




 本文深入剖析Linux VFS中dentry缓存机制,探讨dentry结构体及其在目录树中的作用,详细介绍dentry缓存的初始化、并发控制、创建与删除等关键环节。
本文深入剖析Linux VFS中dentry缓存机制,探讨dentry结构体及其在目录树中的作用,详细介绍dentry缓存的初始化、并发控制、创建与删除等关键环节。
1. dentry结构体
dentry是一个目录项(Directory entry),相当于一个文件目录,该文件目录里面有很多文件。其实本质就是一个dir_entry结构体,重要成员有文件的inode索引号,文件名等,存储着文件的信息。
dentry结构体相关信息:
struct ext2_dir_entry_2 {
__u32 inode; /* 文件的inode号 */
__u16 rec_len; /* 目录项长度 */
__u8 name_len; /* 文件名包含的字符数 */
__u8 file_type; /* 文件类型 */
char name[EXT2_NAME_LEN]; /* 文件名 */
};
rec_len代表当前目录项的长度
name_len代表的是文件名的长度
file_type代表文件的文件类型,有以下几种:
enum {
EXT2_FT_UNKNOWN, /*未知*/
EXT2_FT_REG_FILE, /*常规文件*/
EXT2_FT_DIR, /*目录文件*/
EXT2_FT_CHRDEV, /*字符设备文件*/
EXT2_FT_BLKDEV, /*块设备文件*/
EXT2_FT_FIFO, /*命名管道文件*/
EXT2_FT_SOCK, /*套接字文件*/
EXT2_FT_SYMLINK, /*符号连文件*/
EXT2_FT_MAX /*文件类型的最大个数*/
};
2. inode结构体
文件系统对于磁盘中存储的每一个文件都会有一个对应的inode节点,inode节点存储了文件的一些信息,比如:文件类型,文件的权限,文件的创建时间,文件的数据在硬盘中的存储位置等。其实inode节点本质其实是一个结构体,唯一不在inode的信息是文件名和目录,它们存储在目录项dir_dentry中。
inode结构体中有一个非常非常重要的成员i_block,详细信息如下:
struct ext2_inode {
__u16 i_mode; /* 文件的权限 */
__u16 i_uid; /* 文件所有者ID */
__u32 i_size; /* 文件字节数大小 */
__u32 i_atime; /* 文件上次被访问的时间 */
__u32 i_ctime; /* 文件创建时间 */
__u32 i_mtime; /* 文件被修改的时间 */
__u32 i_dtime; /* 文件被删除的时间 */
__u16 i_gid; /* 文件所属组ID */
__u16 i_links_count; /* 此文件的inode被连接的次数 */
__u32 i_blocks; /* Blocks count */
__u32 i_flags; /* File flags */
union {
struct {
__u32 l_i_reserved1;
} linux1;
struct {
__u32 h_i_translator;
} hurd1;
struct {
__u32 m_i_reserved1;
} masix1;
} osd1; /* OS dependent 1 */
__u32 i_block[EXT2_N_BLOCKS];/* 指向存储文件数据的块的数组 */
__u32 i_generation; /* File version (for NFS) */
__u32 i_file_acl; /* File ACL */
__u32 i_dir_acl; /* Directory ACL */
__u32 i_faddr; /* Fragment address */
union {
struct {
__u8 l_i_frag; /* Fragment number */
__u8 l_i_fsize; /* Fragment size */
__u16 i_pad1;
__u16 l_i_uid_high; /* these 2 fields */
__u16 l_i_gid_high; /* were reserved2[0] */
__u32 l_i_reserved2;
} linux2;
struct {
__u8 h_i_frag; /* Fragment number */
__u8 h_i_fsize; /* Fragment size */
__u16 h_i_mode_high;
__u16 h_i_uid_high;
__u16 h_i_gid_high;
__u32 h_i_author;
} hurd2;
struct {
