宽和通道
4.实验
略
5.核心代码实现
TensorFlow版本
5.1 train decoder
with tf.Graph().as_default(), tf.Session(config=tf_config) as sess:
#[B,32,32,3]
#内容图片
content = tf.placeholder(tf.float32, shape=INPUT_SHAPE, name='content')
#风格迁移图片
style = tf.placeholder(tf.float32, shape=INPUT_SHAPE, name='style')
#标签
label = tf.placeholder(tf.int64, shape =None, name="label")
#style = tf.placeholder(tf.float32, shape=INPUT_SHAPE, name='style')
# create the style transfer net
stn = StyleTransferNet(encoder_path)
# pass content and style to the stn, getting the gen_img
# decoded image from normal one, adversarial image, and input
dec_img, adv_img = stn.transform(content, style)
img = content
get the target feature maps which is the output of AdaIN
target_features = stn.target_features
# pass the gen_img to the encoder, and use the output compute loss
enc_gen_adv, enc_gen_layers_adv = stn.encode(adv_img)
enc_gen, enc_gen_layers = stn.encode(dec_img)
l2_embed = normalize(enc_gen)[0] - normalize(stn.norm_features)[0]
l2_embed = tf.reduce_mean(tf.sqrt(tf.reduce_sum((l2_embed * l2_embed),axis=[1,2,3])))
# compute the content loss
# target_features=content直接经过encoder生成的embedding
#enc_gen_adv=content+styleencoder,然后合并生成embedding,再经过decoder再经过encoder生成的embedding
content_loss = tf.reduce_sum(tf.reduce_mean(
tf.square(enc_gen_adv - target_features), axis=[1, 2]))
modelprep.init_classifier()
build_model = modelprep.build_model
restore_model = modelprep.restore_model
# Get the output from different input, this is a class which define different properties derived from logits
# To use your own model, you can get your own logits from content and pass it to class build_logits in utils.py
adv_output = build_model(adv_img, label, reuse=False)
nat_output = build_model(img, label, reuse=True)
dec_output = build_model(dec_img, label, reuse=True)
style_layer_loss = []
for layer in STYLE_LAYERS:
enc_style_feat = stn.encoded_style_layers[layer]
enc_gen_feat = enc_gen_layers_adv[layer]
meanS, varS = tf.nn.moments(enc_style_feat, [1, 2])
meanG, varG = tf.nn.moments(enc_gen_feat, [1, 2])
sigmaS = tf.sqrt(varS + EPSILON)
sigmaG = tf.sqrt(varG + EPSILON)
l2_mean = tf.reduce_sum(tf.square(meanG - meanS))
l2_sigma = tf.reduce_sum(tf.square(sigmaG - sigmaS))
style_layer_loss.append(l2_mean + l2_sigma)
style_loss = tf.reduce_sum(style_layer_loss)
# compute the total loss
loss = content_loss + style_weight * style_loss 5.2 训练StyleTransferNet
class StyleTransferNet(Base_Style_Transfer):
def transform(self, content, style):
# encode image
enc_c, enc_c_layers = self.encode(content)
enc_s, enc_s_layers = self.encode(style)
self.encoded_content_layers = enc_c_layers
self.encoded_style_layers = enc_s_layers
self.norm_features = enc_c
# pass the encoded images to AdaIN,
with tf.variable_scope("transform"):
target_features, meanS, sigmaS = AdaIN(enc_c, enc_s)
self.set_stat(meanS,sigmaS)
self.target_features = target_features
