



讲到游戏开发,大家耳熟能详的游戏引擎想必有Unity3D的一席之地,而U3D开发手游,我们常会用到热更新技术,达到及时修复Bug与即时新增功能
说到热更新,目前最常见的做法就是在C#内置一个虚拟机,来解释执行不同的语言(如Lua、TypeScript、C#和IL)
最常用的热更方案,目前还是使用Lua进行热更新,所有的游戏代码都写到Lua文件内,再将其打入AB包进行热更。
本篇文章,作者强力推荐C#热更新方案:ILRuntime,该方案可以解释执行C#代码生成的解决方案(DLL)内的IL指令,以达到热更新的需求,非常好用,再也不需要去写Lua了,C#就可以热更了。
话题
那么讲到热更新,大家都会面临一个问题:我的热更新文件是否安全,热更代码丢热更资源里面,是否会造成泄露?
在这个问题上,就仁者见仁智者见智了,有的人可能会说:
“就我这代码,泄露就泄露吧,没必要做什么防护”
有的人可能说:
“魔高一尺道高一丈,没有绝对的安全的,所以没必要进行保护”
那么本篇文章的主要思想,还是
尽全力的提高热更源码泄露的门槛,让人破解起来难度更大
,如果你觉得代码安全毫无意义,请忽略本文章。
前言
作者在GitHub(全球最大同行社交平台),有一个U3D的热更框架,热更新部分的实现就是基于ILRuntime,所以也曾经进行过一定程度的热更代码保护。
想看看的可以参考:
JEngine知乎文章
之前的方案呢,很简单,可以参考下图:
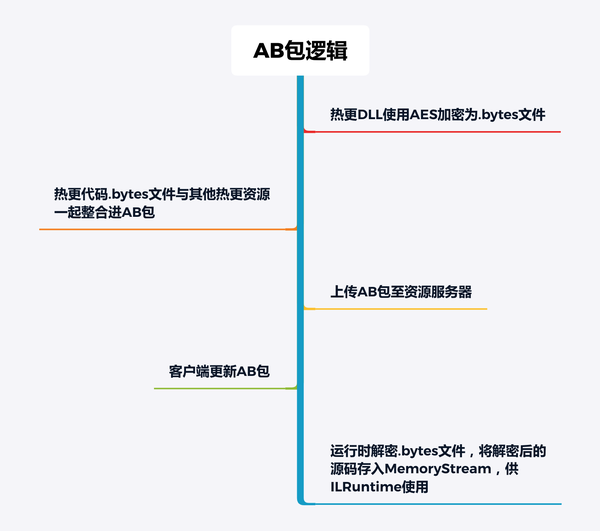
AB热更流程示意图
那么这个逻辑,看似很完善,哪怕AB包被盗了,也解不出加密后的源码(不懂AES的可以自行百度,别说什么穷举法来破解,笑死我,对你没好处)
但是,这个做法还是有遗漏的地方:解密后的源码,明文存入MemoryStream,会导致源码进MemoryStream的内存缓冲区,以至于可以被抓内存来获取源码!!
沟通
意识到了这个问题,作者我联系了ILRuntime的作者,蓝大。
我和蓝大进行了一段时间的沟通,最后得到了解决方案:
ILRuntime获取热更DLL中的指令,会用到Mono.Cecil的 ModuleDefinition.ReadModule方法,而这个方法传的参数,就是之前我的那个MemoryStream。
Mono.Cecil会调用该Stream的
Read
、
ReadByte
和
Seek
方法,来分块读取这个包含了热更代码的文件,所以只需要针对这3个方法,做特殊处理即可。
理论上,我只需要写一个
继承Stream的派生类
,然后在
重载的Read和ReadByte
方法里,进行解密和返回操作即可,
Seek
这个方法暂时不用管,后面会进行解释。
开发
初步构思后,我便自信满满的开始了开发:
我写了个Stream的派生类,然后重载了全部需要重载的方法,其中除了
Read、ReadByte、Seek和Position
之外,我全返回了抛出不支持异常
这里讲一下这4个是干嘛的:
-
Read :读取一段区域的字节,参数是byte[] buffer, int offset, int count,分别是需要Stream把截取的字节段落写入的缓冲区,截取开始的位置和截取的长度, 读完后Position要+=count
-
ReadByte :读取当前位置(Position)的字节,返回这个字节
-
Seek: 偏移Position,这样可以读不同区域的数据,参数是long offset, SeekOrigin loc,显而易见,参数分别是偏移的位置,和偏移方式,SeekOrgin有3个选项:Begin,Current和End,分别是从头开始第offset位,当前开始往后offset位,和从末尾开始往前offset位(这种情况offset是负数)
-
Position :Stream当前读到的位置,用于定位和继续往后读之类的
那么我只需要保证
Seek
和
Position正常
,就可以正常的Read和ReadByte了。
与此同时,我的JStream还需要一个缓存区,用于存byte[]的数据(叫做buffer,可以随意命名),当然,这里面肯定是要进加密数据的,不然会被抓内存。
紧接着,就是分块解密了。
因为我之前是用的AES加密,而
AES是每16块字节进行加密的
,所以我将数据按16个16个去处理,解密,再返回就好。
那么有了思路,就好操作了,很快我就把我需要写的方法开了个头:
private
byte
[
]
GetBytesAt
(
int
start
,
int
length
)
这其中,
start是截取开始的部分,length是截取长度
在这里我们
假设
,我们要从
截取第10位开始截取,截取8位,到第18位
。
按
AES加密是16块分块加密
来说,我们需要包含第10位的这一块,以及包含18位的这一块,
10小于16,所以
10在第一块加密区块内
18大于16小于32,所以
18在第二块加密区块内
我们需要
从加密密文的第1位开始,一直读到第32位
,也就包含了全部需要的密文
紧接着,我们对其进行解密
我这边加密的时候,采用的
PKCS7做Padding对加密的密文
进行填充,但我们
分块解密的时候,是没Padding的
,所以我们
需要以Padding.None去分块解密
。
如果小伙伴还不知道什么是AES的Padding,可以自行百度,也可以忽略继续往下读。
那么我们现在获得了,一个32位的解密明文。
这个时候呢,我们又要从第10位开始读这个解密明文,读到第18位,然后存到新的byte[]内,进行返回,具体实现如下:
/// <summary>
/// 获取特定位置的真实数据(包含解密过程)
/// </summary>
/// <param name="start"></param>
/// <param name="length"></param>
/// <returns></returns>
private
byte
[
]
GetBytesAt
(
int
start
,
int
length
)
{
int
remainder
=
start
%
16
;
// 余数
int
offset
=
start
-
remainder
;
// 偏移值,截取开始的地方,比如 67 变 64
int
count
=
length
+
(
16
-
length
%
16
)
;
//获得需要切割的数组的长度,比如 77 变 80,77+ (16- 77/16的余数) = 77 + (16-13) = 77 + 3 = 80
var
result
=
new
byte
[
length
]
;
//返回值,长度为length
// Log.Print($"start:{start}, length:{length}, remainder:{remainder}");
//现在需要将buffer切割,从offset开始,到count为止
var
encryptedData
=
new
byte
[
count
]
;
//创建加密数据数组
Buffer
.