__u8 m_i_frag; /* Fragment number */
__u8 m_i_fsize; /* Fragment size */
__u16 m_pad1;
__u32 m_i_reserved2[2];
} masix2;
} osd2; /* OS dependent 2 */
};
3. 文件索引过程
这里写图片描述
图1-文件索引过程
注意:文件系统对于数据在磁盘中是以block(数据块)形式存储的。
从上图中可以看出文件的大概索引过程,实际的文件索引过程非常复杂的,这里只是简化了一下。现在我们来看一下,当要查找test.txt文件时,会先从dir_entry结构体中找到与文件名相匹配的inode节点,然后再根据test.txt文件的inode编号找到对应的inode结构体,而在inode结构体中会有一个i_block成员(i_block在inode结构体中是一个非常重要的成员),该成员指出了test.txt文件中的数据在磁盘中的存储位置。
————————————————
版权声明:本文为优快云博主「songly_」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/qq_35733751/article/details/80776585
1 背景
dentry是Linux vfs子系统的四大数据结构之一(super_block,inode,dentry,file),负责vfs树形namespace的构建。dentry cache的管理是vfs pathname lookup实现的基石,而pathname lookup是理解整个vfs实现的基石。
一个dentry结构体代表文件系统中的一个目录或文件,vfs使用基于dentry构建的dentry树来管理整个系统的目录树结构。当然,对于大型系统不可能把整个系统的目录树都塞进内存,dentry cache就负责维护系统目录树中最常用的项目,并采用lru的淘汰策略淘汰最近不使用的项目,维持整个dentry cache中项目数量的稳定。
整体概念如下图所示,本文基于Linux 5.10.80代码分析dentry cache模块的具体实现。
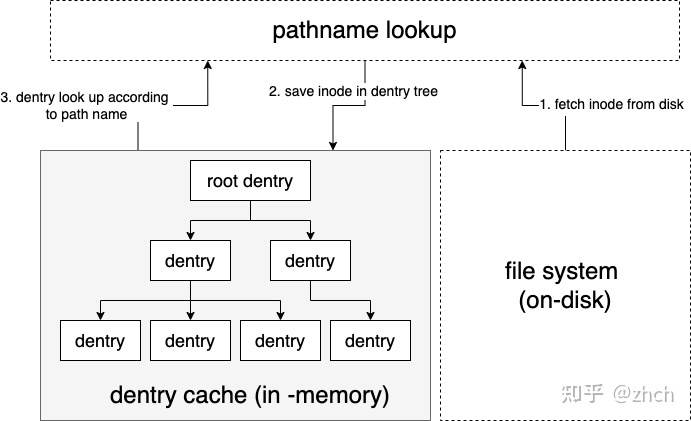
dentry cache
3 dentry cache的初始化
dentry cache在内核启动时完成初始化。内核的启动入口函数是init/main.c文件的start_kernel函数,start_kernel函数会调用vfs_caches_init函数,并调用dcache_init函数来完成dentry cache的初始化。dcache_init函数主要工作内容是两项。
第一项是初始化dentry cache模块的私有变量 struct kmem_cache *dentry_cache,这是一个slab内存分配器。slab内存分配是内核内存管理的常用手段,我们会用专门文章来分析其具体实现,其核心思想非常简单,可以理解为一个对象池,专门应对同一类型,也就是等长内存的频繁分配和释放。dentry cache模块的dentry_cache字段就是专门用来分配struct dentry数据结构所需使用的内存的。
第二项是初始化dentry cache模块的另一个私有变量struct hlist_bl_head *dentry_hashtable,这是一个巨大的哈希表,也就是dentry cache的查找索引,可以dentry的name直接在这个哈希表中进行查找。类型struct hlist_bl_head是一个bit lock hash list的链表头。hash list用于实现哈希表的一个slot,这里的bit lock hash list是一个内核中的hash list实现版本,不需要为每个hash list分配一把锁,只需要使用链表头指针的一个bit来进行访问并发控制,节省内存开销。bit lock hash list的具体实现我们会使用专门文章来分析,本文只分析涉及到的相关用法和语义。dentry_hashtable由一个定长的hlist_bl_head数组组成,相当于是一个永不扩容的哈希表,可以减少并发控制带来的性能开销和实现复杂度。
4 dentry数据结构
一个dentry数据结构代表一个目录或文件,在这里dentry结构体有四个字段:
struct inode *d_inode; struct super_block *d_sb; const struct dentry_operations *d_op; void *d_fsdata;
inode结构体中保存着一个目录或文件的所有元信息,但是没有目录树的树形namespace信息。vfs中负责维护目录树的数据结构就是dentry,通过把inode绑定到dentry来实现目录树的访问和管理。d_sb字段指向dentry所属文件系统的super_block。d_op字段可以接受注册文件系统的dentry操作,d_fsdata可用于注册文件系统专有的数据。