# decode target features back to image
generated_adv_img = self.decode(target_features)
#一个直接将content转回原图像,一个将content+style合并后的embedding再转为原图像
generated_img = self.decode(enc_c)
return generated_img, generated_adv_img5.3 AdaIN
def AdaIN(content, style, epsilon=1e-5):
#计算embedding每一个通道的均值和方差
meanC, varC = tf.nn.moments(content, [1, 2], keep_dims=True)
meanS, varS = tf.nn.moments(style, [1, 2], keep_dims=True)
sigmaC = tf.sqrt(tf.add(varC, epsilon))
sigmaS = tf.sqrt(tf.add(varS, epsilon))
#保持content的shape的同时,并使用style的均值和方差修改content的embedding
#返回style每一个通道的均值和方差
return (content - meanC) * sigmaS / sigmaC + meanS, meanS, sigmaS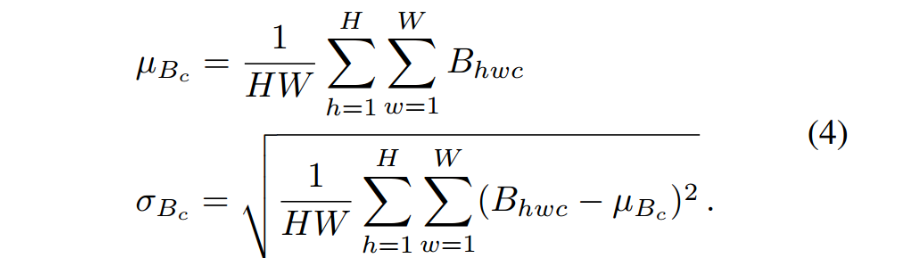
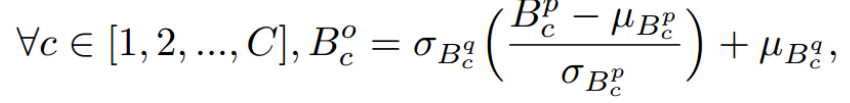
5.4 attack
with tf.Graph().as_default(), tf.Session(config=tf_config) as sess:
content = tf.placeholder(tf.float32, shape=INPUT_SHAPE, name='content')
label = tf.placeholder(tf.int64, shape=None, name="label")
# create the style transfer net
stn = StyleTransferNet_adv(encoder_path)
# pass content and style to the stn, getting the generated_img
#dec_img是原始图片经过encoder再经过decoder生成回原图片
#dav_img是生成图片经过encoder然后修改均值方差生产生干扰再通过decoder变成对抗样本
dec_img, adv_img = stn.transform(content, p=bound)
img = content
stn_vars = get_scope_var("transform")
# get the target feature maps which is the output of AdaIN
target_features = stn.target_features
# pass the generated_img to the encoder, and use the output compute loss
enc_gen_adv, enc_gen_layers_adv = stn.encode(adv_img)
modelprep.init_classifier()
build_model = modelprep.build_model
restore_model = modelprep.restore_model
# Get the output from different input, this is a class which define different properties derived from logits
# To use your own model, you can get your own logits from content and pass it to class build_logits in utils.py
adv_output = build_model(adv_img, label, reuse=False)
nat_output = build_model(img, label, reuse=True)
dec_output = build_model(dec_img, label, reuse=True)
# We are minimizing the loss. Take the negative of the loss
# Use CW loss top5 for imagenet and CW top1 for cifar10.
# Here the target_loss represents CW loss, it is not the loss for targeted attack.
adv_loss = -adv_output.target_loss_auto
# compute the content loss
content_loss_y = tf.reduce_sum(
tf.reduce_mean(tf.square(enc_gen_adv - target_features), axis=[1, 2]),axis=-1)
content_loss = tf.reduce_sum(content_loss_y)
# compute the total loss
loss = content_loss + tf.reduce_sum(adv_loss * BATCH_SIZE * adv_weight)
decoder_vars = get_scope_var("decoder")
# Training step
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.inverse_time_decay(LEARNING_RATE, global_step, DECAY_STEPS, LR_DECAY_RATE)
train_op = gradient(tf.train.AdamOptimizer(learning_rate, beta1= 0.5),vars=stn_vars, loss=loss)
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver(decoder_vars, max_to_keep=1)
saver.restore(sess,Decoder_Model)
restore_model(sess)
###### Start Training ######
step = 05.5 StyleTransferNet_adv