BlockCopy
(
_buffer
,
offset
,
encryptedData
,
0
,
count
)
;
//从原始数据里分割出来
// Log.Print("获取到的密文:"+string.Join(", ", encryptedData));
//给encryptedData解密
var
decrypt
=
CryptoHelper
.
AesDecryptWithNoPadding
(
encryptedData
,
_key
)
;
//截取decrypt,从remainder开始,到length为止,比如余数是3,那么从3-1的元素开始
offset
=
remainder
;
// Log.Print($"copy from offset:{offset}, result.length:{length}, decrypt.length:{decrypt.Length}");
//这里有个问题,比如decrypt有16字节,而result是12字节,offset是8,那么12+8 > 16,就会出现错误
//所以这里要改一下
var
total
=
offset
+
length
;
var
dLength
=
decrypt
.
Length
;
if
(
total
>
dLength
)
{
Array
.
Resize
(
ref
decrypt
,
total
)
;
}
Buffer
.
BlockCopy
(
decrypt
,
offset
,
result
,
0
,
length
)
;
// Log.Print("解密结果:"+string.Join(", ", decrypt));
#
if
UNITY_EDITOR
EncryptedCounts
++
;
#
endif
return
result
;
}
注意,上面的代码直接抄会有问题,因为你没有很多参数,你需要实现自己的Stream才行,当然,最底部会附带完整代码。
通过这个代码,很明显,
技术点在于求Start除以16的余数,然后与Start相减得到需要开始读加密区块的地方
,
然后需要读的长度为传入的长度参数的下一个可以被16整除的数字
。
紧接着,就是上面所阐述的了,进行
NoPadding的解密
,就可以取出了。
这里有一个小坑,就是在复制数据到数组的时候,如果数据长度不够,会导致报错,所以这里有个小判断。
好,现在分块解密
“算是”
初步解决,接下来再修改一下Read和ReadByte就可以开始测试了
public
override
int
Read
(
byte
[
]
buffer
,
int
offset
,
int
count
)
{
if
(
buffer
==
null
)
throw
new
ArgumentNullException
(
nameof
(
buffer
)
,
"buffer == null"
)
;
if
(
offset
<
0
)
throw
new
ArgumentOutOfRangeException
(
nameof
(
offset
)
,
"offset < 0"
)
;
if
(
count
<
0
)
throw
new
ArgumentOutOfRangeException
(
nameof
(
count
)
,
"count < 0"
)
;
if
(
buffer
.
Length
-
offset
<
count
)
throw
new
ArgumentException
(
"invalid buffer length"
)
;
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
int
n
=
_length
-
_position
;
if
(
n
>
count
)
n
=
count
;
if
(
n
<=
0
)
return
0
;
/*
MemoryStream源码是这样的,我也不知道为什么要把8个长度的单独拉出来
if (n <= 8)
{
int byteCount = n;
while (--byteCount >= 0)
buffer[offset + byteCount] = _buffer[_position + byteCount];
}
else
Buffer.BlockCopy(_buffer, _position, buffer, offset, n);
*/
/*
* JEngine的分块解密
* 理论上,aes是 每16字节为单位 加密
* 所以只需给buffer以16位单位切割即可
*/
if
(
_encrypted
)
{
try
{
Buffer
.
BlockCopy
(
GetBytesAt
(
_position
,
count
)
,
0
,
buffer
,
offset
,
n
)
;
//复制过去
//这个用来做log的,去掉注释就可以调试
//这边的result是缓存,把log给打出来,不然分配buffer后,如果出错了没办法还原解密结果
// var result = new byte[buffer.Length];
// Buffer.BlockCopy(buffer, 0, result, 0, buffer.Length);
// Buffer.BlockCopy(src, 0, result, offset, n);
// Log.Print("解密结果:" + string.Join(", ", result));
// Buffer.BlockCopy(result, 0, buffer, offset, n);
}
catch
(
Exception
ex
)
{
Log
.
PrintError
(
ex
)
;
throw
;
}
}
else
{
//没加密的直接读就好
Buffer
.
BlockCopy
(
_buffer
,
_position
,
buffer
,
offset
,
n
)
;
//对比无加密的:加密的字节,用于测试(可能会有不一样的地方)
// Log.Print("原文结果:" + string.Join(", ", buffer));
// var src = GetBytesAt(_position, n);
// var result = new byte[buffer.Length];
// Buffer.BlockCopy(buffer, 0, result, 0, buffer.Length);
// Buffer.BlockCopy(src, 0, result, offset, n);
// Log.Print("解密结果:" + string.Join(", ", result));
// var equal = CompareArray(buffer,result);
// var en = CryptoHelper.AesEncryptWithNoPadding(buffer, _key);
// Log.Print("原文加密结果:" + string.Join(", ", en));
// Log.Print($"pos: {_position}, count: {count}, decrypt equals original: {equal}");
// Log.Print($"=======================");
}
_position
+=
n
;
return
n
;
}
public
override
int
ReadByte
(
)
{
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
if
(
_position
>=
_length
)
return
-
1
;
return
_encrypted
?
