 深度学习基础:反向传播与回归模型在宝可梦战斗力预测中的应用
深度学习基础:反向传播与回归模型在宝可梦战斗力预测中的应用




 文章介绍了反向传播算法在解决大规模参数优化中的作用,通过宝可梦进化后CP值的预测案例探讨了回归问题,使用线性模型和梯度下降进行训练,并讨论了模型复杂度与测试集性能的关系。此外,文章还涉及了识别问题,以及如何利用概率模型和生成模型进行数据建模。最后,提到了正则化在防止过拟合中的重要性。
文章介绍了反向传播算法在解决大规模参数优化中的作用,通过宝可梦进化后CP值的预测案例探讨了回归问题,使用线性模型和梯度下降进行训练,并讨论了模型复杂度与测试集性能的关系。此外,文章还涉及了识别问题,以及如何利用概率模型和生成模型进行数据建模。最后,提到了正则化在防止过拟合中的重要性。
摘要
首先通过梯度下降算法中遇到的问题从而引出反向传播的概念以及反向传播所应用的链式法则。接着通过宝可梦进化后的战斗力案例来分析regression回归模型,最后通过数学中的概率模型引出generative model生成模型的概念。
反向传播(Backpropagation)
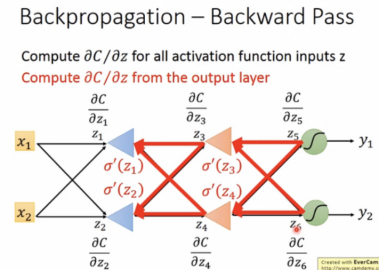
在gradient descent算法中,θ={w1,w2,…},当有million of parameters时,为了使算法更有效率,使用BP(反向传播)算法。
学习BP前,首先需要知道chain rule(链式法则)。
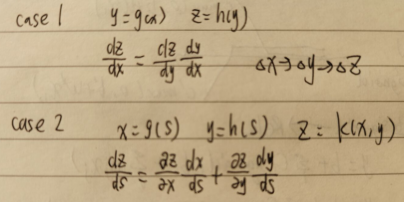
计算loss函数:
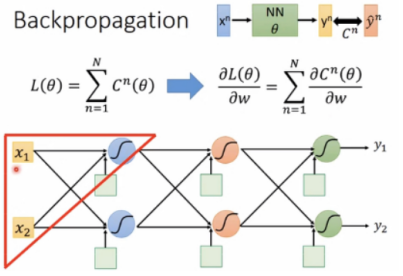
此时分别计算forward pass(前向模式)和backwardpass(后向模式):
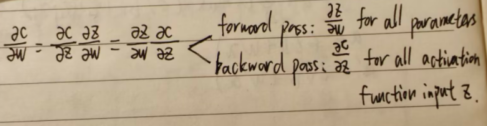
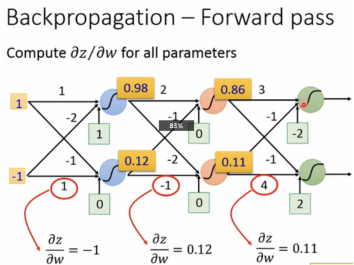
forward pass容易理解,如下图所示:
backward pass求起来相对复杂一些,具体推算过程如下:
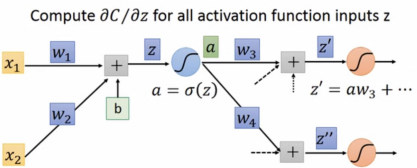
图中此时z=x1w1+x2w2+b,

The value of the input connected by the weight.