为了构建和维护目录树,dentry数据结构中还包含下列字段:
struct dentry *d_parent; struct list_head d_subdirs; struct list_head d_child; struct qstr d_name; unsigned char d_iname[DNAME_INLINE_LEN];
其中d_parent字段用于指向父亲dentry。d_subdirs是一个链表,用于保存该目录中的所有子目录或者文件。d_child字段用于把子节点的dentry链入父节点的d_subdirs字段。Linux的链表实现不是为每一个节点分配一个管理节点,在这个管理节点中设置前驱指针和后继指针,这样做会增加内存分配的次数,而且每个链表中的节点都需要对应两块零散内存,所以Linux中的链表都是采用把指针字段全部直接inline到需要被加入链表的数据结构中去,来使内存使用更紧凑。这也是一种在很多系统中都很常用的技巧,关于Linux链表的具体实现会在专门文章中进行分析,本文不作展开。d_name字段和d_iname字段用于保存文件名,当文件名比较短时会被保存在d_iname中,并把struct qstr中的指针指向d_iname。
dentry树的访问有两种模式,一种是遍历,另一种是查找。所谓遍历,就是给定一棵目录树子树的根节点,遍历访问它的所有子节点,直到满足退出条件后退出,此时要用到d_subdirs字段。所谓查找就是给定要访问目录或文件的父dentry和它的名字,来直接获取要查找目录或文件的dentry。查找时会用到模块级字段dentry_hashtable,这是一个以目录、文件名作为key的哈希表,是模块级的私有字段,前面已经提到过。和链表类似,链入哈希表的slot链,使用的也是一个inline到dentry数据结构的字段:
struct hlist_bl_node d_hash;
super_block有一个字段是s_dentry_lru链表,用于保存dentry cache需要根据LRU的策略淘汰最近最少使用的dentry,d_lru字段就用于把所有dentry链入LRU链表:
struct list_head d_lru;
vfs支持硬链接的概念,所以对于每一个文件,可以有一条或多条目录树路径与之对应,每一条都称作这个文件的一个alias。在inode数据结构中有一个i_dentry字段是一个链表,用于保存该inode的所有alias。而dentry上就有一个对应字段用于链入inode数据结构的i_dentry链表:
struct hlist_node d_alias;
此外还有两个与dentry树并发控制相关的字段,在下面一个专门章节中具体分析。
seqcount_spinlock_t d_seq; struct lockref d_lockref;(#define d_lock d_lockref.lock)
5 dentry cache模块的并发控制机制
这一节总结dentry cache模块用到的并发控制机制,方便后续分析具体逻辑实现时查阅。
5.1 自旋锁与引用计数
从dentry cache中查询获取到dentry数据结构的指针后,可以被保存在外部模块中并使用,这个过程中dentry cache模块的用户需要持有dentry cache的引用计数,只要dentry数据结构的引用计数不为0,dentry数据结构就不会被释放。
很多场景中,引用计数的修改可以通过原子操作进行,同时还有很多场景,引用计数的修改必须保证和数据结构的一些其他字段修改不会并发进行。例如在对dentry数据结构的d_flags字段进行修改时,往往需要先把d_flags字段读出来,加、减一些标志bit,然后再把整个flag写回去,同时这个过程禁止修改dentry的引用计数。当有这种场景存在时,一种naive的解决方案是,完全放弃使用原子变量对引用计数的修改,所有对数据结构的修改前,包括引用计数修改前都要拿锁。当引用计数修改操作频率比较高时,这种方案会有比较大的性能牺牲。针对此,Linux专门实现了lockref数据结构,来优化这种频繁的引用计数修改,相对较低频率的通过锁来同步数据结构的并发修改场景。
lockref实现在include/linux/lockref.h和lib/lockref.c两个文件中。其核心思想是把一个spinlock_t和一个unsigned int count,打包到一块64位对齐的内存中,如下所示:
struct lockref { union { aligned_u64 lock_count; struct { spinlock_t lock; int count; }; }; };
这样就可以使用原子cas操作,在对引用计数修改时保证没有任何并发内核线程持有对应的自旋锁。dentry cache模块用到的lockref API有下面几个。