GetBytesAt
(
_position
++
,
1
)
[
0
]
:
_buffer
[
_position
++
]
;
}
这段代码注释很足,没必要解释了
调试
我自信满满的开始进行测试,结果布满棘刺
写了丰富的Log,然后我自己的JStream在那边分块解密着热更代码。
结果读到
第四百多位,它就出错了
,于是我又拿了个
MemoryStream
进行对比
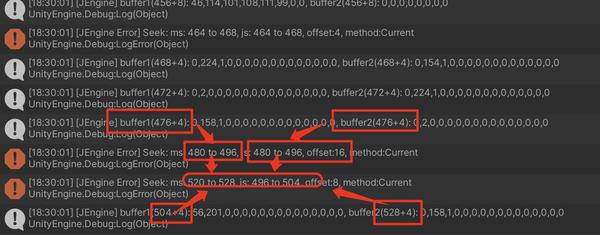
错误一
对比后发现,莫名其妙的,也
没Seek也没Read也没ReadByte
,
MemoryStream的Position比我自己实现
的,
多了十几二十位
,这还得了!
再到后面,更是离谱,多了
六万位
!!

错误二
最后为了省事,我下载了一份
MemoryStream的源码
,把它的
Position机制复制了过来
,这个坑总算解决了!
public
override
long
Position
{
get
{
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
return
_position
-
_origin
;
}
set
{
if
(
value
<
0
)
throw
new
ArgumentOutOfRangeException
(
nameof
(
value
)
,
"value < 0 is invalid"
)
;
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
if
(
value
>
MemStreamMaxLength
)
throw
new
ArgumentOutOfRangeException
(
nameof
(
value
)
,
"value > stream length is invalid"
)
;
_position
=
_origin
+
(
int
)
value
;
}
}
很难相信,
MemoryStream自己的Position机制,竟然还带了个origin参数
,这也就是导致我
自己写的Position不对的罪魁祸首
!
好,
这个问题解决了,新的问题又来了
。
读到第4万位,出现了我之前提到的,
复制数据到数组长度不够
的坑。
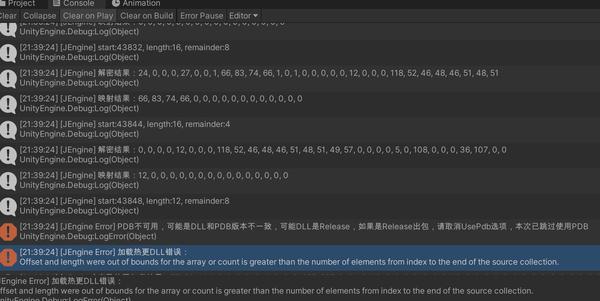
错误三
还好,最后发现并修复了。
这还不错,
好歹读了上万位了哈哈。
然而,我
还是太天真
了,
新的问题又来了
。
读到
第10万
位,
Mono.Cecil那边出现了空错误,这不科学啊,我解密的代码没问题啊!

错误四
然后我就开始了漫长的排查,
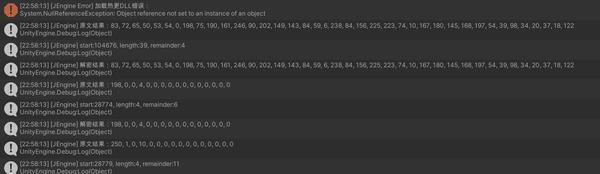
错误五

错误六
通过对比,我发现,
这俩玩意儿没区别啊,怎么就空了呢?
于是,我写了个代码,对比每一次读取的字节是否一样:
/// <summary>
/// 数组比较是否相等
/// </summary>
/// <param name="bt1">数组1</param>
/// <param name="bt2">数组2</param>
/// <returns>true:相等,false:不相等</returns>
public
bool
CompareArray
(
byte
[
]
bt1
,
byte
[
]
bt2
)
{
var
len1
=
bt1
.
Length
;
var
len2
=
bt2
.
Length
;
if
(
len1
!=
len2
)
{
return
false
;
}
for
(
var
i
=
0
;
i
<
len1
;
i
++
)
{
if
(
bt1
[
i
]
!=
bt2
[
i
]
)
{
// Log.PrintError($"original: {string.Join(",",bt1)}, decrypt: {string.Join(",",bt2)}\n" +
// $"{bt1[i]} != {bt2[i]}");
return
false
;
}
}
return
true
;
}
然后在读取时:
//对比无加密的:加密的字节,用于测试(可能会有不一样的地方)
Log
.
Print
(
"原文结果:"
+
string
.
Join
(
", "
,
buffer
)
)
;
var
src
=
GetBytesAt
(
_position
,
n
)
;
var
result
=
new
byte
[
buffer
.
Length
]
;
Buffer
.
BlockCopy
(
buffer
,
0
,
result
,
0
,
buffer
.
Length
)
;
Buffer
.
BlockCopy
(
src
,
0
,
result
,
offset
,
n
)
;
Log
.
Print
(
"解密结果:"
+
string
.
Join
(
", "
,
result
)
)
;
var
equal
=
CompareArray
(
buffer
,
result
)
;
var
en
=
CryptoHelper
.
AesEncryptWithNoPadding
(
buffer
,
_key
)
;
Log
.
Print
(
"原文加密结果:"
+
string
.
Join
(
", "
,
en
)
)
;
Log
.
Print
(
$"pos:
{
_position
}
, count:
{
count
}
, decrypt equals original:
{
equal
}
"
)
;
Log
.
Print
(
$"======================="
)
;
通过对比,
我发现,每次返回16位的buffer,解密的对比未加密的数据,总会多几个0,诡异的是读取也没报错,到后来才爆发空错误
例如:
本应返回:[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16],解密后返回了[1,2,3,4,5,6,7,8,9,10,0,0,0,0,0,0],后面的东西没了!
然后我进行了
大量的StackOverFlow和谷歌
,发现,这还是
AES解密的锅
,这玩意儿
解密的是会丢失最后几位!
解决方法就是,
扩大解密范围!
还记的之前,
是取截取末尾之后的那个可以整除16的位数吗,现在我们再+16位,扩大范围!
