



文章目录
摘要
通过使用activation function激活函数对模型进行改写,从而推导出更多更复杂的新模型。新推导出的模型仍然使用gradient descent算法寻找最优解。同时,在推导更复杂新模型的过程中,进一步提出深度学习的概念,即many layers means Deep。
一.第一种new model
Sigmoid函数常被用作神经网络的激活函数,将变量映射到0,1之间。
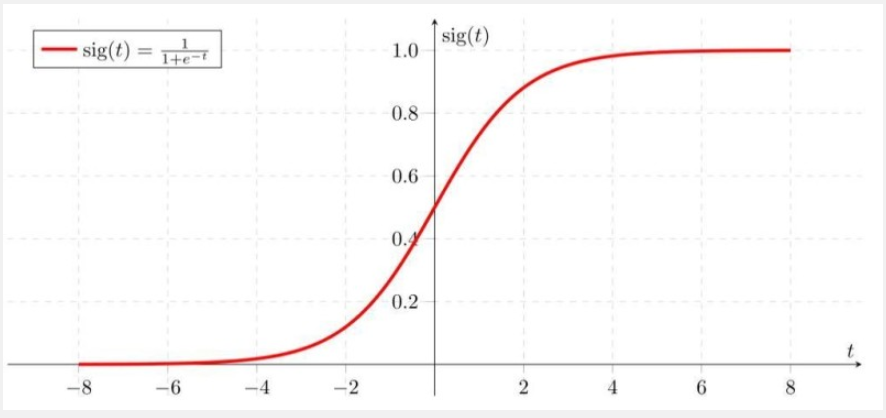
在有了sigmoid function的基础上,可以将进行如下的变换,改写y=b+wx1后得到新function:
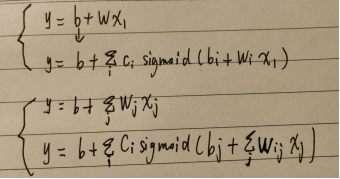
此时,设i,j分别取值1,2,3。
1.新的function with unknown parameters:
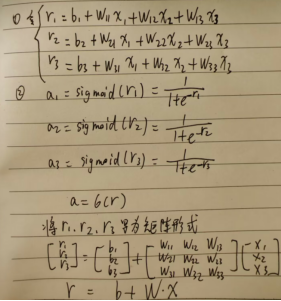

2.find loss function:
Loss是关于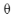 的函数, 用以评估参数的好坏。
的函数, 用以评估参数的好坏。
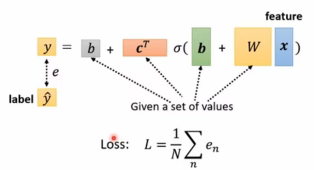
3.optimization of New Model
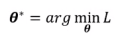
寻找最佳的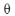 值,使得loss最小。
值,使得loss最小。
首先随机选择一个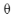 0的初始值。
0的初始值。
然后开始求梯度g和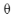 1:
1:

在第一步中可以对a再次求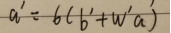 ,还可以多次叠加a。具体做几次也是hyperparameter,做得越多,层数越多,深度也会越深。
,还可以多次叠加a。具体做几次也是hyperparameter,做得越多,层数越多,深度也会越深。
二.第二种new model
不使用sigmoid函数,使用relu线性整数函数。

sigmoid与relu都是activation function(激活函数),还有其他的激活函数。
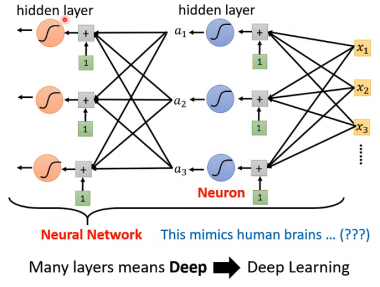
众多的neural组成neutral network(神经网络)。
神经网络有以下三个层次组成:输入层(input layer), 隐藏层 (hidden layers), 输出层 (output layers)。
如今更多使用hidden layer(隐藏层)的叫法,many layers means Deep,即层越多,深度越深。
层数并非越深越好,可能会出现overfitting问题,即better on training data,worse on
unseen data。
三、深度学习
1.深度学习的诞生:

2.深度学习的一些术语:
CNN:深度神经网络,它将卷积结构放在神经网络中,可以很好的对图像进行处理。
RNN:循环神经网络,通常处理序列化的数据,如音频,视频等。
3.深度学习的关键步骤:
深度学习是属于机器学习的分支,故关键步骤与机器学习接近。
step1:define a set of function(neural network)
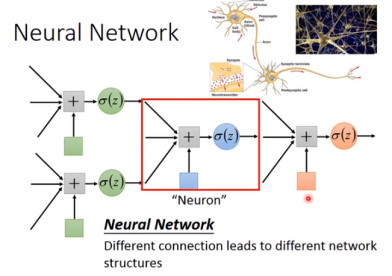
例如:fully connected feetforward network(全连接前馈网络)
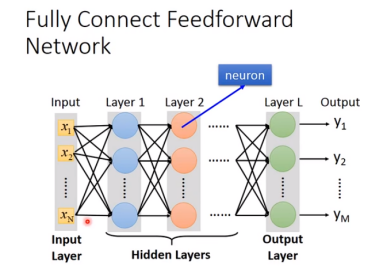
step2:goodness of function
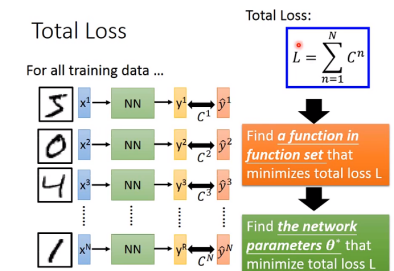
step3:pick the best function
step2和step3仍然使用gradient descent梯度下降算法找最优解。
以上就是learning的过程,即使是阿尔法狗,也是采用这种方式。
总结
在对新模型的推导过程使用了线性代数中矩阵相关内容以及高数中的求导、微分等知识,进一步让我体会到数学对于机器学习的重要性,在学习机器学习的同时,可以利用业余时间复习巩固或是新学习一些数学知识。深度学习的层数也并非越深越好,还需要考虑到overfitting的问题,有时候层数多了,深度深了,只是training data变好,然而预测数据变得更差了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