5.1.1 lockref_get
void lockref_get(struct lockref *lockref)
- 先读取lockref结构体中的自旋锁值,如果没有加锁,则用cas操作对引用计数加1
- 如果cas成功则操作成功,否则重试
- 重试超过一定次数后进入加锁模式,先加锁自旋锁,再增加引用计数,再解锁自旋锁
5.1.2 lockref_put_or_lock
int lockref_put_or_lock(struct lockref *lockref)
- 先读取lockref结构体的值,如果自旋锁没有加锁,且引用计数大于1,则使用cas操作对引用计数建1
- 若cas操作成功则返回1,否则重试
- 如果重试超过最大次数则进入加锁模式
- 对自旋锁加锁
- 判断引用计数如果大于1,则对引用计数减1,解锁自旋锁,返回1
- 否则保持持有自旋锁不解锁,返回0
5.1.3 lockref_put_return
int lockref_put_return(struct lockref *lockref)
- 读取lockref结构体的值,如果没有加锁,且引用计数大于0,则用cas操作对引用计数减1
- 如果cas成功则返回减1后的引用计数值
- 如果cas失败则重试,超过最大次数还是失败后返回-1
5.1.4 lockref_mark_dead
void lockref_mark_dead(struct lockref *lockref)
标记lockref已释放,不可再使用。
5.2 sequence lock
Linux中的读写锁rwlock是读者优先的,写者可能出现饥饿。如果不希望出现写者饥饿,则可以使用seqlock。seqlock适合读多写少,但是当真的有写操作需要执行时,希望写者获得尽可能快的执行的场景。seqlock的具体实现在include/linux/seqlock.h文件中, 其核心数据结构是seqcount_t,如下所示,本质就是一个sequence number。
typedef struct seqcount { unsigned sequence; } seqcount_t;
seqlock实现的核心思想是,write每次修改共享资源都用原子指令对sequence做加1。读者在进入临界区前先通过原子指令获得sequence,在临界区结束后使用原子指令校验sequence,如果在校验时发现sequence和自己进入临界区前不同,说明在自己执行期间有write修改了共享资源,需要对整个读取逻辑进行重试。同时seqlock要求进入临界区的writer最多只有一个,如果有并发的writer存在,需要用户使用专门的锁来做串行化,或者使用seqcount_t与某一种锁的结合体API来实现,如seqcount_spinlock_t,seqcount_rwlock_t,seqcount_mutex_t等。例如dentry的d_seq就是一把seqcount_spinlock_t。seqlock的核心API有下面几个。
5.2.1 raw_write_seqcount_begin, raw_write_seqcount_end
分别标记对共享资源写操作的开始和结束。这两个函数都会对sequence加1,来向读者提示共享资源可能已经被修改。seqlock要求用户保证同时最多只有一个写者进入临界区,所以不难发现,当有写者在临界区执行时,sequence将会是奇数,写者临界区结束后sequence恢复为偶数。
raw_write_seqcount_begin会调用preempt_disable来关闭抢占,raw_write_seqcount_end则调用preempt_enable重新开启抢占。seqlock的写者在修改共享资源期间需要关抢占的原因是为了避免读者等待过久。
5.2.2 write_seqcount_begin, write_seqcount_end
这一组和raw_write_seqcount_begin, raw_write_seqcount_end类似,差别在于会引入lockdep死锁debug机制,lockdep的实现我们在专门文章中分析。
5.2.3 raw_read_seqcount_begin
开始读取临界区,首先读取sequence,如果是奇数,则在while循环中调用cpu_relax(),并重新判断sequence,直到sequence为偶数。把sequence作为返回值返回。
5.2.4 read_seqcount_t_retry
判断当前sequence是否与raw_read_seqcount_begin返回的相同,相同则返回true,否则返回false。
5.2.5 write_seqcount_t_invalidate
保证所有正在并发执行的reader的读取操作都会失败,在这个API调用之后重新读取,以保证读到的数据最新。实现就是对sequence直接加2.