/// <summary>
/// 获取特定位置的真实数据(包含解密过程)
/// </summary>
/// <param name="start"></param>
/// <param name="length"></param>
/// <returns></returns>
private
byte
[
]
GetBytesAt
(
int
start
,
int
length
)
{
int
remainder
=
start
%
16
;
// 余数
int
offset
=
start
-
remainder
;
// 偏移值,截取开始的地方,比如 67 变 64
int
count
=
length
+
(
32
-
length
%
16
)
;
//获得需要切割的数组的长度,比如 77 变 96(80+16),77+ (32- 77/16的余数) = 77 + (32-13) = 77 + 19 = 96,多16位确保不丢东西
var
result
=
new
byte
[
length
]
;
//返回值,长度为length
// Log.Print($"start:{start}, length:{length}, remainder:{remainder}");
//现在需要将buffer切割,从offset开始,到count为止
var
encryptedData
=
new
byte
[
count
]
;
//创建加密数据数组
Buffer
.
BlockCopy
(
_buffer
,
offset
,
encryptedData
,
0
,
count
)
;
//从原始数据里分割出来
// Log.Print("获取到的密文:"+string.Join(", ", encryptedData));
//给encryptedData解密
var
decrypt
=
CryptoHelper
.
AesDecryptWithNoPadding
(
encryptedData
,
_key
)
;
//截取decrypt,从remainder开始,到length为止,比如余数是3,那么从3-1的元素开始
offset
=
remainder
;
// Log.Print($"copy from offset:{offset}, result.length:{length}, decrypt.length:{decrypt.Length}");
//这里有个问题,比如decrypt有16字节,而result是12字节,offset是8,那么12+8 > 16,就会出现错误
//所以这里要改一下
var
total
=
offset
+
length
;
var
dLength
=
decrypt
.
Length
;
if
(
total
>
dLength
)
{
Array
.
Resize
(
ref
decrypt
,
total
)
;
}
Buffer
.
BlockCopy
(
decrypt
,
offset
,
result
,
0
,
length
)
;
// Log.Print("解密结果:"+string.Join(", ", decrypt));
#
if
UNITY_EDITOR
EncryptedCounts
++
;
#
endif
return
result
;
}
16 - length % 16 变为了 32 - length % 16
再次运行,终于成功!
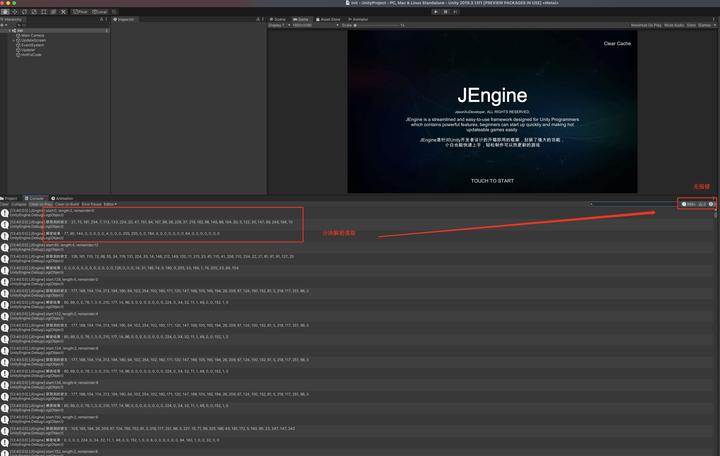
终于成功
然后测了下
耗时,很奈斯!
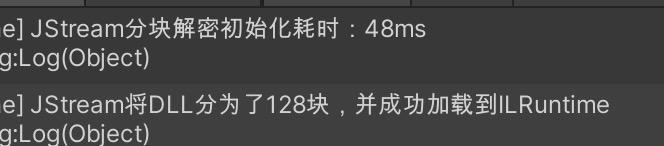
分块解密初始化热更DLL耗时
才
48ms
,毫无问题,同时
返回了128块代码
块给ILRuntime
总结
这个分块出来的代码,是明文,但我和ILRuntime作者确定了,
ILRuntime不会缓存
,但我不能保证Mono.Cecil是否会缓存。
然而,你的
代码被切成几万份
,那不得
内存抓个几万次
?所以啊,没啥毛病!
性能
这块,
多几ms
而已,
无GC
,没啥毛病,
不会卡顿
!
然后,为什么我要做这个,主要总有人说我是缝合怪,那我不得证明一下我自己吗,当然,也欢迎各位大佬指出本文存在的任何错误,我会虚心接受的!
结尾
注,Log.Print是Debug.Log,Log.PrintError是Debug.LogError,Log.PrintWarning是Debug.LogWarning
以下是JStream源码
:
using
System
;
using
System
.
IO
;
namespace
JEngine
.
Core
{
public
class
JStream
:
Stream
{
private
byte
[
]
_buffer
;
// Either allocated internally or externally.
private
readonly
int
_origin
;
// For user-provided arrays, start at this origin
private
int
_position
;
// read/write head.
private
int
_length
;
// Number of bytes within the memory stream
private
int
_capacity
;
// length of usable portion of buffer for stream
private
string
_key
;
//解密密码
private
string
_defaultKey
=
"hello_JEngine_!_"
;
#
if
UNITY_EDITOR
public
int
EncryptedCounts
{
get
;
set
;
}
#
endif
// Note that _capacity == _buffer.Length for non-user-provided byte[]'s
private
bool
_encrypted
=
true
;
//是否aes加密了
private
bool
_expandable
;
// User-provided buffers aren't expandable.
private
readonly
bool
_exposable
;
// Whether the array can be returned to the user.
private
bool
_isOpen
;
// Is this stream open or closed?
private
readonly
uint
maxLength
=
2147483648
;
private
const
int
MemStreamMaxLength
=
Int32
.
MaxValue
;
public
bool
Encrypted
{
get
=>
_encrypted
;
set
=>
_encrypted
=
value
;
}
public
JStream
(
byte
[
]
buffer
,
string
key
)
:
this
(
buffer
,
key
,
true
)
{
}
public
JStream
(
byte
[
]
buffer
,
string
key
,
bool
writable
)
{
_buffer
=
buffer
??
throw
new
ArgumentNullException
(
nameof
(
buffer
)
,
"buffer == null"
)
;
_length
=
_capacity
=
buffer
.
Length
;
_exposable
=
false
;
_origin
=
0
;
_isOpen
=
true
;
_key
=
key
;
if
(
_key
.
Length
<
16
)
{
_key
=
Init
.
Instance
.
Key
.