以上是正向求解backward pass的过程,接下来使用反向思维简化求解,从后往前求解各微分,这才是真正意义上的反向传播:
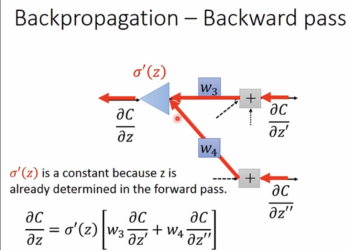
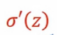 实则是一个常数。
实则是一个常数。
Regression(回归问题):Case Study
Regression,用回归对一些问题进行预测,例如预测股票、预测PM 2.5等等。
例子:预测宝可梦进化后的cp值(combat power战斗力)。
对函数进行猜测:
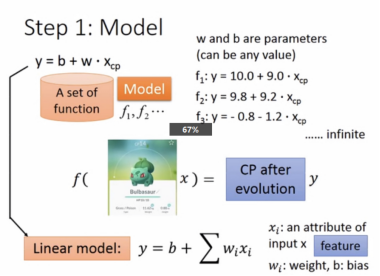
f(Xcp)=CP after evolution (y) (进化后的战斗力)
还有Xs,Xhp,Xw,Xh等等parameters。
Step 1:Model
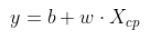 是一个linear model
是一个linear model
注:Linear Model:
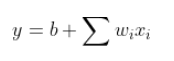 xi: feature wi:weight b:bias
xi: feature wi:weight b:bias
Step 2:
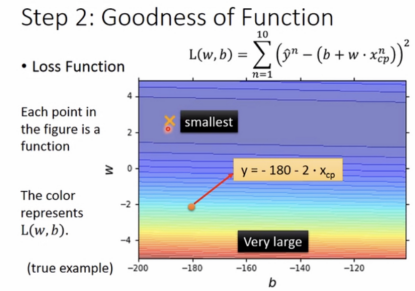
(1)Goodness of Function
Loss function L:
Input: a function output:how bad it is
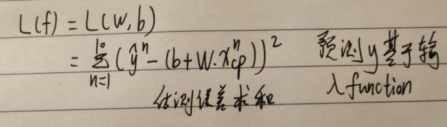
training data共有十个宝可梦的数据,故n=10.
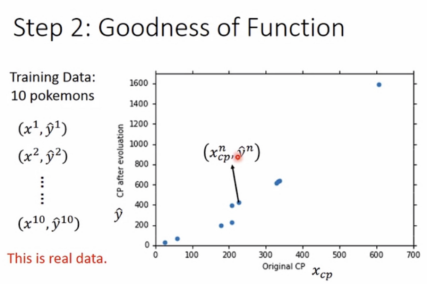
(2)Best Function

Step 3:梯度下降。
操作步骤第二次周报已写过。
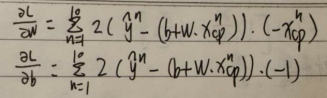
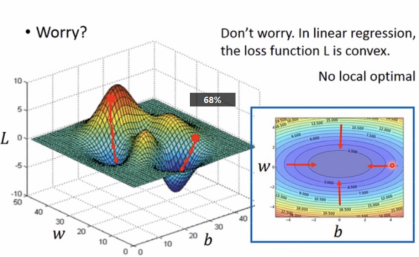
注:不必担心出现local optional(局部最优解),因为线性回归模型,损失函数是凸的。
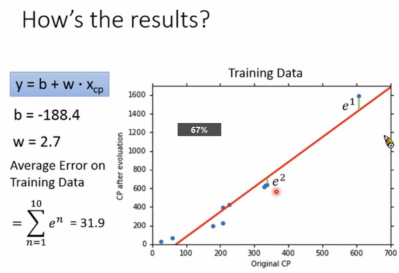
宝可梦战力实际测试结果:
训练集:
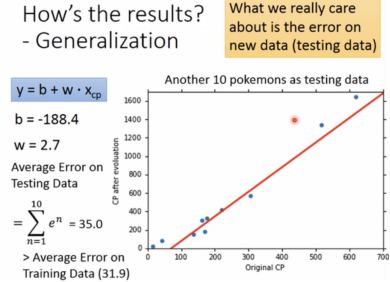
测试集:
可以进一步优化模型,使模型更加复杂(增加最高项的次数,使函数变为曲线)。
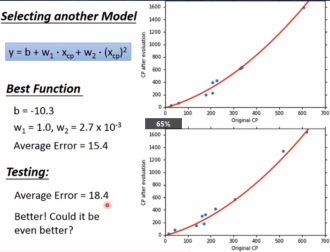
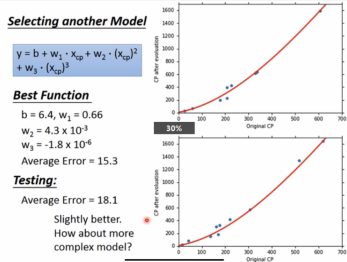
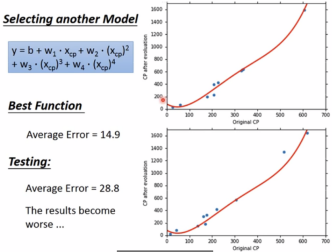
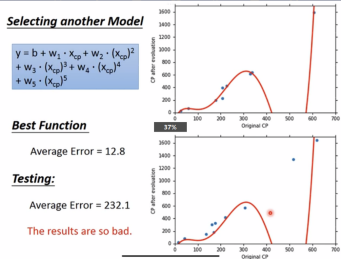
不同模型总结:

模型越复杂,训练集的确会表现更好,但实际测试集并不一定会更好。就像生活中有的人考驾照时模拟的时候做得好,不代表实际在考场上也能表现好,因为还会受到其他很多因素的影响。
收集更多的数据,扩大训练集合,会发现还有其他的隐藏因素影响宝可梦进化后的CP值。
比如物种。此时返回第一步重新构建模型。
Back to step 1:Redesign the Model

得到新模型的实际测试集合表现更好,如下图所示:
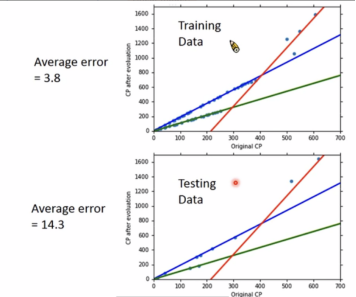
Back to step 2:Regularization(正则化)
通过正则化对目标函数添加一个参数范数惩罚,限制模型的学习能力,可以使得曲线变得光滑平整,调节模型的拟合程度与模型的复杂程度。

宝可梦预测战力总结:
即进化后的CP与初始CP和物种有关。
Classification(识别)
Example Application
使用total,hp,attack,defense,sp atk,sp def,speed等七围属性来识别宝可梦的种类。
How to do Classification:
training data for classification
如果把classification当作regression,
以binary 识别为例,
Training: class 1 means the target is 1
class 2 means the target is -1
Testing: 更接近1即为class 1,更接近-1即为class 2
分析:如果出现远大于1的点,会出现error。
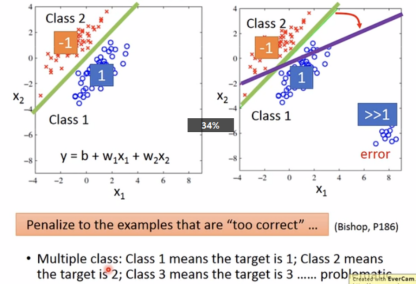
Ideal Alternatives

在进行下一步之前,需要先研究数学中的概率模型:

在有了数学概率模型的基础上,创建generative model(概率生成模型,简称生成模型):
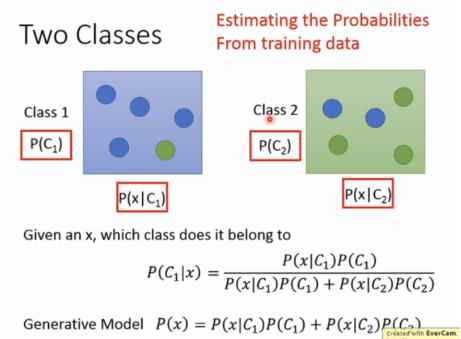
从训练集的数据中预估测试集的可能性。
总结
本周学习了反向传播、回归模型,以及概率模型的部分内容,通过预测宝可梦战斗力的案例进一步加深了对regression的理解,同时也加深了对machine learning的理解,下周将继续研究识别宝可梦种类的案例,进一步掌握概率生成模型。

















 1550
1550



 到【灌水乐园】发言
到【灌水乐园】发言