5.3 RCU
dentry cache还用到rcu来做并发控制,rcu是read-copy-update的简称,也是用于优化部分使用读写锁的场景。使用rcu时,读和写都不需要加锁,可以消除加锁带来的开销提高性能。但是要求对共享资源的修改都使用原子操作进行,且需要用户保证如果存在多此原子操作修改,读者和写者的并发执行不会存在问题。最常见的场景就是用rcu保护对一个共享指针的修改,并可基于此来实现链表、哈希表、树等更复杂的并发数据结构。
rcu的框架中有三种角色,分别是reader,updater和recalimer。reader会读取共享数据,updater会修改共享数据,而recalimer负责对老的无人继续使用的内存和其他资源进行回收。
rcu的具体实现在kernel/rcu目录和文件include/linux/rcupdate.h中,本文只分析与dentry cache实现相关部分API的语义和实现,rcu的完整实现分析留在专门文章中。先来看rcu提供的核心API。
5.3.1 rcu_dereference
dereference的本意是取出指针所指向变量中所存储的值。这个API就是在足够memory barrier保护的前提下读取指针的值,后续用户可以deference这个函数返回的指针来获取需要的值。
5.3.2 rcu_assign_pointer
在足够的memory barrier保护下给给定的指针赋值。不难发现rcu_assign_pointer和rcu_dereference构成了一对对指针并发修改的基础。剩下的问题就是老版的指针所指向的不再使用的内存如何回收。
5.3.3 rcu_read_lock和rcu_read_unlock
标记rcu reader临界区的开始和结束,这两个函数没有任何输入参数也没有任何返回值。实现也非常简单,会在rcu_read_lock中关抢占,再在rcu_read_unlock中开抢占,就这么简单。
这两个函数的名字会有一些误导,这一对read lock和unlock并不是reader在和updater做同步,而是reader在和recalimer做同步。rcu中的reader和updater不需要同步,双方都是通过原子操作+memory barrier对共享数据做更新和读取,而共享数据通常只是一个指针,所以不需要做同步,如果有需要对多个指针做修改的场景,语义实现需要用户保证。
5.3.4 synchronize_rcu
updater在完成所有共享数据的更新后就可以调用synchronize_rcu来启动recalimer角色。到这一步因为所有对共享数据的修改都已经完成,所以至此以后进入读临界区的reader都将读到新的数据。接下去reclaminer需要等待之前已经在执行的reader完成读临界区的所有操作,就可以进行被更新数据的清理了。
synchronize_rcu如何知道老的reader已经全部退出了临界区呢?要知道rcu_read_lock函数可没有任何输入参数!这里rcu实现的核心思想就来了,因为rcu_read_lock的时候会关抢占,等待rcu_read_unlock再重开抢占。所以synchronize_rcu只要等待所有cpu都完成一次上下文切换就可以了。当CPU数量较少时,synchronize_rcu使用cpumask来实现,而当CPU数量特别多时,还有tree rcu来优化性能。具体实现此处从略。
5.3.5 call_rcu
call_rcu是synchronize_rcu的异步版本,不会等待所有已开始reader完成,而是注册一个recalimer回调,在所有reader退出临界区后由进程上下文切换或者softirq负责执行回调。回调函数中不允许发生阻塞。
6 创建dentry
6.1 关于negative dentry
在dentry cache中不但会保存最近最常使用的目录/文件的相关项目,还会保存最近查询过的,不存在的目录或文件。在dentry cache中查询某个pathname对应的目录/文件如果不存在,这是一次cache miss,需要继续调用对应path具体文件系统的实现,来查询这个path到底是否存在,这个过程中可能访问磁盘,是一个慢速过程。而negative dentry,就是把频繁访问的不存在的pathname也在dentry树中记录下来,那么当查询到这个negative dentry时,我们就可以立即直到这个路径不存在,向用户返回,避免可能的磁盘访问。
而所谓negative dentry,就是没有inode与之绑定的dentry,本节具体分析dentry的创建、初始化与inode绑定等逻辑的实现。
6.2 d_alloc
dentry创建的入口函数是d_alloc,具体的函数签名如下:
struct dentry *d_alloc(struct dentry * parent, const struct qstr *name)
输入一个父dentry和要创建的dentry的name,完成一个dentry的创建。主体工作流程如下:
- 调用__d_alloc函数,从slab dentry_cache中分配一个dentry结构体所需的内存
- 如果参数name的长度比较短,小于DNAME_INLINE_LEN-1,则把name保存在dentry的d_iname字段中,d_name字段指向d_iname字段。否则调用kmalloc,为d_name字段分配内存,并把name保存进去
- 初始化dentry的其他各个字段,其中比较重要的几个是:设置引用计数d_lockref.count为1;d_flags为0;d_inode为NULL
- 把parent的super_block中的dentry_operations保存到d_op字段
- 调用dentry_operations.d_init函数,对dentry进一步进行具体文件系统相关的初始化