Length
<
16
?
_defaultKey
:
Init
.
Instance
.
Key
;
}
}
public
JStream
(
byte
[
]
buffer
,
string
key
,
int
index
,
int
count
)
:
this
(
buffer
,
key
,
index
,
count
,
false
)
{
}
public
JStream
(
byte
[
]
buffer
,
string
key
,
int
index
,
int
count
,
bool
publiclyVisible
)
{
if
(
buffer
==
null
)
throw
new
ArgumentNullException
(
nameof
(
buffer
)
,
"buffer == null"
)
;
if
(
index
<
0
)
throw
new
ArgumentOutOfRangeException
(
nameof
(
index
)
,
"index < 0"
)
;
if
(
count
<
0
)
throw
new
ArgumentOutOfRangeException
(
nameof
(
count
)
,
"count < 0"
)
;
if
(
buffer
.
Length
-
index
<
count
)
throw
new
ArgumentException
(
"invalid length of buffer"
)
;
_buffer
=
buffer
;
_origin
=
_position
=
index
;
_length
=
_capacity
=
index
+
count
;
_exposable
=
publiclyVisible
;
// Can TryGetBuffer/GetBuffer return the array?
_expandable
=
false
;
_isOpen
=
true
;
_key
=
key
;
if
(
_key
.
Length
<
16
)
{
_key
=
Init
.
Instance
.
Key
.
Length
<
16
?
_defaultKey
:
Init
.
Instance
.
Key
;
}
}
public
override
bool
CanRead
=>
_isOpen
;
public
override
bool
CanSeek
=>
_isOpen
;
public
override
bool
CanWrite
=>
false
;
protected
override
void
Dispose
(
bool
disposing
)
{
try
{
if
(
disposing
)
{
_isOpen
=
false
;
_expandable
=
false
;
// Don't set buffer to null - allow TryGetBuffer, GetBuffer & ToArray to work.
}
}
finally
{
// Call base.Close() to cleanup async IO resources
base
.
Dispose
(
disposing
)
;
}
}
// returns a bool saying whether we allocated a new array.
private
bool
EnsureCapacity
(
int
value
)
{
// Check for overflow
if
(
value
<
0
)
throw
new
IOException
(
"Stream too long, value < capacity of stream is invalid"
)
;
if
(
value
>
_capacity
)
{
int
newCapacity
=
value
;
if
(
newCapacity
<
256
)
newCapacity
=
256
;
// We are ok with this overflowing since the next statement will deal
// with the cases where _capacity*2 overflows.
if
(
newCapacity
<
_capacity
*
2
)
newCapacity
=
_capacity
*
2
;
// We want to expand the array up to Array.MaxArrayLengthOneDimensional
// And we want to give the user the value that they asked for
if
(
(
uint
)
(
_capacity
*
2
)
>
maxLength
)
newCapacity
=
value
<
maxLength
?
value
:
(
int
)
(
maxLength
/
2
)
;
Capacity
=
newCapacity
;
return
true
;
}
return
false
;
}
public
override
void
Flush
(
)
{
}
public
virtual
byte
[
]
GetBuffer
(
)
{
if
(
!
_exposable
)
throw
new
UnauthorizedAccessException
(
"UnauthorizedAccess to get member buffer"
)
;
return
_buffer
;
}
public
virtual
bool
TryGetBuffer
(
out
ArraySegment
<
byte
>
buffer
)
{
if
(
!
_exposable
)
{
buffer
=
default
(
ArraySegment
<
byte
>
)
;
return
false
;
}
buffer
=
new
ArraySegment
<
byte
>
(
_buffer
,
offset
:
_origin
,
count
:
(
_length
-
_origin
)
)
;
return
true
;
}
// -------------- PERF: Internal functions for fast direct access of JStream buffer (cf. BinaryReader for usage) ---------------
// PERF: Internal sibling of GetBuffer, always returns a buffer (cf. GetBuffer())
internal
byte
[
]
InternalGetBuffer
(
)
{
return
_buffer
;
}
// PERF: Get origin and length - used in ResourceWriter.
internal
void
InternalGetOriginAndLength
(
out
int
origin
,
out
int
length
)
{
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
origin
=
_origin
;
length
=
_length
;
}
// PERF: True cursor position, we don't need _origin for direct access
internal
int
InternalGetPosition
(
)
{
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
return
_position
;
}
// PERF: Takes out Int32 as fast as possible
internal
int
InternalReadInt32
(
)
{
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
int
pos
=
(
_position
+=
4
)
;
// use temp to avoid ----
if
(
pos
>
_length
)
{
_position
=
_length
;
Log
.
PrintError
(
"end of file"
)
;
}
return
_buffer
[
pos
-
4
]
|
_buffer
[
pos
-
3
]
<<
8
|
_buffer
[
pos
-
2
]
<<
16
|
_buffer
[
pos
-
1
]
<<
24
;
}
// PERF: Get actual length of bytes available for read; do sanity checks; shift position - i.e. everything except actual copying bytes
internal
int
InternalEmulateRead
(
int
count
)
{
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
int
n
=
_length
-
_position
;
if
(
n
>
count
)
n
=
count
;
if
(
n
<
0
)
n
=
0
;
_position
+=
n
;
return
n
;
}
// Gets & sets the capacity (number of bytes allocated) for this stream.
// The capacity cannot be set to a value less than the current length
// of the stream.
//
public
virtual
int
Capacity
{
get
{
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
return
_capacity
-
_origin
;
}
set
{
// Only update the capacity if the MS is expandable and the value is different than the current capacity.
// Special behavior if the MS isn't expandable: we don't throw if value is the same as the current capacity
if
(
value
<
Length
)
throw
new
ArgumentOutOfRangeException
(
nameof
(
value
)
,
"value < capcacity is invalid"
)
;
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
if
(
!
_expandable
&&
(
value
!=
Capacity
)
)
Log
.
PrintError
(
"JStream is not expandable"
)
;
// JStream has this invariant: _origin > 0 => !expandable (see ctors)
if
(
_expandable
&&
value
!=
_capacity
)
{
if
(
value
>
0
)
{
byte
[
]
newBuffer
=
new
byte
[
value
]
;
if
(
_length
>
0
)
Buffer
.
