 提升标签精度:低秩表示引导样本相关性预测
提升标签精度:低秩表示引导样本相关性预测




Label Enhancement with Sample Correlations via Low-Rank Representation 论文分享
method
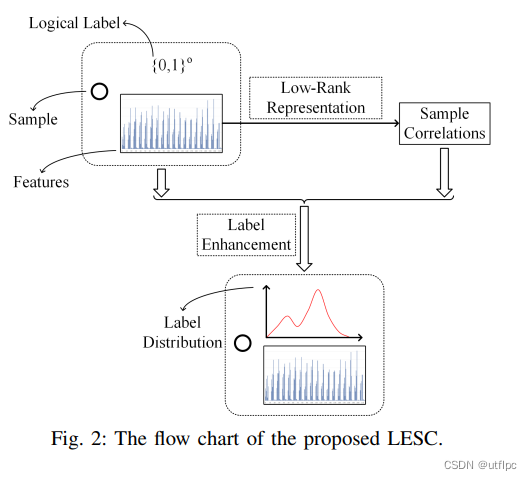
采用低秩表示方法(low-rank representation)来捕获样本的全局关系并预测隐式标签相关性以实现标签增强。
motivation
- 基于部分的每个实例的图构建过程中仅利用了局部拓扑特征,而特征空间的整体信息还没有得到很大的利用。
- 方法需要超参数的先验知识
期望一种全局挖掘整个特征空间的全局结构并对参数具有鲁棒性的方法
具体做法
low-rank representation(LRR)对数据子空间表示施加低秩约束以捕获所有实例的全局关系。
构建的低秩结构通常可以平滑地转移到标签空间,所以利用特征空间的最低秩表示来表示标签分布的LRR。
将获得的 LRR 合并到目标函数中,以探索标签分布空间中的隐藏线索。
notations
| X = [ x 1 ; x 2 ; . . . x n ] X= [\mathcal{x}_1;x_2;...x_n] X=[x1;x2;...xn] | feature matrix |
|---|---|
| Γ = [ L 1 ; L 2 ; . . . L n ] \Gamma=[L_1;L_2;...L_n] Γ=[L1;L2;...Ln] | logical label matrix |
| D = [ D 1 ; D 2 ; . . . D n ] \mathfrak{D}=[D_1;D_2;...D_n] D=[D1;D2;...Dn] | label distribution matrix |
mapping model
对于实例
x
i
x_i
xi,其标签分布为
D
i
=
ϕ
(
θ
^
,
ξ
(
x
i
)
)
.
D_i=\phi(\hat{\theta},\xi(x_i)).
Di=ϕ(θ^,ξ(xi)).
ϕ
(
θ
^
,
⋅
)
\phi(\hat{\theta},\cdotp)
ϕ(θ^,⋅)表示由
θ
^
\hat{\theta}
θ^ 参数化的线性变换.
ξ
(
x
i
)
\xi(x_i)
ξ(xi)表示高斯核函数将
x
i
x_i
xi(也就是特征)映射到高维空间中
θ ^ \hat{\theta} θ^的最优化
min
θ
^
L
(
θ
^
)
+
λ
1
Ψ
(
θ
^
)
\min\limits_{\hat{\theta}}\mathcal{L}(\hat{\theta})+\lambda_1\Psi(\hat{\theta})
θ^minL(θ^)+λ1Ψ(θ^)
L
(
θ
^
)
\mathcal{L}(\hat{\theta})
L(θ^)代表损失函数
Ψ
(
θ
^
)
\Psi(\hat{\theta})
Ψ(θ^)是挖掘原始特征空间中信息和标签之间的相关性的函数
损失函数
The least-squares (LS) loss function:
L
(
θ
^
)
=
∑
i
=
1
n
∥
ϕ
(
θ
^
,
ξ
(
x
i
)
)
−
L
i
∥
\mathcal{L}(\hat{\theta})=\sum_{i=1}^n\Big\lVert\phi(\hat{\theta},\xi(x_i))-L_i\Big\rVert
L(θ^)=i=1∑n∥∥∥ϕ(θ^,ξ(xi))−Li∥∥∥
挖掘函数
在LRR中,所有样本及其全局关系都由少量数据的线性组合表示,在一般情况下,该属性可以转移到标签空间。
因此,可以得到标签分布
D
\mathfrak{D}
D的低秩恢复,即找到一个合适的