- 加锁父dentry的自旋锁d_lockref.lock
- 调用__dget_dlock对父dentry引用计数加1
- 把dentry的d_parent字段设置为参数parent
- 把子dentry,通过d_child作为连接键,加入到父dentry的d_subdirs中
- 解锁父dentry的自旋锁d_lockref.lock
6.3 d_alloc_anon
d_alloc_anon用于单纯分配一个dentry结构体,并不设置parent和name的相关状态。
6.4 d_instantiate
d_instantiate函数负责把一个给定的inode绑定到给定的dentry,函数签名如下:
void d_instantiate(struct dentry *entry, struct inode * inode)
工作流程如下:
- 加锁inode的i_lock自旋锁
- 调用__d_instantiate,开始执行具体的绑定操作
- 调用d_flags_for_inode函数,根据inode的信息生成dentry上需要设置的相应flags
- 加锁dentry的d_lockref.lock自旋锁
- 以dentry的d_u.d_alias字段作为连接键,把dentry加入inode的i_dentry hash list
- 调用raw_write_seqcount_begin,通过dentry的d_seq seqlock标记dentry的d_flags和d_inode字段将发生修改
- 调用__d_set_inode_and_type函数,设置dentry的d_inode字段为参数inode,把d_flags_for_inode返回的flags OR到dentry的d_flags字段
- 调用raw_write_seqcount_end
- fsnotify_update_flags(dentry);
- 解锁dentry的d_lockref.lock自旋锁
- 解锁inode的i_lock自旋锁
6.5 d_make_root
d_make_root函数用于在mount一个文件系统的时候,为文件系统的root inode创建对应的dentry。函数签名为:
struct dentry *d_make_root(struct inode *root_inode)
工作流程为:
- 调用d_alloc_anon创建一个空的dentry
- 调用d_instantiate把参数root_inode绑定到新创建的dentry
7 dentry的引用计数
所有open的目录/文件其对应的dentry的引用计数都大于0,每次close一个目录/文件时都会对其dentry引用计数减1。还有vfs中的其他一些模块和具体文件系统实现的过程中,也可能会用到dentry的引用计数。实现dentry的引用计数需要用到lockref类型的d_lockref字段,并提供下列引用计数相关API。
7.1 d_count
unsigned d_count(const struct dentry *dentry)
查询dentry当前的引用计数,直接返回dentry的d_lockref.count字段。
7.2 dget_dlock
struct dentry *dget_dlock(struct dentry *dentry)
在持有d_lockref.lock自旋锁的前提下,对dentry的引用计数加1,直接执行d_lockref.count字段的加加操作。
7.3 dget
struct dentry *dget(struct dentry *dentry)
调用lockref_get,对dentry引用计数进行加1.
7.4 lru list的管理
引用计数大于0的dentry称作in-used dentry,当dentry的引用计数减为0,此时所有用户执行的open操作都已经close,dentry成为一个unused dentry。unused dentry首先会进入super_block的lru list,等待被复用或者释放。
每个super_block有一个s_dentry_lru字段,是用于保存所有unused dentry的lru list,dentry使用d_lru字段链入这个lru list。提供API d_lru_add和d_lru_del,分别用于把一个dentry加入或者摘下其super_block的lru list。
被加入lru list的dentry的d_flags字段会被打上DCACHE_LRU_LIST标记。
7.5 dput
void dput(struct dentry *dentry)
释放对dentry的引用计数(引用计数减1)。主体工作流程如下:
- 调用rcu_read_lock,进入rcu reader临界区
- 调用fast_dput,这一步将先用无锁快速路径减引用计数,如果引用计数大于0则成功,否则则进入慢速路径,具体实现见下面
- 如果执行成功则调用rcu_read_unlock,离开rcu reader临界区,并返回
- 如果执行失败,先调用rcu_read_unlock,离开rcu reader临界区
- 调用retain_dentry如果执行成功,说明继续保留dentry,后续复用。则解锁dentry的d_lock自旋锁,并返回
- 否则调用dentry_kill,完成dentry释放
7.6 fast_dput
bool fast_dput(struct dentry *dentry)
fast_dput是dentry减引用的快速路径,会试图使用原子操作对引用计数减1,如果引用计数大于0则成功,否则需要进入加锁逻辑。具体实现如下:
- 如果dentry的d_flags字段包含DCACHE_OP_DELETE标志位,说明dentry所属的文件系统注册了d_op->d_delete()操作,不能在vfs层直接释放dentry,也就是如果当引用计数减到0时不能使用无锁的快速路径
