








 该专栏为热销专栏榜 第32名
该专栏为热销专栏榜 第32名 超级会员免费看
超级会员免费看


本文将介绍构建推理模型的主要四种方法,或如何增强LLMs的推理能力。希望这能为您提供有价值的见解,并帮助您应对这一主题快速发展的文献和炒作。
2024 年,LLM字段见证了越来越多的专业化。除了预训练和微调之外,我们还见证了从 RAG 到代码助手的专用应用兴起。我预计这一趋势将在 2025 年加速,对领域和应用特定优化的重视程度将更高(即“专业化”)。
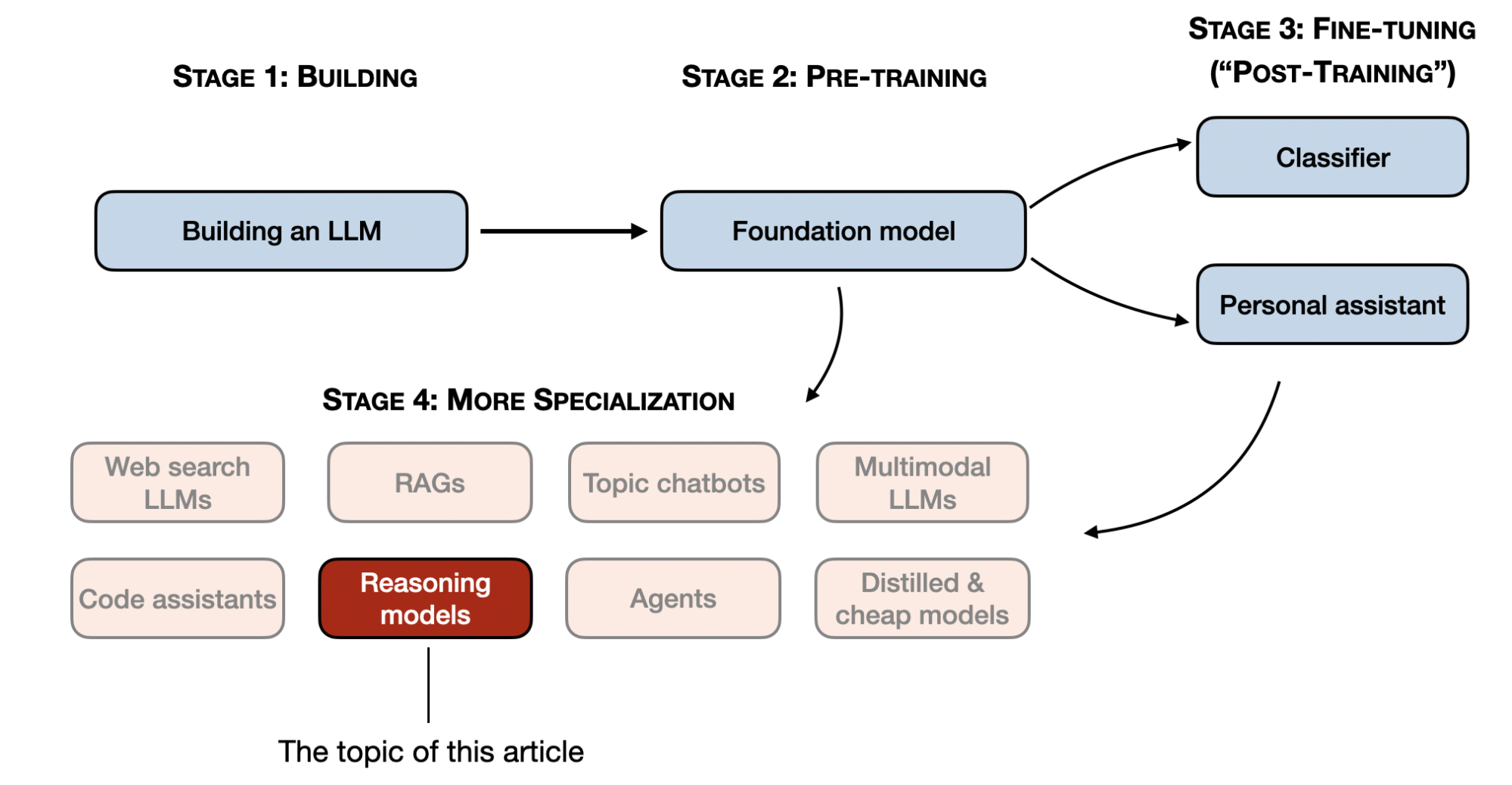
阶段 1-3 是开发 LLMs 的常见步骤。阶段 4 专门针对特定用例进行 LLMs。
推理模型的开发是这些专业化之一。这意味着我们改进LLMs以擅长通过中间步骤解决的最佳复杂任务,例如谜题、高级数学和编码挑战。然而,这种专业化并不取代其他LLM应用。因为将LLM转化为推理模型也引入了某些缺点,我将在稍后讨论。
目录

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