D
\mathfrak{D}
D,使
D
\mathfrak{D}
D与
D
C
^
\mathfrak{D}\hat{C}
DC^的距离最小,其中
C
^
\hat{C}
C^是特征空间的最小LRR。
Ψ
(
θ
^
)
=
∥
D
−
D
C
^
∥
F
2
=
∥
(
I
−
C
^
T
)
D
T
∥
F
2
\Psi(\hat{\theta})=\Big\lVert\mathfrak{D}-\mathfrak{D}\hat{C}\Big\rVert_F^2=\Big\lVert(I-\hat{C}^T)\mathfrak{D}^T\Big\rVert_F^2
Ψ(θ^)=∥∥∥D−DC^∥∥∥F2=∥∥∥(I−C^T)DT∥∥∥F2
C ^ \hat{C} C^的最优化
在特征矩阵中寻找LRR来挖掘特征空间的全局结构,即假设
X
=
X
C
+
E
X = XC + E
X=XC+E,然后解决以下正则化秩最小化问题:
min
C
,
E
r
a
n
k
(
C
)
+
λ
2
∥
E
∥
l
,
s
.
t
.
,
X
=
X
C
+
E
\min\limits_{C,E}rank(C)+\lambda_2\lVert E\rVert_l,s.t.,X=XC+E
C,Eminrank(C)+λ2∥E∥l,s.t.,X=XC+E
E
E
E是 the sample-specific corruptions.
为计算方便,秩函数用核范数代替:
min
C
,
E
∥
C
∥
∗
+
λ
2
∥
E
∥
2
,
1
,
s
.
t
.
,
X
=
X
C
+
E
\min\limits_{C,E}\lVert C\rVert_*+\lambda_2\lVert E\rVert_{2,1},s.t.,X=XC+E
C,Emin∥C∥∗+λ2∥E∥2,1,s.t.,X=XC+E
目标函数
P ( θ ^ ) = ∑ i = 1 n ∥ ϕ ( θ ^ , ξ ( x i ) ) − L i ∥ + λ 1 ∥ ( I − C ^ T ) D T ∥ F 2 = t r [ ( ϕ ( θ ^ , Ξ ) , − Γ ) T ( ϕ ( θ ^ , Ξ ) , − Γ ) ] + λ 1 t r ( D ( I − C ^ ) ( I − C T ^ ) D T ) ) P\Big(\hat{\theta}\Big)=\sum_{i=1}^n\Big\lVert\phi(\hat{\theta},\xi(x_i))-L_i\Big\rVert+\lambda_1\Big\lVert(I-\hat{C}^T)\mathfrak{D}^T\Big\rVert_F^2 \\ =tr\Big[\Big(\phi\Big(\hat{\theta},\Xi),-\Gamma\Big)^T(\phi\Big(\hat{\theta},\Xi\Big),-\Gamma\Big)\Big]\\ +\lambda_1tr\Big(\mathfrak{D}\Big(I-\hat{C}\Big)\Big(I-\hat{C^T}\Big)\mathfrak{D}^T\Big)\Big) P(θ^)=i=1∑n∥∥∥ϕ(θ^,ξ(xi))−Li∥∥∥+λ1∥∥∥(I−C^T)DT∥∥∥F2=tr[(ϕ(θ^,Ξ),−Γ)T(ϕ(θ^,Ξ),−Γ)]+λ1tr(D(I−C^)(I−CT^)DT))
Ξ = [ ξ ( x 1 ) , . . . , ξ ( x n ) ] . \Xi=[\xi(x_1),...,\xi(x_n)]. Ξ=[ξ(x1),...,ξ(xn)].

















 68
68

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