- 此时,调用lockref_put_or_lock,如果dentry的引用计数仍然大于0,则没问题执行成功,如果引用计数已经减到0,则此处会加锁dentry的d_lock自选锁,并返回false
- 否则,也就是文件系统没有注册d_op->d_delete()操作,则当引用计数减到0时可以试图使用无锁快速路径完成dentry释放,下面开始执行:
- 调用lockref_put_return,试图使用原子操作对引用计数减1
- 如果减引用计数后,引用计数仍然大于0,则执行成功返回
- 如果减引用计数失败,说明有其他内核线程持有了dentry的自旋锁,fall back到加锁模式:
- 加锁dentry的自旋锁,如果引用计数大于1,则对引用计数减1并释放自旋锁,返回true
- 否则,持有自旋锁不释放,返回false
- 执行到这一步,已经原子减引用计数成功,并且引用计数减到了0:
- 如果dentry还在dentry cache哈希表上,且没有注册delete操作,且已经在lru list上,那么什么都不用做,直接返回
- 加锁dentry的自旋锁,如果此时引用计数又被加上去了,大于0,则释放自旋锁,直接返回true
- 否则,引用计数真的减到了0,而且我们已经持有了自旋锁,则继续保持持有锁,且返回false
8 删除dentry
8.1 d_drop
d_drop会把dentry从dentry树中摘除,之后将无法在dentry树中找到这个目录或文件。后续如果用户执行了父目录下对应name的查找,那么需要从对应的文件系统中查找inode是否存在,来判定该目录/文件是否存在。具体签名如下:
void d_drop(struct dentry *dentry)
主体工作流程如下:
- 加锁dentry的d_lockref.lock自旋锁
- 依次调用__d_drop和___d_drop,执行具体的drop操作
- 如果给定的dentry是某个文件系统的根dentry,那么需要将其从super_block的s_roots bit lock hash list中摘除,否则需要从dentry_hashtable摘除。摘除过程中需要调用hlist_bl_lock锁住对应的bit lock hash list
- 完成摘除后调用write_seqcount_invalidate,invalidate dentry的d_seq seqlock
- 解锁dentry的d_lockref.lock自旋锁
8.2 d_delete
d_delete会把dentry标记为negative,也就是明确的在dentry cache中标记该目录/文件不存在,那么后续如果用户执行了父目录下对应name的查找,在dentry cache中命中negative dentry就可以直接给用户返回该目录/文件不存在。具体签名如下:
void d_delete(struct dentry * dentry)
主体工作流程如下:
- 加锁inode的i_lock自旋锁
- 加锁dentry的d_lock自旋锁
- 如果引用计数为1,则说明已经没有其他人在使用该dentry,调用dentry_unlink_inode把dentry转化为negative dentry
- 如果引用计数不为1,调用__d_drop,只做dentry的drop,再后续dput时再触发转成negative dentry
8.3 dentry_kill
drop和delete分别是把dentry从dentry树中移除或者转化为negative dentry,都不会做dentry物理的释放,dentry的物理释放由dentry_kill实现。
9 dentry的查找和遍历
dentry的查找时指给定dentry的父节点和dentry的name,查找对应目录/文件的dentry。dentry的遍历是指给定dentry节点,遍历它的所有子节点。注意,dentry的遍历只有在dentry cache维护的相关路径上才会调用,所以如果一个目录/文件在磁盘上存在,在dentry cache中不存在,遍历的时候不会访问到也不存在目录树管理正确性的问题。
9.1 d_lookup
d_lookup实现了在parent中查找给定name的子目录/文件,具体签名如下:
struct dentry *d_lookup(const struct dentry *parent, const struct qstr *name)
主要工作流程如下:
- 执行seq=read_seqbegin(&rename_lock)
- 调用__d_lookup执行具体查找流程:
- 调用d_hash,找到name对应的dentry_hashtable中的hash list
- 调用rcu_read_lock,进入rcu reader临界区
- 调用hlist_bl_for_each_entry_rcu,使用rcu的方式遍历hash list,对于hash list中的每一个dentry:
- 判断dentry的d_name.hash字段是否等于要查找的name hash
- 加锁dentry的d_lock自旋锁
- 判断dentry的d_parent是否等于参数parent
- 调用d_unhashed,判断dentry是否已经被从dentry cache中移除
- 调用d_same_name,判断dentry的name是否和要查找的name相同
- 如果上述判断全部通过,那么已经找到了要找的dentry,对其引用计数d_lockref.count做加1
- 解锁dentry的d_lock自旋锁
- 调用rcu_read_unlock,退出rcu reader临界区
- 调用read_seqretry(&rename_lock, seq)判断查找过程中,是否发生了rename,如果发生了,则查找结果无效,返回步骤2重新查找,如果没发生则返回查找结果
