








 该专栏为热销专栏榜 第68名
该专栏为热销专栏榜 第68名 超级会员免费看
超级会员免费看


大语言模型原理与应用实践:基于监督学习进行微调 Supervised Learning & Fine-Tuning
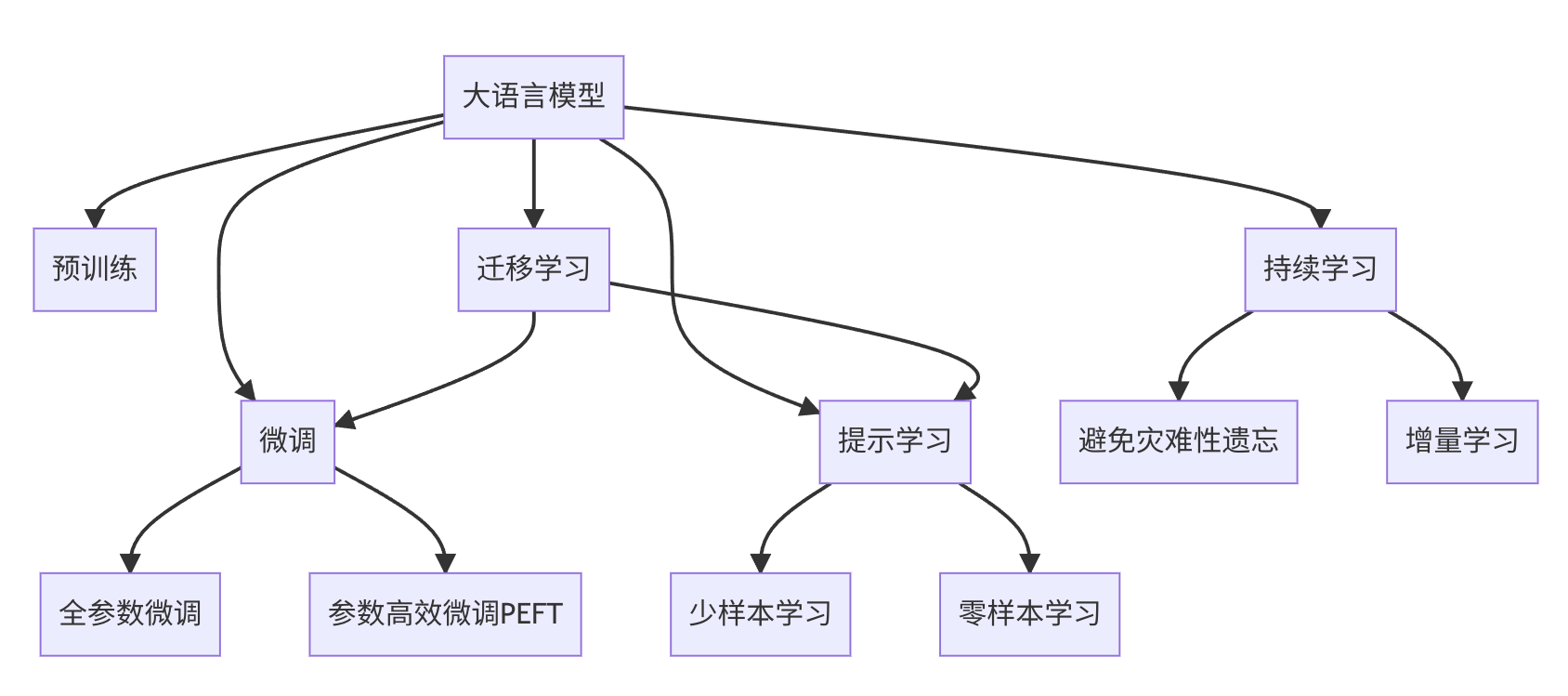
关键词:大语言模型,微调(Fine-tuning),迁移学习,监督学习,Transformer,BERT,预训练,下游任务,参数高效微调,自然语言处理(NLP)
文章目录
1. 背景介绍
1.1 问题的由来
近年来,随着深度学习技术的快速发展,大规模语言模型(Large Language Models, LLMs)在自然语言处理(Natural Language Processing, NLP)领域取得了巨大的突破。这些大语言模型通过在海量无标签文本数据上进行预训练,学习到了丰富的语言知识和常识,可以通过少量的有标签样本在下游任务上进行微调(Fine-Tuning),获得优异的性能。其中最具代表性的大模型包括OpenAI的GPT系列模型、Google的BERT、T5等。
然而,由于预训练语料的广泛性和泛化能力的不足,这些通用的大语言模型在特定领域应用时,效

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











