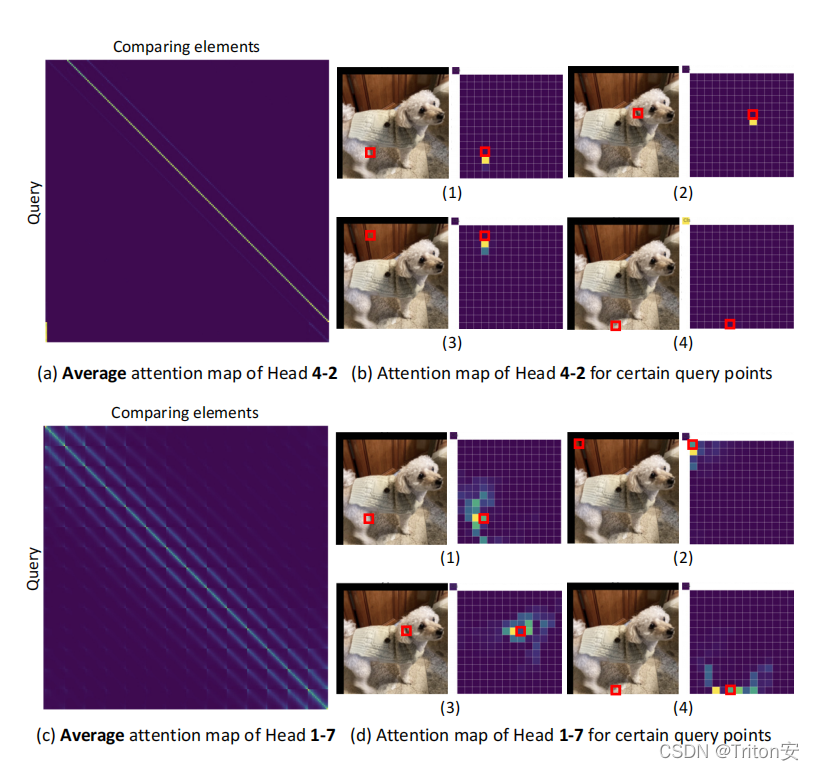
本文的核心思想:
1.在前层的attention map非常稀疏,可以用一个mask来减少计算量。(具体看文章如何实现mask)

2.attention可以分为三种
Relative position based attentionAbsolute position based attention
Content-based attention
 优化注意力机制:稀疏注意力与相对位置关注
优化注意力机制:稀疏注意力与相对位置关注
 本文探讨了在注意力机制中如何通过mask减少前层注意力图的计算量,提出了相对位置、绝对位置和内容为基础的三种注意力类型。通过引入mask策略,可以有效地优化模型性能并降低计算复杂度。
本文探讨了在注意力机制中如何通过mask减少前层注意力图的计算量,提出了相对位置、绝对位置和内容为基础的三种注意力类型。通过引入mask策略,可以有效地优化模型性能并降低计算复杂度。
Relative position based attentionAbsolute position based attention
Content-based attention
 1462
2890
2652
1231
1226
7869
1462
2890
2652
1231
1226
7869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言