9.2 d_walk
d_walk函数实现了dentry子树的遍历,具体签名如下:
void d_walk( struct dentry *parent, void *data, enum d_walk_ret (*enter)(void *, struct dentry *) )
其中,parent参数是要遍历的dentry子树的根节点。enter参数是遍历过程中执行处理的回调函数。data参数是传给enter函数的参数。
d_walk执行的是深度优先遍历,主要流程如下:
- 执行read_seqbegin_or_lock(&rename_lock, &seq)
- 首先从传入的参数parent开始遍历,先加锁d_lock自旋锁
- 调用enter函数处理该dentry的遍历回调
- 如果当前dentry的d_subdirs字段不为空,则开始遍往深度探索
- 解锁当前dentry的d_lock自旋锁
- spin_release(&dentry->d_lock.dep_map, _RET_IP_);
- spin_acquire(&this_parent->d_lock.dep_map, 0, 1, _RET_IP_);
- 回到步骤3
- 到此找到了遍历子树的最深,最左节点,开始遍历其d_subdirs字段,并依次进行如下操作:
- 加锁dentry的d_lock自旋锁
- 调用enter回调处理
- 解锁dentry的d_lock自旋锁
- 到此遍历完了深层次子树,开始返回上一层
- 先解锁子节点的d_lock自旋锁,再加锁父节点的d_lock自选锁,这里因为是先解锁子节点再加锁父节点,从始至终保证了再dentry树中自上而下加锁的顺序,所以不会造成死锁
- need_seqretry(&rename_lock, seq),如果发现过程中执行了rename,则释放所有锁,返回步骤1,重跑所有节点的遍历
- 如果过程中没有执行rename,则获取当前dentry的第一个兄弟节点,并返回步骤3继续遍历
9.3 d_ancestor
struct dentry *d_ancestor(struct dentry *p1, struct dentry *p2)
如果p1是p2的祖先,则找到p1通往p2的子节点,如果p1不是p2的祖先,则返回NULL。
10 dentry cache的维护
10.1 d_rehash
d_rehash重新计算dentry的哈希值,并将其加入对应的hash list,函数签名如下:
void d_rehash(struct dentry * entry)
主体工作流程如下:
- 加锁dentry的d_lock自旋锁
- 调用__d_rehash,执行具体的加入hash list操作:
- 根据name计算dentry的哈希值,并找到对应的hash list
- 加锁hash list
- 把dentry加入hash list
- 解锁hash list
- 解锁dentry的d_lock自旋锁
10.2 d_add
d_add负责把给定的dentry和inode绑定,并加入hash list。
10.3 shrink_dcache_sb
释放某个文件系统的所有unused dentry。
void shrink_dcache_sb(struct super_block *sb)
- 遍历super_block的s_dentry_lru list,把其中的dentry全部加入dispose list
- 调用shrink_dentry_list,释放dispose list中的所有dentry
- 如果super_block的s_dentry_lru list还不为空,则返回步骤1继续释放
10.4 shrink_dcache_parent
void shrink_dcache_parent(struct dentry *parent)
- 调用d_walk,遍历以参数parent作为根节点的dentry子树,对于每一节点,如果其引用计数为0就将其加入dispose list
- 不用遍历所有子节点,找到几个可以shrink的节点就可以返回,下次继续遍历
- 如果遍历得到的dispose list不为空则调用shrink_dentry_list,把dispose list上的所有dentry调用dentry_kill进行释放
11 小结
- vfs中inode结构保存了目录/文件的元信息,但是没有目录树的结构,目录树的管理就是靠的vfs另一核心数据结构dentry
- 一个系统的目录树不可能全部塞入内存,所以dentry不光要维护这样一个树形的结构,还要在优先的内存中只存储最频繁使用的目录项,淘汰较少使用的目录项,这就是所谓dentry cache模块所要完成的工作
- dentry cache整体维护了一个很大的哈希表,所有dentry都按照name哈希装入这个哈希表。包括不同目录下的同名子目录/文件,此时当然是哈希冲突的,没关系在查找哈希表后再判断dentry的parent字段是否符合查找的parent,以及最终使用具体文件系统注册的dentry比较函数来判定两个dentry是否相等
- 所有被用户通过open使用的dentry都会维护引用计数,引用计数降为0的dentry称作unused dentry,会被加入super_block的list,可以按文件系统的粒度释放所有unused dentry或者是遍历某个子目录释放所有unused dentry
- 不存在的目录/文件也会被保存在dentry cache中,称作negative dentry,这样查找某个目录/文件不存在可以在不访问磁盘的情况下直接返回,提高性能

















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