BlockCopy
(
_buffer
,
0
,
newBuffer
,
0
,
_length
)
;
_buffer
=
newBuffer
;
}
else
{
_buffer
=
null
;
}
_capacity
=
value
;
}
}
}
public
override
long
Length
{
get
{
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
return
_length
-
_origin
;
}
}
public
override
long
Position
{
get
{
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
return
_position
-
_origin
;
}
set
{
if
(
value
<
0
)
throw
new
ArgumentOutOfRangeException
(
nameof
(
value
)
,
"value < 0 is invalid"
)
;
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
if
(
value
>
MemStreamMaxLength
)
throw
new
ArgumentOutOfRangeException
(
nameof
(
value
)
,
"value > stream length is invalid"
)
;
_position
=
_origin
+
(
int
)
value
;
}
}
public
override
int
Read
(
byte
[
]
buffer
,
int
offset
,
int
count
)
{
if
(
buffer
==
null
)
throw
new
ArgumentNullException
(
nameof
(
buffer
)
,
"buffer == null"
)
;
if
(
offset
<
0
)
throw
new
ArgumentOutOfRangeException
(
nameof
(
offset
)
,
"offset < 0"
)
;
if
(
count
<
0
)
throw
new
ArgumentOutOfRangeException
(
nameof
(
count
)
,
"count < 0"
)
;
if
(
buffer
.
Length
-
offset
<
count
)
throw
new
ArgumentException
(
"invalid buffer length"
)
;
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
int
n
=
_length
-
_position
;
if
(
n
>
count
)
n
=
count
;
if
(
n
<=
0
)
return
0
;
/*
MemoryStream源码是这样的,我也不知道为什么要把8个长度的单独拉出来
if (n <= 8)
{
int byteCount = n;
while (--byteCount >= 0)
buffer[offset + byteCount] = _buffer[_position + byteCount];
}
else
Buffer.BlockCopy(_buffer, _position, buffer, offset, n);
*/
/*
* JEngine的分块解密
* 理论上,aes是 每16字节为单位 加密
* 所以只需给buffer以16位单位切割即可
*/
if
(
_encrypted
)
{
try
{
Buffer
.
BlockCopy
(
GetBytesAt
(
_position
,
count
)
,
0
,
buffer
,
offset
,
n
)
;
//复制过去
//这个用来做log的,去掉注释就可以调试
//这边的result是缓存,把log给打出来,不然分配buffer后,如果出错了没办法还原解密结果
// var result = new byte[buffer.Length];
// Buffer.BlockCopy(buffer, 0, result, 0, buffer.Length);
// Buffer.BlockCopy(src, 0, result, offset, n);
// Log.Print("解密结果:" + string.Join(", ", result));
// Buffer.BlockCopy(result, 0, buffer, offset, n);
}
catch
(
Exception
ex
)
{
Log
.
PrintError
(
ex
)
;
throw
;
}
}
else
{
//没加密的直接读就好
Buffer
.
BlockCopy
(
_buffer
,
_position
,
buffer
,
offset
,
n
)
;
//对比无加密的:加密的字节,用于测试(可能会有不一样的地方)
// Log.Print("原文结果:" + string.Join(", ", buffer));
// var src = GetBytesAt(_position, n);
// var result = new byte[buffer.Length];
// Buffer.BlockCopy(buffer, 0, result, 0, buffer.Length);
// Buffer.BlockCopy(src, 0, result, offset, n);
// Log.Print("解密结果:" + string.Join(", ", result));
// var equal = CompareArray(buffer,result);
// var en = CryptoHelper.AesEncryptWithNoPadding(buffer, _key);
// Log.Print("原文加密结果:" + string.Join(", ", en));
// Log.Print($"pos: {_position}, count: {count}, decrypt equals original: {equal}");
// Log.Print($"=======================");
}
_position
+=
n
;
return
n
;
}
/// <summary>
/// 数组比较是否相等
/// </summary>
/// <param name="bt1">数组1</param>
/// <param name="bt2">数组2</param>
/// <returns>true:相等,false:不相等</returns>
public
bool
CompareArray
(
byte
[
]
bt1
,
byte
[
]
bt2
)
{
var
len1
=
bt1
.
Length
;
var
len2
=
bt2
.
Length
;
if
(
len1
!=
len2
)
{
return
false
;
}
for
(
var
i
=
0
;
i
<
len1
;
i
++
)
{
if
(
bt1
[
i
]
!=
bt2
[
i
]
)
{
// Log.PrintError($"original: {string.Join(",",bt1)}, decrypt: {string.Join(",",bt2)}\n" +
// $"{bt1[i]} != {bt2[i]}");
return
false
;
}
}
return
true
;
}
public
override
int
ReadByte
(
)
{
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
if
(
_position
>=
_length
)
return
-
1
;
return
_encrypted
?
GetBytesAt
(
_position
++
,
1
)
[
0
]
:
_buffer
[
_position
++
]
;
}
/// <summary>
/// 获取特定位置的真实数据(包含解密过程)
/// </summary>
/// <param name="start"></param>
/// <param name="length"></param>
/// <returns></returns>
private
byte
[
]
GetBytesAt
(
int
start
,
int
length
)
{
int
remainder
=
start
%
16
;
// 余数
int
offset
=
start
-
remainder
;
// 偏移值,截取开始的地方,比如 67 变 64
int
count
=
length
+
(
32
-
length
%
16
)
;
//获得需要切割的数组的长度,比如 77 变 96(80+16),77+ (32- 77/16的余数) = 77 + (32-13) = 77 + 19 = 96,多16位确保不丢东西
var
result
=
new
byte
[
length
]
;
//返回值,长度为length
// Log.Print($"start:{start}, length:{length}, remainder:{remainder}");
//现在需要将buffer切割,从offset开始,到count为止
var
encryptedData
=
new
byte
[
count
]
;
//创建加密数据数组
Buffer
.
BlockCopy
(
_buffer
,
offset
,
encryptedData
,
0
,
count
)
;
//从原始数据里分割出来
// Log.Print("获取到的密文:"+string.Join(", ", encryptedData));
//给encryptedData解密
var
decrypt
=
CryptoHelper
.
