







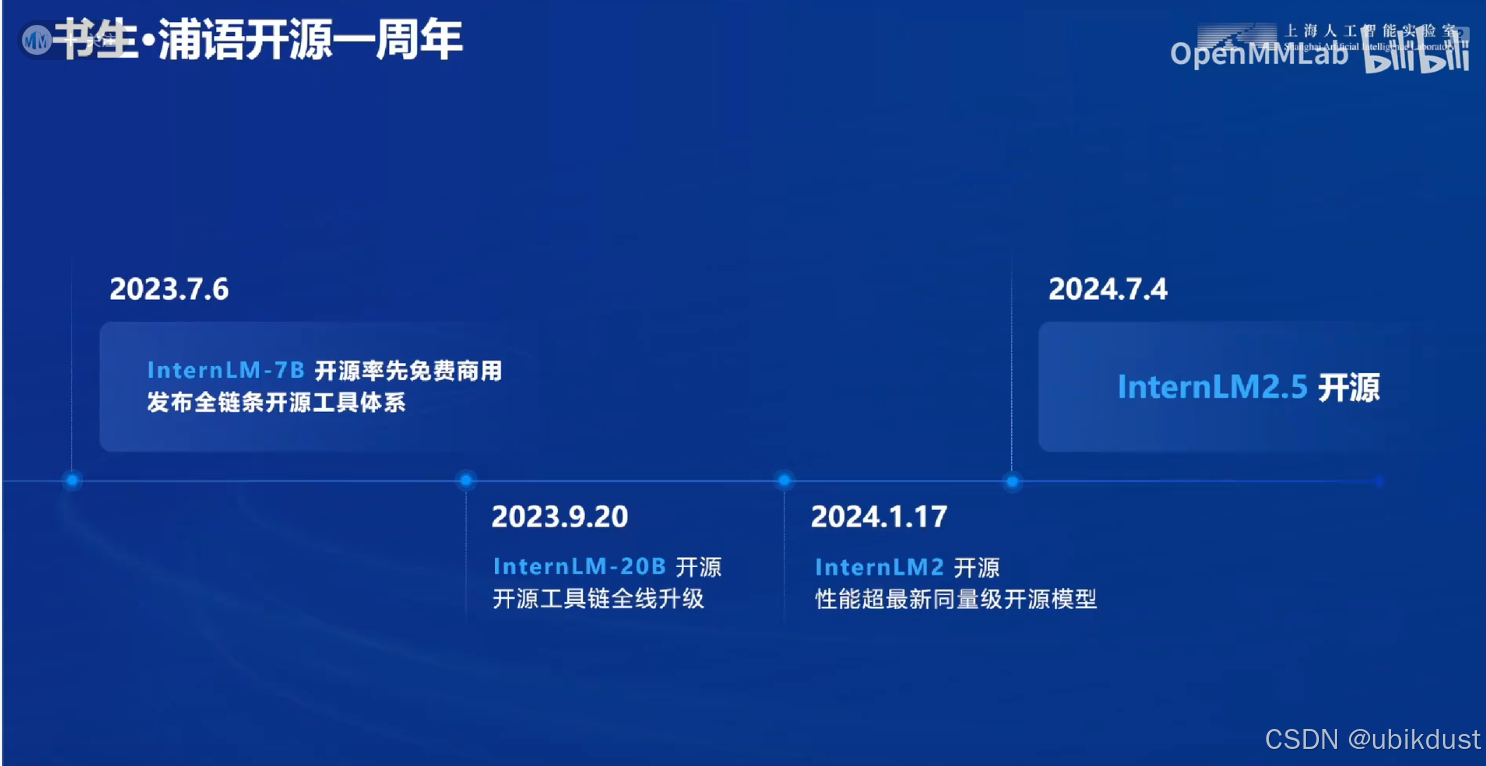
书生 浦语开源体系主要是以InternLM为核心的,但其体系远不止模型本身
可以看出书生浦语大模型持续优化,尤其是最新的Intern LM2.5-20B-chat的性能已经走在前列


书生浦语大模型为什么随着版本的迭代性能与表现能有那么大的提升呢,下面这个图反映了其数据驱动的特点

通过数据过滤、智能评估生成预训练数据,还有就是指令生成、辅助标记生成对齐数据,来实现模型的更新迭代,并且这是一个持续的过程。

书生浦语大模型不仅是在其原生模型的能力上,还在与调用的搜索引擎,解决问题的策略相关。</
书生 浦语开源体系主要是以InternLM为核心的,但其体系远不止模型本身
可以看出书生浦语大模型持续优化,尤其是最新的Intern LM2.5-20B-chat的性能已经走在前列
书生浦语大模型为什么随着版本的迭代性能与表现能有那么大的提升呢,下面这个图反映了其数据驱动的特点
通过数据过滤、智能评估生成预训练数据,还有就是指令生成、辅助标记生成对齐数据,来实现模型的更新迭代,并且这是一个持续的过程。
书生浦语大模型不仅是在其原生模型的能力上,还在与调用的搜索引擎,解决问题的策略相关。</

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