class StyleTransferNet_adv(Base_Style_Transfer):
def transform(self, content, p=1.5):
# encode image
enc_c, enc_c_layers = self.encode(content)
self.encoded_content_layers = enc_c_layers
self.norm_features = enc_c
with tf.variable_scope("transform"):
target_features, self.init_style, self.style_bound, sigmaS, meanS, self.meanC, self.sigmaC, self.init_style_rand, self.normalized \
= AdaIN_adv(enc_c, p=p)
self.set_stat(meanS, sigmaS)
bs = settings.config["BATCH_SIZE"]
self.meanS_ph= tf.placeholder(tf.float32, [bs]+ self.meanS.shape.as_list()[1:])
self.sigmaS_ph = tf.placeholder(
tf.float32, [bs] + self.sigmaS.shape.as_list()[1:])
self.asgn = [tf.assign(self.meanS, self.meanS_ph),
tf.assign(self.sigmaS, self.sigmaS_ph)]
self.target_features = target_features
# decode target features back to image
generated_adv_img = self.decode(target_features)
generated_img = self.decode(enc_c)
return generated_img, generated_adv_img5.6 AdaIN_adv
def AdaIN_adv(content, epsilon=1e-5, p=1.5):
meanC, varC = tf.nn.moments(content, [1, 2], keep_dims=True)
# 获取批处理大小和内容的形状
bs = settings.config["BATCH_SIZE"]
content_shape = content.shape.as_list()
# 创建一个新形状,其中批处理大小被调整为 `bs`,高度和宽度为 1
new_shape = [bs, 1, 1, content_shape[3]]
with tf.variable_scope("scale"):
# 定义 meanS 变量,形状为 new_shape,初始化为全零
meanS = tf.get_variable("mean_S", shape=new_shape,
initializer=tf.zeros_initializer())
# 定义 sigmaS 变量,形状为 new_shape,初始化为全一
sigmaS = tf.get_variable("sigma_S", shape=new_shape,
initializer=tf.ones_initializer())
#epsilon 是一个小的常数,它用于避免方差为零的情况,从而保证计算的稳定性
#tf.add 将方差 varC 和小常数 epsilon 相加
#tf.sqrt() 对相加后的结果进行开方操作,得到标准差 sigmaC
sigmaC = tf.sqrt(tf.add(varC, epsilon))
#p = 1.5,论文中embedding方差和均值的放大系数
p_sigma = p
p_mean = p
"""
tf.clip_by_value() 函数用于将张量中的元素限制在指定的范围内。这里将 sigmaS 和 meanS 限制在一定的范围内。
tf.assign() 函数用于将一个张量的值赋给另一个张量。这里将限制后的值重新赋给 sigmaS 和 meanS。
"""
sign = tf.sign(meanC)
abs_meanC = tf.abs(meanC)
"""等价的pytorch代码如下
ops_bound = [
sigmaS.data.clamp_(sigmaC / p_sigma, sigmaC * p_sigma),
meanS.data.clamp_(abs_meanC / p_mean, abs_meanC * p_mean)]
"""
ops_bound = [tf.assign(sigmaS, tf.clip_by_value(sigmaS, sigmaC/p_sigma, sigmaC*p_sigma)),
tf.assign(meanS, tf.clip_by_value(meanS, abs_meanC/p_mean, abs_meanC*p_mean))]
"""
这段 TensorFlow 代码创建了两个随机张量,sigmaC_rand 和 meanC_rand,它们的值在一定的范围内随机分布
tf.random_uniform() 用于生成指定形状的均匀分布的随机数。
第一个参数是张量的形状,接着是随机数的最小值和最大值。在这里,最小值是 sigmaC/p 或 abs_meanC/p,
最大值是 sigmaC*p 或 abs_meanC*p,即随机数在这个范围内
"""
sigmaC_rand = tf.random_uniform(tf.shape(sigmaC), sigmaC/p, sigmaC*p)
meanC_rand = tf.random_uniform(tf.shape(meanC), abs_meanC/p, abs_meanC*p)
#sigmaS = tf.sqrt(tf.add(varS, epsilon))
ops_asgn = [tf.assign(meanS, abs_meanC), tf.assign(sigmaS, sigmaC)]
ops_asgn_rand = [tf.assign(sigmaS, sigmaC_rand), tf.assign(meanS, meanC_rand)]
return (content - meanC) * sigmaS / sigmaC + sign * meanS, ops_asgn, ops_bound, sigmaS, meanS, meanC, sigmaC, ops_asgn_rand, (content - meanC) / (sigmaC)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