AesDecryptWithNoPadding
(
encryptedData
,
_key
)
;
//截取decrypt,从remainder开始,到length为止,比如余数是3,那么从3-1的元素开始
offset
=
remainder
;
// Log.Print($"copy from offset:{offset}, result.length:{length}, decrypt.length:{decrypt.Length}");
//这里有个问题,比如decrypt有16字节,而result是12字节,offset是8,那么12+8 > 16,就会出现错误
//所以这里要改一下
var
total
=
offset
+
length
;
var
dLength
=
decrypt
.
Length
;
if
(
total
>
dLength
)
{
Array
.
Resize
(
ref
decrypt
,
total
)
;
}
Buffer
.
BlockCopy
(
decrypt
,
offset
,
result
,
0
,
length
)
;
// Log.Print("解密结果:"+string.Join(", ", decrypt));
#
if
UNITY_EDITOR
EncryptedCounts
++
;
#
endif
return
result
;
}
public
override
long
Seek
(
long
offset
,
SeekOrigin
loc
)
{
if
(
!
_isOpen
)
Log
.
PrintError
(
"stream is closed"
)
;
if
(
offset
>
MemStreamMaxLength
)
throw
new
ArgumentOutOfRangeException
(
nameof
(
offset
)
,
"offset > stream length is invalid"
)
;
switch
(
loc
)
{
case
SeekOrigin
.
Begin
:
{
int
tempPosition
=
unchecked
(
_origin
+
(
int
)
offset
)
;
if
(
offset
<
0
||
tempPosition
<
_origin
)
throw
new
IOException
(
"offset < 0 from the beginning of stream is invalid"
)
;
_position
=
tempPosition
;
break
;
}
case
SeekOrigin
.
Current
:
{
int
tempPosition
=
unchecked
(
_position
+
(
int
)
offset
)
;
if
(
unchecked
(
_position
+
offset
)
<
_origin
||
tempPosition
<
_origin
)
throw
new
IOException
(
"offset is before the stream which is invalid"
)
;
_position
=
tempPosition
;
break
;
}
case
SeekOrigin
.
End
:
{
int
tempPosition
=
unchecked
(
_length
+
(
int
)
offset
)
;
if
(
unchecked
(
_length
+
offset
)
<
_origin
||
tempPosition
<
_origin
)
throw
new
IOException
(
"offset is before the stream which is invalid"
)
;
_position
=
tempPosition
;
break
;
}
default
:
throw
new
ArgumentException
(
"invalid seek origin"
)
;
}
return
_position
;
}
// Sets the length of the stream to a given value. The new
// value must be nonnegative and less than the space remaining in
// the array, Int32.MaxValue - origin
// Origin is 0 in all cases other than a JStream created on
// top of an existing array and a specific starting offset was passed
// into the JStream constructor. The upper bounds prevents any
// situations where a stream may be created on top of an array then
// the stream is made longer than the maximum possible length of the
// array (Int32.MaxValue).
//
public
override
void
SetLength
(
long
value
)
{
if
(
value
<
0
||
value
>
Int32
.
MaxValue
)
{
throw
new
ArgumentOutOfRangeException
(
nameof
(
value
)
,
"value does not fit the length (out of range)"
)
;
}
// Origin wasn't publicly exposed above.
if
(
value
>
(
Int32
.
MaxValue
-
_origin
)
)
{
throw
new
ArgumentOutOfRangeException
(
nameof
(
value
)
,
"value is too big"
)
;
}
int
newLength
=
_origin
+
(
int
)
value
;
bool
allocatedNewArray
=
EnsureCapacity
(
newLength
)
;
if
(
!
allocatedNewArray
&&
newLength
>
_length
)
Array
.
Clear
(
_buffer
,
_length
,
newLength
-
_length
)
;
_length
=
newLength
;
if
(
_position
>
newLength
)
_position
=
newLength
;
}
public
virtual
byte
[
]
ToArray
(
)
{
byte
[
]
copy
=
new
byte
[
_length
-
_origin
]
;
Buffer
.
BlockCopy
(
_buffer
,
_origin
,
copy
,
0
,
_length
-
_origin
)
;
return
copy
;
}
public
override
void
Write
(
byte
[
]
buffer
,
int
offset
,
int
count
)
{
throw
new
NotSupportedException
(
"JStream does not support write method!"
)
;
}
}
}
以下是CryptoHelper,加密类源码:
//
// CryptoHelper.cs
//
// Author:
// JasonXuDeveloper(傑) <jasonxudeveloper@gmail.com>
//
// Copyright (c) 2020 JEngine
//
// Permission is hereby granted, free of charge, to any person obtaining a copy
// of this software and associated documentation files (the "Software"), to deal
// in the Software without restriction, including without limitation the rights
// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
// copies of the Software, and to permit persons to whom the Software is
// furnished to do so, subject to the following conditions:
//
// The above copyright notice and this permission notice shall be included in
// all copies or substantial portions of the Software.
//
// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
// THE SOFTWARE.
using
System
;
using
System
.
Security
.
Cryptography
;
using
System
.
Text
;
using
UnityEngine
;
namespace
JEngine
.
Core
{
public
class
CryptoHelper
{
/// <summary>
/// 加密字符串
/// </summary>
/// <param name="value"></param>
/// <param name="key"></param>
/// <returns></returns>
/// <exception cref="Exception"></exception>
public
static
string
EncryptStr
(
string
value
,
string
key
)
{
try
{
Byte
[
]
keyArray
=
System
.
Text
.
Encoding
.
UTF8
.
GetBytes
(
key
)
;
Byte
[
]
toEncryptArray
=
System
.
Text
.
Encoding
.
UTF8
.
GetBytes
(
value
)
;
var
rijndael
=
new
System
.
Security
.
Cryptography
.
RijndaelManaged
(
)
;
rijndael
.
Key
=
keyArray
;
rijndael
.
Mode
=
System
.
Security
.
Cryptography
.
CipherMode
.
ECB
;
rijndael
.
Padding
=
System
.
Security
.
Cryptography
.
PaddingMode
.
PKCS7
;
System
.
Security
.
Cryptography
.
ICryptoTransform
cTransform
=
rijndael
.
CreateEncryptor
(
)
;
Byte
[
]
resultArray
=
cTransform
.
TransformFinalBlock
(
toEncryptArray
,
0
,
toEncryptArray
.
Length
)
;
return
Convert
.
ToBase64String
(
resultArray
,
0
,
resultArray
.
Length
)
;
}
catch
(
Exception
ex
)
{
Log
.
PrintError
(
ex
)
;
return
null
;
}
}
/// <summary>
/// 解密字符串
/// </summary>
/// <param name="value"></param>
/// <param name="key"></param>
/// <returns></returns>
/// <exception cref="Exception"></exception>
public
static
string
DecryptStr
(
string
value
,
string
key
)
{
try
{
Byte
[
]
keyArray
=
System
.
Text
.
Encoding
.
UTF8
.
GetBytes
(
key
)
;
Byte
[
]
toEncryptArray
=
Convert
.
FromBase64String
(
value
)
;
var
rijndael
=
new
System
.
Security
.
Cryptography
.
RijndaelManaged
(
)
;
rijndael
.
Key
=
keyArray
;
rijndael
.
Mode
=
System
.
Security
.
Cryptography
.
CipherMode
.
ECB
;
rijndael
.
Padding
=
System
.
Security
.
Cryptography
.
PaddingMode
.
PKCS7
;
System
.
Security
.
Cryptography
.
ICryptoTransform
cTransform
=
rijndael
.
CreateDecryptor
(
)
;
Byte
[
]
resultArray
=
cTransform
.
TransformFinalBlock
(
toEncryptArray
,
0
,
toEncryptArray
.
Length
)
;
return
System
.
Text
.
Encoding
.
UTF8
.
GetString
(
resultArray
)
;
}
catch
(
Exception
ex
)
{
Log
.
PrintError
(
ex
)
;
return
null
;
}
}
/// <summary>
/// AES 算法加密(ECB模式) 将明文加密
/// </summary>
/// <param name="toEncryptArray,">明文</param>
/// <param name="Key">密钥</param>
/// <returns>加密后base64编码的密文</returns>
public
static
byte
[
]
AesEncrypt
(
byte
[
]
toEncryptArray
,
string
Key
)
{
try
{
byte
[
]
keyArray
=
Encoding
.
UTF8
.
GetBytes
(
Key
)
;
RijndaelManaged
rDel
=
new
RijndaelManaged
(
)
;
rDel
.
Key
=
keyArray
;
rDel
.
Mode
=
CipherMode
.
ECB
;
rDel
.
Padding
=
PaddingMode
.
PKCS7
;
ICryptoTransform
cTransform
=
rDel
.
CreateEncryptor
(
)
;
byte
[
]
resultArray
=
cTransform
.
TransformFinalBlock
(
toEncryptArray
,
0
,
toEncryptArray
.
Length
)
;
return
resultArray
;
}
catch
(
Exception
ex
)
{
Log
.
PrintError
(
ex
)
;
return
null
;
}
}
/// <summary>
/// AES 算法解密(ECB模式) 将密文base64解码进行解密,返回明文
/// </summary>
/// <param name="toDecryptArray">密文</param>
/// <param name="Key">密钥</param>
/// <returns>明文</returns>
public
static
byte
[
]
AesDecrypt
(
byte
[
]
toDecryptArray
,
string
Key
)
{
try
{
byte
[
]
keyArray
=
Encoding
.
UTF8
.
GetBytes
(
Key
)
;
RijndaelManaged
rDel
=
new
RijndaelManaged
(
)
;
rDel
.
Key
=
keyArray
;
rDel
.
Mode
=
CipherMode
.
ECB
;
rDel
.
Padding
=
PaddingMode
.
PKCS7
;
ICryptoTransform
cTransform
=
rDel
.
CreateDecryptor
(
)
;
byte
[
]
resultArray
=
cTransform
.
TransformFinalBlock
(
toDecryptArray
,
0
,
toDecryptArray
.
Length
)
;
return
resultArray
;
}
catch
(
Exception
ex
)
{
Log
.
PrintError
(
ex
)
;
return
null
;
}
}
/// <summary>
/// AES 算法加密(ECB模式) 无padding填充,用于分块解密
/// </summary>
/// <param name="toEncryptArray,">明文</param>
/// <param name="Key">密钥</param>
/// <returns>加密后base64编码的密文</returns>
public
static
byte
[
]
AesEncryptWithNoPadding
(
byte
[
]
toEncryptArray
,
string
Key
)
{
try
{
byte
[
]
keyArray
=
Encoding
.
UTF8
.
GetBytes
(
Key
)
;
RijndaelManaged
rDel
=
new
RijndaelManaged
(
)
;
rDel
.
Key
=
keyArray
;
rDel
.
Mode
=
CipherMode
.
ECB
;
rDel
.
Padding
=
PaddingMode
.
None
;
ICryptoTransform
cTransform
=
rDel
.
CreateEncryptor
(
)
;
byte
[
]
resultArray
=
cTransform
.
TransformFinalBlock
(
toEncryptArray
,
0
,
toEncryptArray
.
Length
)
;
return
resultArray
;
}
catch
(
Exception
ex
)
{
Log
.
PrintError
(
ex
)
;
return
null
;
}
}
/// <summary>
/// AES 算法解密(ECB模式) 无padding填充,用于分块解密
/// </summary>
/// <param name="toDecryptArray">密文</param>
/// <param name="Key">密钥</param>
/// <returns>明文</returns>
public
static
byte
[
]
AesDecryptWithNoPadding
(
byte
[
]
toDecryptArray
,
string
Key
)
{
try
{
byte
[
]
keyArray
=
Encoding
.
UTF8
.
GetBytes
(
Key
)
;
RijndaelManaged
rDel
=
new
RijndaelManaged
(
)
;
rDel
.
Key
=
keyArray
;
rDel
.
Mode
=
CipherMode
.
ECB
;
rDel
.
Padding
=
PaddingMode
.
None
;
ICryptoTransform
cTransform
=
rDel
.
CreateDecryptor
(
)
;
byte
[
]
resultArray
=
cTransform
.
TransformFinalBlock
(
toDecryptArray
,
0
,
toDecryptArray
.
Length
)
;
return
resultArray
;
}
catch
(
Exception
ex
)
{
Log
.
PrintError
(
ex
)
;
return
null
;
}
}
}
}
感谢大家的阅读!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









